TRACE: TEMPORAL GROUNDING VIDEO LLM VIA CAUSAL EVENT MODELING
摘要
视频时序定位能力(VTG)是视频理解模型的一项关键能力,在视频浏览、视频编辑等下游任务中发挥了重要作用。为了能够同时处理各种任务,并实现零样本预测,越来越多的研究开始尝试使用视觉大模型完成VTG任务。然而,目前基于视频llm的方法完全依赖于自然语言生成,缺乏建模视频中固有的清晰结构的能力,限制了其处理VTG任务的有效性。为了解决这个问题,本文首先正式介绍了因果事件建模框架,该框架将视频LLM输出表示为事件序列,并使用以前的事件、视频输入和文本指令来预测当前事件。每个事件由三个部分组成:时间戳、显著性分数和文本caption。随后,本文提出了一种新颖的任务交错(task-interleaved)视频大模型TRACE,在实践中有效地实现了因果事件建模框架。TRACE会处理视觉帧、时间戳、显著分数和文本作为独立的任务,每个任务都使用不同的编码器和解码头。根据因果事件建模框架的公式,任务标记以交错的顺序排列。在各种VTG任务和数据集上进行的大量实验表明,与最先进的视频llm相比,TRACE具有优越的性能。
引言
视频时序定位(VTG)是视频理解模型的一项重要能力,并已成为一系列下游任务的基础,如时刻检索、密集视频字幕、视频亮点检测和视频摘要。虽然非生成模型在时刻检索和视频亮点检测方面表现出色,但它们是不灵活的、特定于任务的,需要大量的微调以获得最佳性能。为了应对这些挑战,最近的研究采用视频LLM作为通用模型,将时间戳信息集成到视觉输入中,并在VTG任务上对它们进行微调,以提高其性能,促进零样本预测。
非生成模型的局限性
- 任务特定性:需为每类任务(如检索、检测)设计独立架构,无法通过自然语言指令灵活切换任务。例:Moment-DETR只能做时刻检索,无法生成描述或回答视频相关问题。
- 微调依赖:迁移到新任务需重新训练模型头部(如分类层、回归层),数据效率低。
- 结构僵化:输入输出形式固定(如时间戳数值、得分),难以扩展至多模态生成任务。
融合时间戳信息的mllm:VideoLLaVA、VTimeLLM、Momentor、Efficient Temporal Extrapolation of Multimodal Large Language Models with Temporal Grounding Bridge、Number it: Temporal grounding videos like flipping manga
在长视频内容检索的研究领域中,用户常面临时间线导航效率低下的困境。传统的视频检索方法采用逐帧分析的线性处理策略,如同逐帧查字典,效率低下且泛化能力差。而现有的多模态大模型,虽然泛化能力更强,但是效果仍然差强人意。
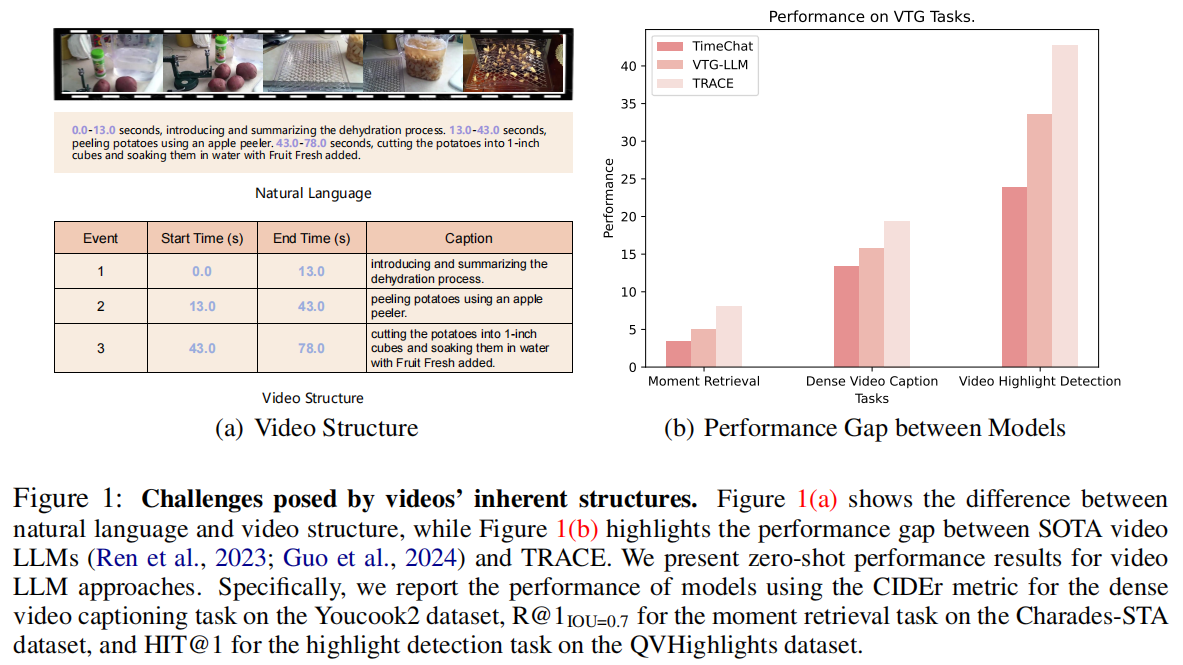
