Cross-modal Causal Relation Alignment for Video Question Grounding
前置论文
CausalVLR: A Toolbox and Benchmark for Visual-Linguistic Causal Reasoning
随着海量异构多模态数据的涌现(图像、视频、语言、音频、多传感器),大型语言模型已在多种视觉与语言任务中展现出优异性能。然而,当前 LLMs 严重依赖对广泛知识分布的拟合,往往捕捉到跨模态的虚假相关性,导致其难以学习反映多模态知识中本质因果关系的可靠思维链(COT),从而限制了模型的泛化能力和认知水平。值得庆幸的是,因果推断为解决这一问题提供了新方向——其通过构建鲁棒的表征和模型学习能力,有望帮助开发更可靠、更具认知能力的跨模态模型。
视觉语言推理旨在理解视觉和语言内容,同时执行各种推理任务,如视觉问题回答(VQA)、视觉对话、图像/视频caption、医学报告生成。然而,到目前为止,还没有综合的开源框架可用于因果关系感知的视觉语言推理。为了提供一个高质量的工具箱和一个统一的基准,本文开发了CausalVLR:一个基于pytorch的开源工具箱和基准,专门为视觉语言的因果推理设计。
- 核心问题:现有大语言模型(LLMs)在多模态任务中依赖虚假相关性,缺乏对因果关系的建模,限制了模型的泛化能力和认知推理能力。
- 解决方案:提出CausalVLR,首个开源的视觉-语言因果推理工具箱,整合了多种因果发现与推理方法,支持多模态任务(如VQA、医疗报告生成等),旨在通过因果建模提升模型的鲁棒性和可解释性。
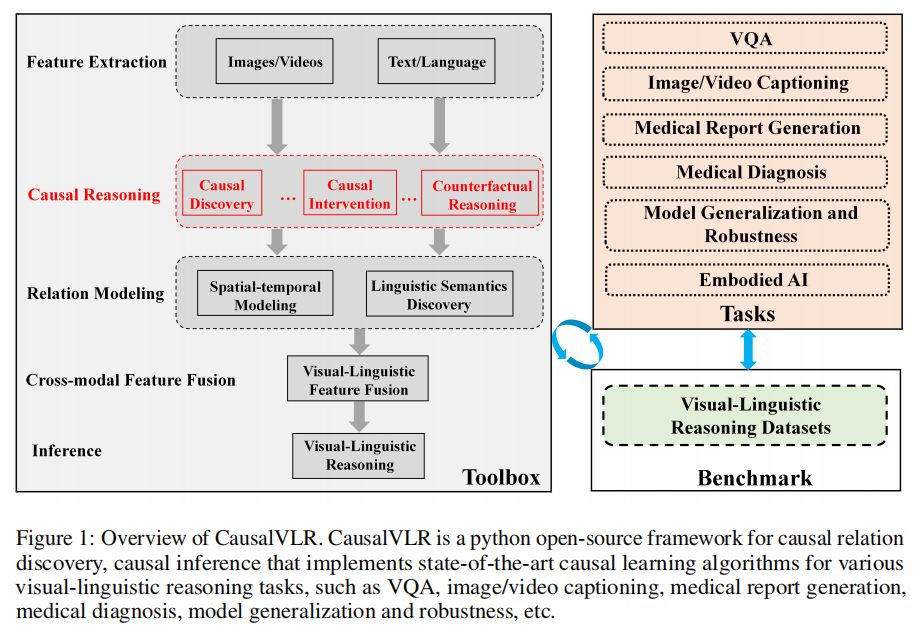
CausalVLR 具备以下核心特性:
(1) 模块化设计:将视觉-语言推理框架分解为独立组件,支持通过组合不同模块灵活构建定制化框架。
(2) 开箱即用的多框架支持:内置主流前沿视觉-语言推理框架,可直接调用。
(3) 高效性:所有基础模块与运算均基于GPU实现,确保最优性能。
(4) 技术先进性:代码源自因果推断与视觉-语言推理领域经验丰富的HCP-Lab团队,持续迭代优化。
除提供代码库与基准测试结果外,本文还分享了视觉-语言因果推理的最佳实践与经验,包括对超参数、模型架构及训练策略的系统性消融实验与分析。这些工作旨在推动未来研究,并促进不同方法的对比评估。
算法

| 任务 (Task) | 算法 (Algorithm) | 对应论文与技术亮点 |
|---|---|---|
| Causal CoT | CausalGPT [21] | 论文: Ziyi Tang et al. “Towards CausalGPT: A Multi-Agent Approach for Faithful Knowledge Reasoning via Promoting Causal Consistency in LLMs” (arXiv 2023). 技术亮点: 多智能体协作框架,通过因果一致性评估器(Evaluator)结合反事实推理修正答案,提升思维链的因果逻辑可靠性。 |
| VQA | CMCIR [8; 6] | 论文: Yang Liu et al. “Cross-modal Causal Relational Reasoning for Event-level Visual Question Answering” (IEEE TPAMI 2023). 技术亮点: 跨模态因果干预(前门/后门干预),时空Transformer建模多模态交互,解决事件级VQA中的虚假关联问题。 |
| VQA | VCSR [25] | 论文: Yushen Wei et al. “Visual Causal Scene Refinement for Video Question Answering” (ACM MM 2023). 技术亮点: 基于视觉因果场景分离(CSS模块)和问题引导的时序特征优化(QGR模块),通过前门干预实现视频因果场景发现。 |