视频的固有结构带来的挑战:目前基于视频LLM的方法依赖于纯自然语言的生成。这种方法缺乏清晰的结构,并且不加选择地混合时间戳和文本caption等信息。(如图1a所示)相比之下,视频具有一种超越单纯的文本描述的内在结构。要准确地描述或从视频中进行推理,仅仅依靠自然语言文本是不够的。相反,相应的时间戳和显著性分数也是重要的组成部分。这些元素一起提供了对视频内容的更全面和结构化的理解。因此,当前的视频结构与现有视觉大模型之间的差距损害了模型有效建模视频事件的能力,并潜在地造成了视觉大模型难以在VTG任务上取得令人满意地结果。
总结现有方法缺陷:
- 传统非生成模型(如InternVideo)需针对任务微调,缺乏通用性。
- 视频LLM(如VideoChat)生成非结构化文本,无法精确建模时间戳和事件依赖。
因果事件建模方案:在本文中,我们的主要目标是开发一种新的视频LLM方法来解决LLM的语言建模与视频固有结构之间的不匹配问题。具体来说,我们专注于解决两个主要挑战:
(1)开发一个理论框架,从因果语言建模转向基于结构化的事件建模;
(2)基于理论框架构建一个实际的视频LLM,以提供一个有效的解决方案。
为了实现这一点,我们首先引入了因果事件建模框架,其中视频LLM输出被表示为事件序列,每个事件序列包含时间戳、显著分数和文本caption。根据视频输入、文本指令和前面的事件来预测下一个事件。为了在实践中有效地实现因果事件建模框架,我们提出了一种新的任务交错视频LLM,TRACE–通过因果事件建模进行TempoRAl定位(TempoRAl grounding via Causal Event modeling),如图2所示。TRACE将视觉帧、时间戳、显著分数和文本视为单独的任务,为每个任务使用不同的编码器和解码头,任务标记以交错的方式排序。此外,我们还开发了一种自适应的head-switching方法来改进生成。我们在各种VTG任务中的数值结果显示,与最先进的(SOTA)视频LLM相比,TRACE的性能更好。
关键贡献:
我们通过一系列事件对视频进行建模,并提出了因果事件建模框架来捕捉视频的固有结构。然后,我们提出了一种新的任务交错视频LLM模型,TRACE,通过对时间戳、显著分数和文本标题的顺序编码/解码来实现因果事件建模框架。
我们在多个VTG任务和数据集上进行了全面的实验,以验证TRACE的有效性。结果显示,与SOTA视频llm相比,TRACE有了显著的改善。值得注意的是,TRACE在Youcook2(CIDEr和F1分数)上提高了3.1和4.9%,在召回率(IOU = {0.5,0.7})上提高了6.5%和3.7%,在QVHighlights上mAP和HIT@1上提高了10.3%和9.2%。此外,TRACE获得了与传统的非生成式和特定于任务的方法相当的性能,突出了视频llm在VTG任务中表现出色的潜力。
相关工作
视频时间定位
VTG旨在精确地识别给定视频中的事件的时间戳,包含多个子任务如时刻检索、密集视频字幕、视频亮点检测和视频摘要。对于时刻检索、视频摘要和视频亮点检测等任务,传统的方法主要使用大规模的视频-文本预训练。随后,他们通过合并特定于任务的预测头来对预先训练过的模型进行微调。虽然这些方法已经证明了令人满意的结果,但它们对于预训练是资源密集型的,缺乏零样本能力,每个模型只能处理一个特定的任务,并且通常需要对许多下游任务进行额外的微调。
对于密集的视频标注任务,Vid2Seq使用特殊的时间token来表示时间戳。一些方法集成了额外的输入信息,例如来自训练数据集的文本查询,而其他模型则利用不同的解码头并行解码时间戳和文本标题(Learning grounded vision-language representation for versatile understanding in untrimmed videos.)。然而,这些架构是专门为密集的视频字幕任务而设计的,不能很容易地适应LLM结构来充分利用预先训练好的LLM的能力,也缺乏零样本能力。
VTG视觉大模型
LLM已经显示出了在获取知识和使用零样本方法解决现实世界挑战方面的巨大潜力。近期研究聚焦于整合来自其他模态的知识如视觉和音频以增强LLM的能力。在视觉领域,视频大模型已经成为重要的研究课题。传统的视频LLM在视频问答、推理和视频字幕等任务上取得了显著的性能改进。然而,这些方法在精确定位视频中的事件时间戳方面遇到了困难。
TimeChat,VTimeLLM和Hawkeye尝试克服这一挑战,通过在VTG任务数据集上微调大模型。近期LITA引入了快-慢视觉token,并将时间token合并到LLM标记器中。Momentor提出了一个时间编码器来解决时间标记量化错误。VTG-LLM集成了特殊的时间token和时间位置嵌入,以提高视频llm理解时间戳的能力。但是,这些方法并没有考虑到视频的固有结构,仍然不能达到令人满意的性能。
本文方法
本节目标是开发一种新的视频LLM,它与视频结构保持一致,解决两个问题:(1)如何建模与视频结构良好对齐的结构化视频LLM输出,以及(2)如何实现理论模型。我们首先提出因果事件建模框架来解决“如何建模”。然后,我们引入Trace来解决“如何实现”。
建模视频的固有结构
- 根据事件制定视觉大模型的输出:给定指令I和视觉输入F,将大模型的输出R表示为一组事件序列{e1, e2, … , ek},每个事件ek = (tk, sk, ck),包含时间戳tk,显著性得分sk,文本标题ck。总的来说,我们有:
$$
R = {e_1, e_2, … , e_k} = {(t_k, s_k, c_k) | 1 ≤ k ≤ K}
$$
- 因果事件建模框架:为了有效地利用预先训练过的llm的知识,因果事件建模的设计共享了因果语言模型的潜在直觉,如下所示:
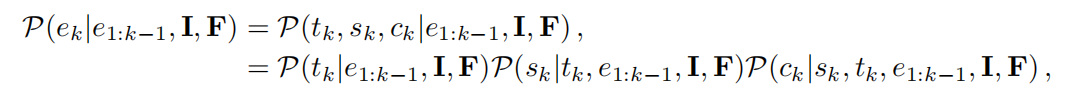