| Image Captioning | AAAI2023 [26] | 论文: Yang Wu et al. “Scene Graph to Image Synthesis via Knowledge Consensus” (AAAI 2023). 技术亮点: 基于知识共识的场景图到图像生成,增强图像描述的语义一致性。 |
| Medical Report Generation | VLCI [1] | 论文: Weixing Chen et al. “Visual-Linguistic Causal Intervention for Radiology Report Generation” (arXiv 2023). 技术亮点: 隐式视觉-语言因果前门干预模块(VDM/LDM),结合PLM与MIM预训练,消除医疗报告生成中的跨模态混淆因素。 |
| Medical Diagnosis | TPAMI2023 [4] | 论文: Junfan Lin et al. “Towards Causality-aware Inferring: A Sequential Discriminative Approach for Medical Diagnosis” (IEEE TPAMI 2023). 技术亮点: 因果感知的序列判别框架,优化医疗诊断中的病理推理过程。 |
| Model Generalization and Robustness | CVPR2023 [27] | 论文: Yao Xiao et al. “Masked Images are Counterfactual Samples for Robust Fine-tuning” (CVPR 2023). 技术亮点: 基于掩码图像的反事实微调方法,提升模型对遮挡和噪声的鲁棒性。 |
CaCo-CoT
Towards causalgpt: A multi-agent approach for faithful knowledge reasoning via promoting causal consistency in llms.
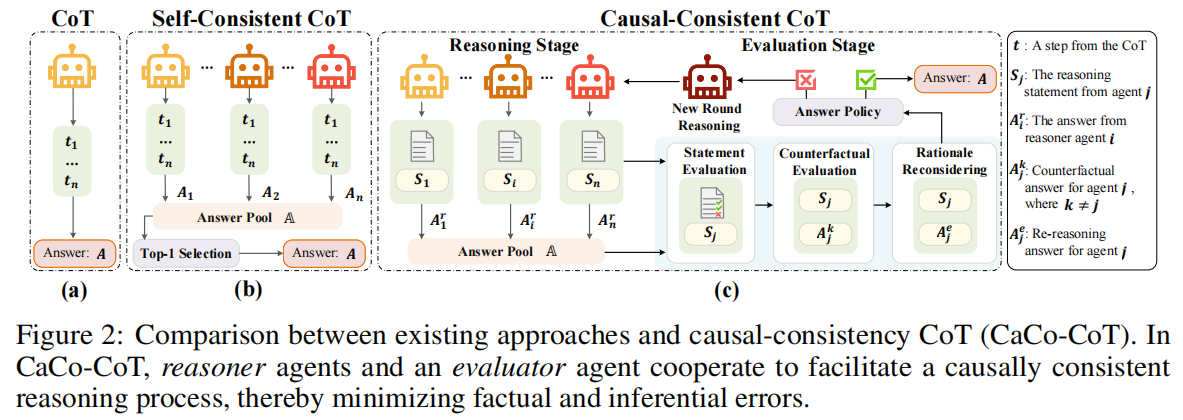
- 挑战:尽管大型语言模型(LLMs)在知识存储和生成方面表现优异,但知识推理能力仍存在显著缺陷,包括知识召回不稳定、推理过程易受干扰(如事实错误、逻辑谬误)。
- 现有方法不足
- 自主规划或大量采样推理链效率低下,且未解决中间步骤的推理错误。
- 多数投票法可能因模型共同偏见导致错误答案被选中。
- 推理步骤的线性依赖(如链式思维CoT)难以处理复杂非线性问题。
CaCo-COT:通过多智能体协作(推理者与评估者)实现因果一致性检查,提升推理忠实性。
因果一致性思维链(CaCo-CoT)框架(如图2所示)的贡献如下:
因果一致性验证:
- 推理者(Reasoners)
- 概念解释:明确问题中的关键术语和原理,减少误解。
- 子问题分解:将复杂问题拆分为逻辑关联的子问题。
- 逻辑生成与答案合成:基于知识生成推理链并得出结论。
- 引入评估器(Evaluator),通过逐步检查解决方案中的陈述,确保推理过程符合因果逻辑。
- 非因果方向的结构分析:逆向检查推理链的全局一致性,识别逻辑漏洞。
- 反事实矛盾检测:对原始问题应用反事实答案,检测逻辑矛盾。
- 再评估与共识达成:修正错误或确认最终答案。
- 推理者(Reasoners)
多智能体协作机制:若多数解决方案通过评估器的因果一致性验证,智能体群组将协作生成共识答案。
实验验证:在科学问答与常识推理任务中,CaCo-CoT通过系统实验证明其优于现有方法(如传统思维链和单智能体框架)。
VQA
CMCIR
Cross-Modal Causal Relational Reasoning for Event-Level Visual Question Answering, TPAMI, 2023.