下一个事件ek由文本指令、视觉输入和以前的事件决定。
我们可以发现,因果事件建模框架与视频结构很好地对齐(图1(a)): (1)时间戳、显著分数和文本标题在每个事件中依次解码;(2)事件按时间戳排序。
- 时间戳生成
- 输入: 前序事件序列 e1:k−1、文本指令 I、视频帧 F。
- 作用: 确定当前事件在视频中的时间位置。
- 模型实现: 时间解码头根据视频特征和指令,预测事件开始/结束时间。
- 显著分数生成
- 新增依赖: 当前时间戳 tk(事件定位完成后,评估其重要性)。
- 作用: 量化事件的关键性(如高光片段 vs 普通片段)。
- 模型实现: 分数解码头结合时间位置和上下文,输出重要性得分。
- 文本描述生成
- 新增依赖: 显著分数 sk(重要性影响描述生成,如重点事件需详细描述)。
- 作用: 生成自然语言描述,内容受时间和重要性约束。
- 模型实现: 文本解码头基于前两步结果,生成连贯的语义描述。
因果语言模型(causal language model),是跟掩码语言模型相对的语言模型,跟transformer机制中的decoder很相似,因果语言模型采用了对角掩蔽矩阵,使得每个token只能看到在它之前的token信息,而看不到在它之后的token,模型的训练目标是根据在这之前的token来预测下一个位置的token。通常是根据概率分布来计算词之间组合的出现概率,因果语言模型根据所有之前的token信息来预测当前时刻token,所以可以很直接地应用到文本生成任务中。可以理解为encoder-decoder的模型结果使用了完整的transformer结构,但是因果语言模型则只用到transformer的decoder结构(同时去掉transformer中间的encoder-decoder attention,因为没有encoder的结构)。
| 维度 | 传统语言建模 | 因果事件建模 |
|---|---|---|
| 输入单元 | Token序列(词/子词) | 结构化事件单元(时间戳+分数+文本) |
| 生成逻辑 | 自回归Token预测 | 分阶段条件概率链式生成 |
| 建模重点 | 文本语义连贯性 | 时间结构+事件重要性+语义一致性 |
| 输出结构 | 线性文本序列 | 带时间戳的多模态事件序列 |
| 依赖关系 | 局部上下文窗口 | 全局时间约束与跨事件因果依赖 |
Trace:任务交错模型
在上面的式子中,我们引入了一个正式的因果事件建模框架来解决建模结构化视频LLM输出的挑战。本节说明了用于实现因果事件建模框架的Trace模型的设计(图2)。
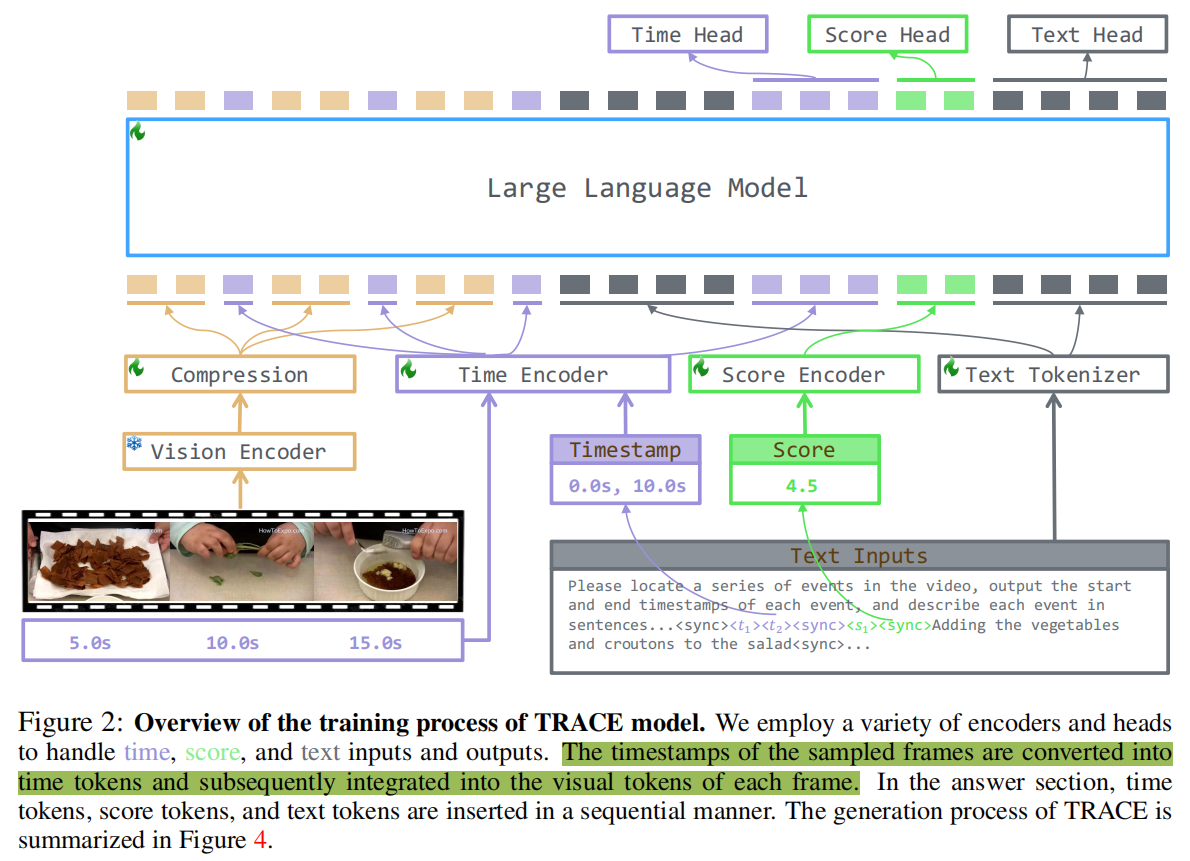
如等式2所示、因果事件建模框架需要对视觉帧(F)、文本(I和ck)、时间戳(tk)和分数(sk)进行编码/解码。因此,TRACE将这些元素视为不同的任务,并使用以下设计来有效地管理它们。
- 独立的多任务处理。为每个任务利用单独的编码器和解码头将任务输入转换为任务标记,并解码任务token到输出。
- 任务交错的序列建模。任务标记根据等式以交错的方式进行排序并输入到LLM骨干。
- 自适应头切换机制。在生成过程中,我们实现了一个自适应的头切换机制来选择适当的解码头来产生下一个token。
分离多任务处理
TRACE由四个独特的任务组成:视觉帧、文本、时间戳和分数。关于文本,我们直接利用LLM主干的文本标注器和LLM头(Mistral-7B-v0.2)。此外,我们还添加了一个特殊的标记<sync>,用于指示文本任务的结束。对其他任务的处理的详细介绍如下。
时间戳和分数处理:为了处理时间戳和分数信息,我们使用了两个独立的编码器和解码头,它们都共享相同的架构。具体来说,每个编码器都使用包含13个token的分词器进行初始化: 11个数字标记<0>、···、<9>、<.>。用于表示时间戳/分数,<sep>标记每个时间戳/分数的结束,<sync>表示当前任务的结束。token embeddings使用LLM token embeddings进行初始化。
根据VTG-LLM的研究,我们将每个时间戳/分数格式化为相同的长度,包括4个整数部分、1个点和1个分数部分。随后,在时间戳/分数之间插入<sep>,并在每个时间戳/分数输入序列的末尾附加<sync>。例如,时间戳输入[10.23,125.37]将被标记化为以下序列:⟨0⟩⟨0⟩⟨1⟩⟨0⟩⟨.⟩⟨2⟩⟨sep⟩⟨0⟩⟨1⟩⟨2⟩⟨5⟩⟨.⟩⟨4⟩⟨sync⟩。分数用 3 位编码(例:[4.5] →<4><.><5><sync>)
- Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding
视觉帧处理:给定一个t帧视频,我们首先使用预先训练的CLIP ViT-L对帧进行编码,每一帧被编码为576个视觉token。随后,我们采用了基于插槽的压缩(slot-based compression,也是来自VTG-LLM)来将视觉token的数量减少到每帧8个。此外,为了将时间信息集成到视觉输入中,我们使用时间编码器对每个采样帧的时间戳进行编码,并删除sync和sep令牌,从而为每一帧产生6个时间token。最后,我们将8个视觉标记与6个时间标记连接起来,形成每个帧的视觉输入。
- 该方法的核心是通过可学习的插槽向量(Slot Vectors)与输入token进行注意力交互,计算每个插槽对输入token的权重,最终通过加权平均生成压缩后的token。
- 输入分割:将每帧的视觉token(如24x24=576)视为输入序列。
- Slot初始化:定义K=8个可训练的slot向量Φ_1到Φ_8,每个维度为d(与token维度相同)。