现有视觉问答(VQA)方法存在以下问题:
- 跨模态伪相关(Spurious Correlations):模型容易学习到视觉与语言模态间的虚假关联。
- 事件级推理不足:缺乏对事件时序性、因果性和动态性的捕捉能力。
提出首个面向事件级视觉问答的因果感知框架CMCIR,通过跨模态因果干预(前门/后门干预)挖掘真实因果结构,消除视觉与语言模态间的虚假关联。
- 语言后门干预模块:基于语言语义关系的引导,设计后门因果干预模块,缓解语言模态内的虚假偏差,揭示语言因果依赖。
- 局部-全局因果注意力模块(LGCAM):通过前门因果干预聚合局部(如物体区域)与全局(如场景)视觉表征,解耦视觉模态的虚假相关性。
- 时空Transformer(STT):建模视觉(时空特征)与语言(语义)模态的细粒度共现交互,捕捉事件级动态关系。
- 视觉-语言特征融合(VLFF)模块:利用层次化语言语义关系自适应融合跨模态特征,生成全局语义感知的联合表征。
实验验证:
- 在SUTD-TrafficQA、TGIF-QA、MSVD-QA和MSRVTT-QA数据集上的实验表明,CMCIR在事件级VQA任务中显著优于基线模型。
- 消融实验验证了各模块(如LGCAM、STT)对性能提升的贡献。
VCSR:
- 视觉因果场景发现:提出首个基于前门因果干预的视频因果场景发现框架,从视频帧序列中分离因果相关场景与非因果干扰场景。
- 因果场景分离器(CSS):根据视觉-语言因果相关性,将视频片段划分为因果场景(直接影响答案)与非因果场景,并通过对比学习估计场景分离干预的因果效应。
- 问题引导的优化器(QGR):基于问题语义优化连续视频帧特征,提取更具代表性的时序片段特征,增强前门干预的鲁棒性。
实验验证:
- 在视频问答任务中,VCSR在NExT-QA和Causal-VidQA等数据集上达到SOTA性能。
- 可视化结果表明,CSS模块能有效定位与问题因果相关的关键场景。
本文内容
视频问题定位(VideoQG)要求模型在回答问题的同时,定位支持答案的视频片段,需同时完成视频问答(VideoQA)和时序定位(Temporal Grounding)。然而,现有方法存在以下问题:
- 虚假跨模态关联:模型依赖数据中的统计偏差(如语言/视觉短时关联),而非真实的因果视觉证据。
- 弱监督挑战:标注成本高导致缺乏时间定位标注,现有方法在无标注场景下效果受限,泛化性能差。
- 模型幻觉:大规模视觉语言模型(VLMs)易生成与视频内容无关的答案,影响可靠性。
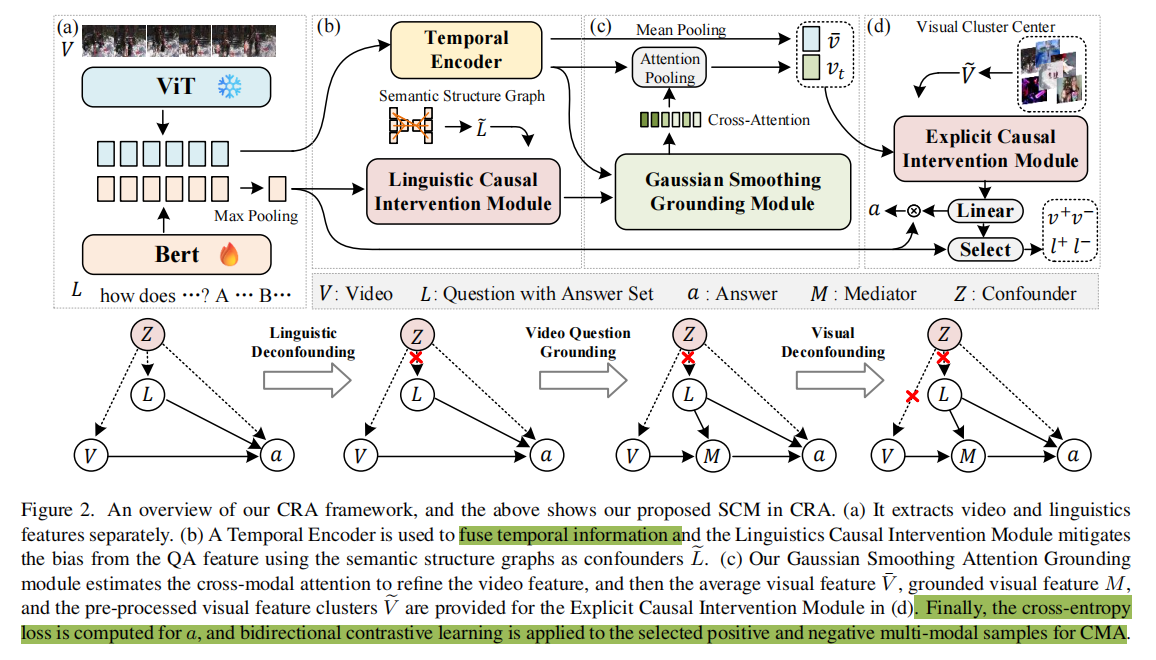
本文提出了一种名为跨模态因果关系对齐(Cross-modal Causal Relation Alignment, CRA)的新型VideoQG框架,以消除虚假相关性,提高问答与视频时间定位之间的因果一致性。CRA包含三个关键组件:
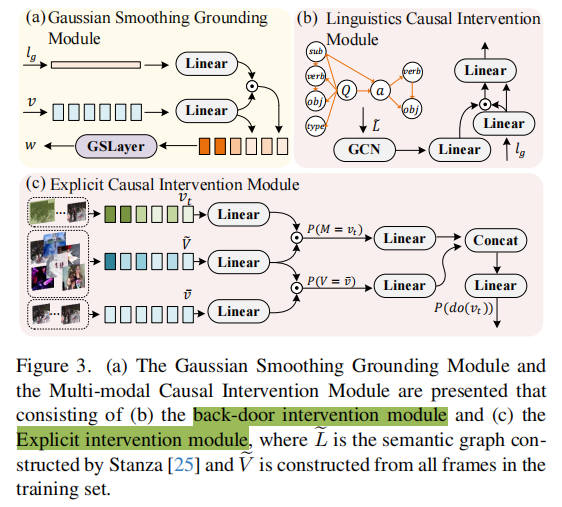
- 高斯平滑定位(Gaussian Smoothing Grounding, GSG):通过跨模态注意力估计时间间隔,利用自适应高斯滤波器去噪,生成精确的时间定位。作用:抑制时序噪声,提升关键帧定位鲁棒性。
- 跨模态对齐(Cross-Modal Alignment, CMA):采用双向对比学习(InfoNCE损失),对齐视频片段与QA特征,增强弱监督下的多模态关联。核心:通过正负样本采样,减少对标注数据的依赖。
- 显式因果干预(Explicit Causal Intervention, ECI):用于多模态去混杂。
- 视觉模态:通过前门干预(以视频片段为中介)消除视觉混淆因素。
- 语言模态:通过后门干预(基于语义结构图)阻断语言偏差路径。
- 技术亮点:结合因果推理,提升答案与定位的因果一致性。
在两个VideoQG数据集上进行的大量实验证明了我们的CRA在发现基于视觉定位的内容和实现稳健的问题推理方面的优越性。
参考
论文:https://arxiv.org/pdf/2503.07635
代码:https://github.com/WissingChen/CRA-GQA/tree/main
Cross-modal Causal Relation Alignment for Video Question Grounding-CSDN博客