- 注意力权重计算:对于每个slot k,计算其与所有576个token的相似度(通过点积Φ_k^T z_i),然后通过softmax归一化得到权重。
- Slot生成:每个slot s_k是权重加权的token之和,即s_k = Σ (softmax(Φ_k^T z_i) * z_i)。
- 输出压缩后的token:最终得到8个slot tokens作为该帧的压缩表示。
任务交错序列建模
利用处理后的任务标记,遵循式2构建序列。token序列顺序说明在图3中。
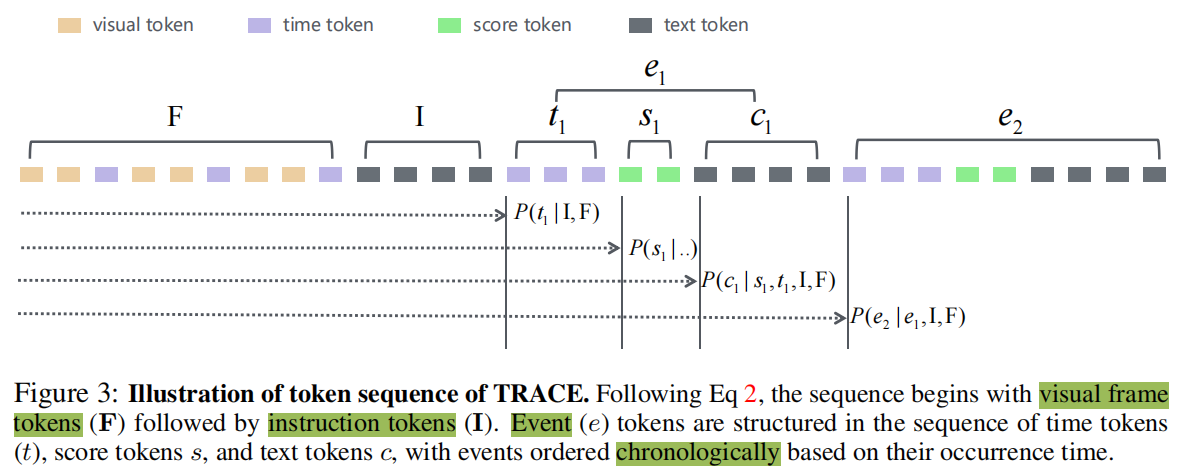
事件间序列顺序:序列以视觉帧标记F开始,然后是文本指令标记I。对于事件部分,事件标记根据事件的发生时间进行排序,以与因果事件建模公式对齐。
事件内序列顺序:对于每个事件,标记按时间标记、分数标记、文本标记顺序排列。因果事件建模框架作为一个专门的自回归模型出现,具有一个独特的序列顺序,与视频结构紧密一致。
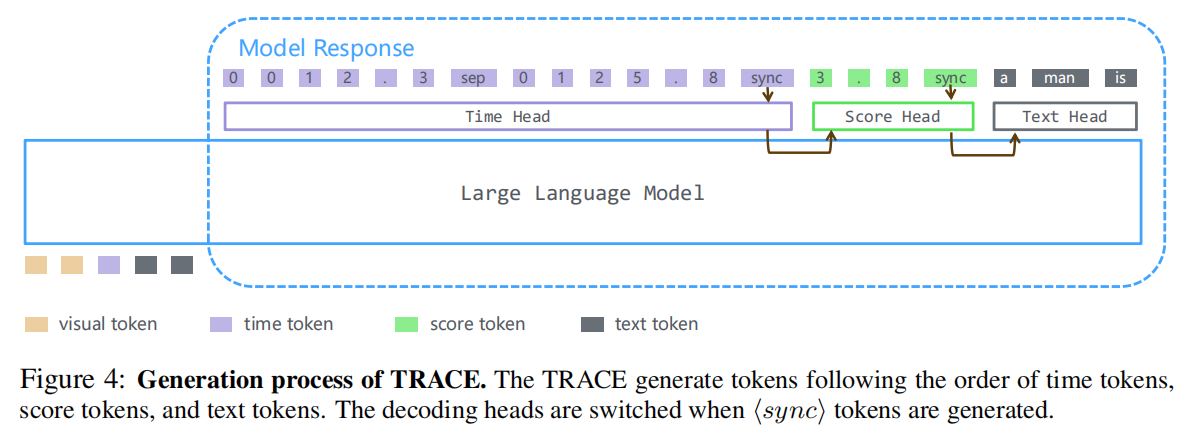
使用<sync>切换head
由于TRACE在训练过程中对各种任务使用不同的解码头,因此在生成过程中根据之前解码的标记选择合适的解码头是至关重要的。<sync>标记促进了这种选择。如图4所示,TRACE按照时间、分数和文本标记的顺序生成token。sync标记的检测会提示TRACE相应地切换解码头。头部按时间头、分数头、文本头的顺序循环切换。
训练策略
本节概述了TRACE训练过程,其中包括两个阶段。对于阶段1,任务模块,如视觉压缩层、任务编码器和任务头被训练以初始化。对于阶段2,LLM主干被微调,同时保持任务模块调优。详细的设置和数据集如下所示。
模型 backbone 基于 Mistral-7B 架构,分两阶段训练:
- 第一阶段:任务模块的初始化。训练视觉压缩模块 + 任务头(时间、分数、文本头)(每个视频抽取128 帧,学习率 1e-3),冻结视觉编码器和大模型主干。
- 第二阶段:指令微调用于增强VTG能力。LLM主干和任务模块进行了微调,只有视觉编码器保持固定。对于每个视频,划分为128个clip,每个clip随机抽取1帧,学习率 5e-6。

阶段一用到的数据集:(1)图像和视频caption数据集,用于初始化视觉压缩层的数据集。这组数据集包括Valley、LLaVA_Image、TextVR,以及随机采样的ShareGPT4Video数据集子集。(2)用于任务编码器/头初始化的VTG数据集。我们在这一组中使用了VTG-IT数据集。
阶段二用到的数据集:(1)VTG指令调优数据集:VTG-IT、ActivityNet Captions、InternVid的子集,得到一组635k的样本。过滤掉低质量的样本,并对VTG-IT-VHD和VTG-IT-VS数据集进行重新注释。(2)视频caption数据集,以保持视觉压缩层的质量。使用了来自第一阶段的部分视频数据,如Valley、TextVR、ShareGPT4Video。这些数据集通过只保留具有相同视频但有不同指令的样本的一个样本来进行压缩,产生284K数据。(3)视频问答数据集,以增强TRACE的推理能力。这一部分使用了VideoChatGPT和NextQA。
实验
baseline
我们评估了模型在三个不同的任务上的性能:
密集视频caption:我们使用Youcook2和ActivityNet caption数据集作为评估数据集。评估指标包括CIDEr、METEOR和SODA_c,用于评估caption的质量。这些指标在不同的IoU阈值{0 .3、0.5、0.7、0.9}下取平均值。此外,我们报告f1分数来衡量模型准确定位时间戳的能力。
时刻检索:我们利用Charades-STA测试集进行时刻检索任务,并报告在IOU阈值为0.5和0.7时的召回率。此外,我们还给出了mIOU的结果。
视频亮点检测:我们使用QVHighlight数据集的验证集,报告IOU阈值为0.5和0.75的平均精度(mAP),以及代表得分最高剪辑的HIT@1的命中率。
| 任务类型 | 评估指标 |
|---|---|
| 密集视频描述 | - CIDEr:基于n-gram的生成文本与参考描述的语义相似度 - SODA_c:故事级时序对齐与内容匹配度 - F1 Score:预测时间戳与真实区间的重叠精度 |
| 时刻检索 | - **R@1 (IoU=0.5/0.7)**:IoU阈值下检索到的正确时刻的召回率 |
| 视频高光检测 | - mAP:平均精度(IoU=0.5/0.75) - HIT@1:预测最高分片段是否为真实高光 |
| 数据集 | 任务类型 | 数据规模 | 评估目标 |
|---|---|---|---|
| YouCook2 | 密集视频描述 | 2,000+视频片段 | 生成带时间戳的多段视频描述,评估描述质量与时间定位精度 |
| Charades-STA | 时刻检索 | 6,672个视频-文本对 | 根据文本查询定位视频中的事件起止时间点 |
| QVHighlights | 视频高光检测 | 10,000+视频片段 | 预测视频中与文本查询相关的高光片段及显著性评分曲线 |
数据格式
对于一般的任务,如视频字幕、图像字幕和视频QA,数据的回答部分不包括时间戳或分数。因此,使用单个令牌<sync>作为时间戳和分数的占位符,表示这部分响应的空响应。
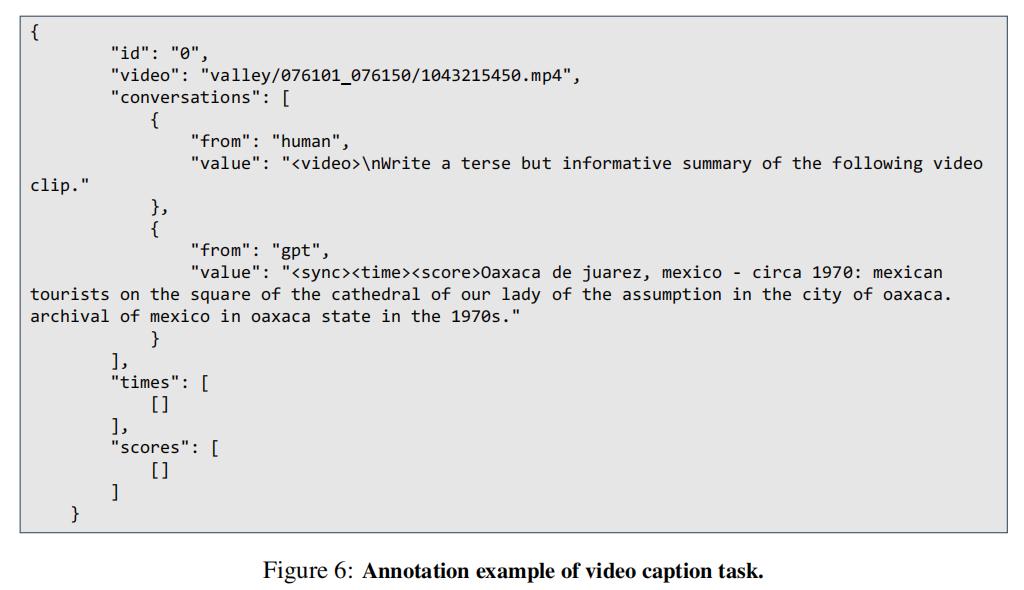
密集视频字幕任务:密集的视频字幕任务仅包括时间戳和文本字幕响应。因此,我们使用单个<sync>作为分数的占位符。
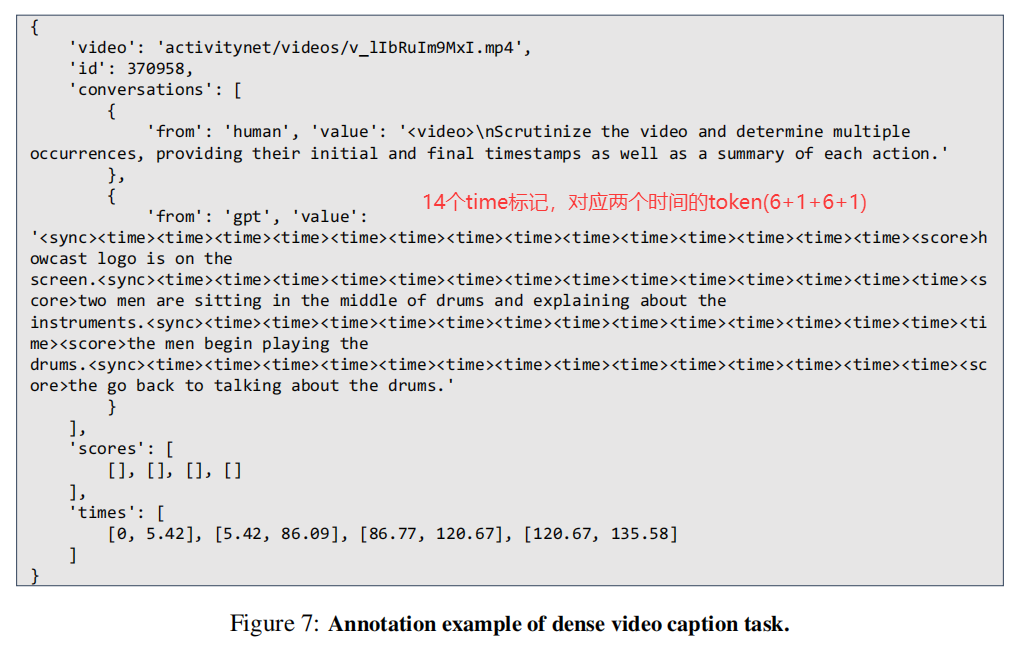
时刻检索任务:
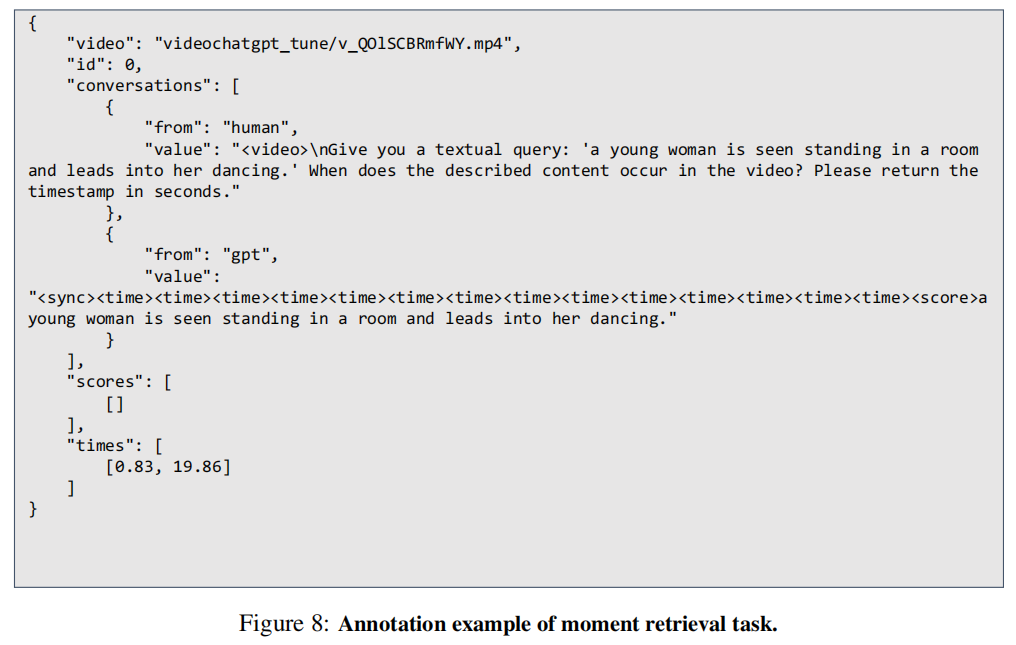
视频亮点检测任务:

视频摘要:
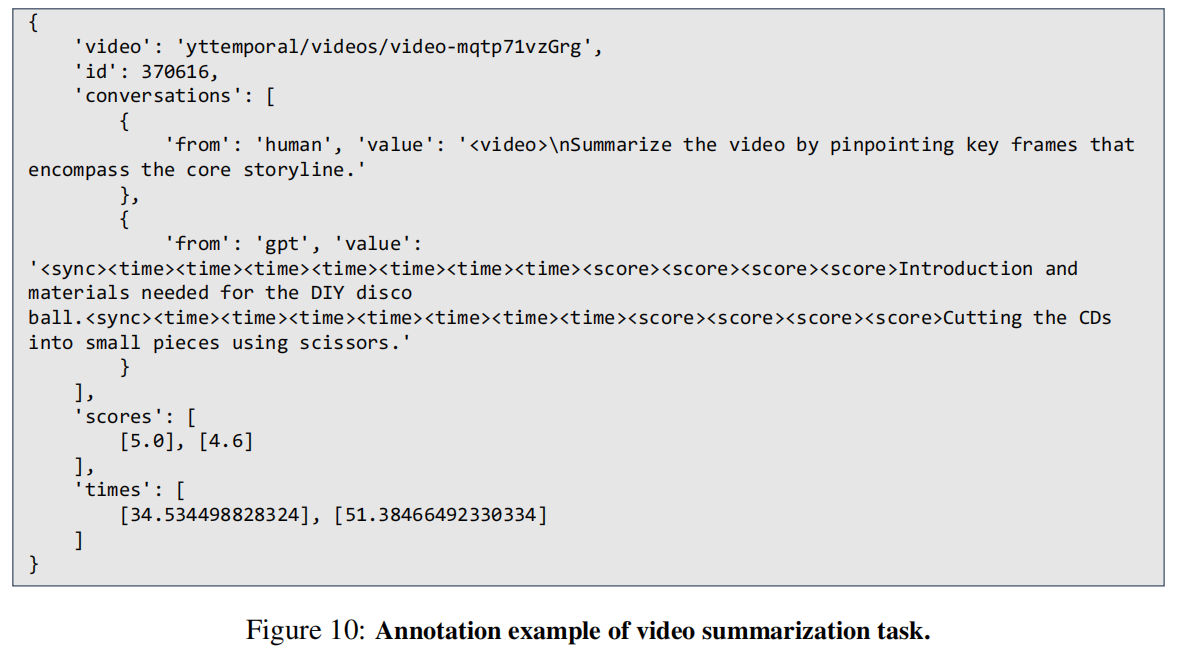
Trace性能
优于其他视频LLM的零样本性能。在表2中,我们展示了TRACE与SOTA视频LLM基线相比的零样本性能。
- 在CIDEr和F1评分上实现了3.1%和4.9%的性能改进;召回率上6.5%和3.7%的性能提升;mAP 和 HIT@1 指标有10.3% 和 9.2%的性能提升。
- 比特定于任务的模型和更大的llm具有更好的性能。作为一种能够处理各种任务的多面手模型,TRACE的性能超过了HawkEye等特定任务的模型
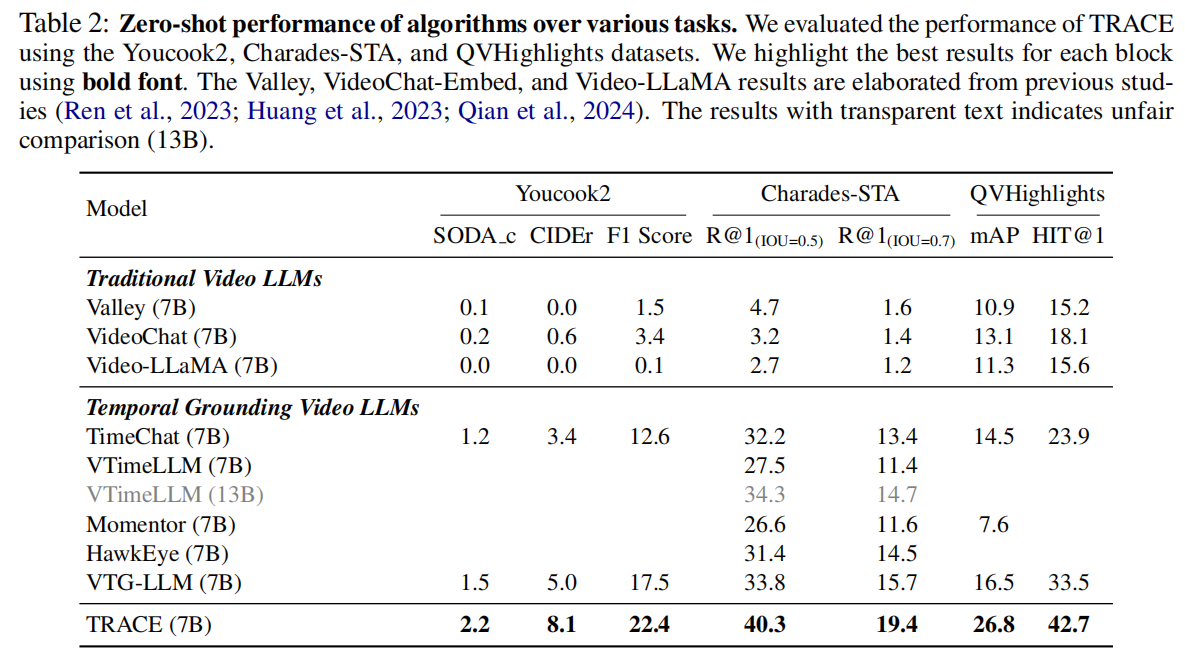
TRACE在ActivityNet Caption数据集上的性能。在表4中,我们展示了TRACE在ActivityNet Caption数据集上的性能。除Momentor外,所有报告的算法都已将ActivityNet Caption数据集作为训练数据的一部分。结果表明,TRACE在时刻检索任务中获得了最好的性能,并在密集视频字幕任务中显示了与VTimeLLM相当的结果。
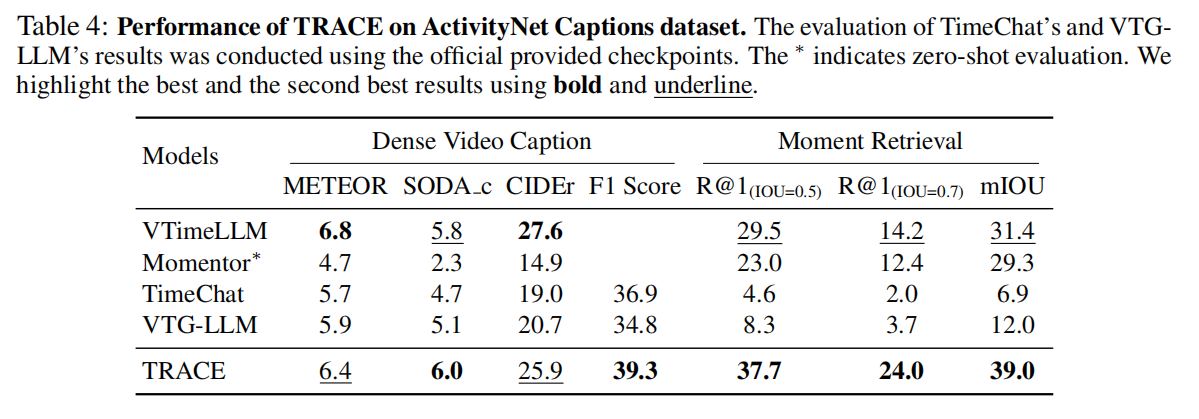
消融研究
因果事件建模框架提高了VTG任务中的模型性能。在表3的“框架消融研究”部分,我们在没有使用因果事件建模框架的情况下进行了实验。结果表明,采用因果事件建模框架可以显著提高模型的性能,即使采样的视频帧较少,也能获得更好的效果。
对不同的任务使用不同的编码器和解码头是获得最佳效果的必要条件。在表3的“w/o独立编码器/头”部分中,我们通过对不同的任务不使用单独的编码器和解码器头来进行消融研究。直接将时间标记和分数标记合并到文本标记化器中。结果表明,使用共享的编码器/解码头进行因果事件建模框架,显著破坏了llm的预学习知识,导致不相关和无意义的反应。
TRACE的性能随着帧数的增加而提高。我们对采样帧的数量进行了消融研究,如表3所示。结果表明:(1)性能随着采样帧数的增加而增强;(2)仅采样8帧时,TRACE的性能优于VTG-LLM和TimeChat等SOTA视频llm,甚至更好,证明了模型结构的有效性
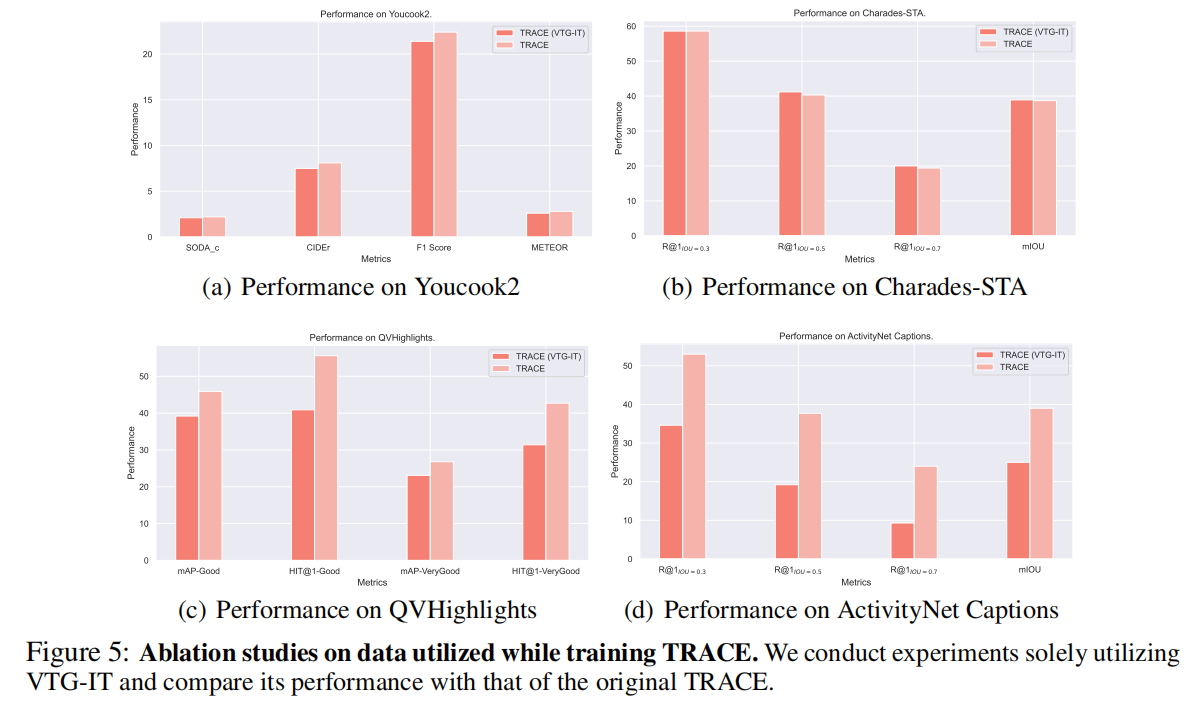
结合InternVid和ActivityNet Captions数据集能够提高TRACE在长视频上的性能。我们通过专门使用VTG-IT作为VTG任务的训练数据来进行消融研究。结果表明,在合并InternVid和ActivityNet Captions数据集时,长视频的性能有所提高,导致Youcook2、QVHighlight和ActivityNet数据集的性能有所提高。相反,在短视频上的性能略有下降(Charades-STA),这表明InternVid和ActivityNet数据集中的注释可能不如短视频注释中的准确。
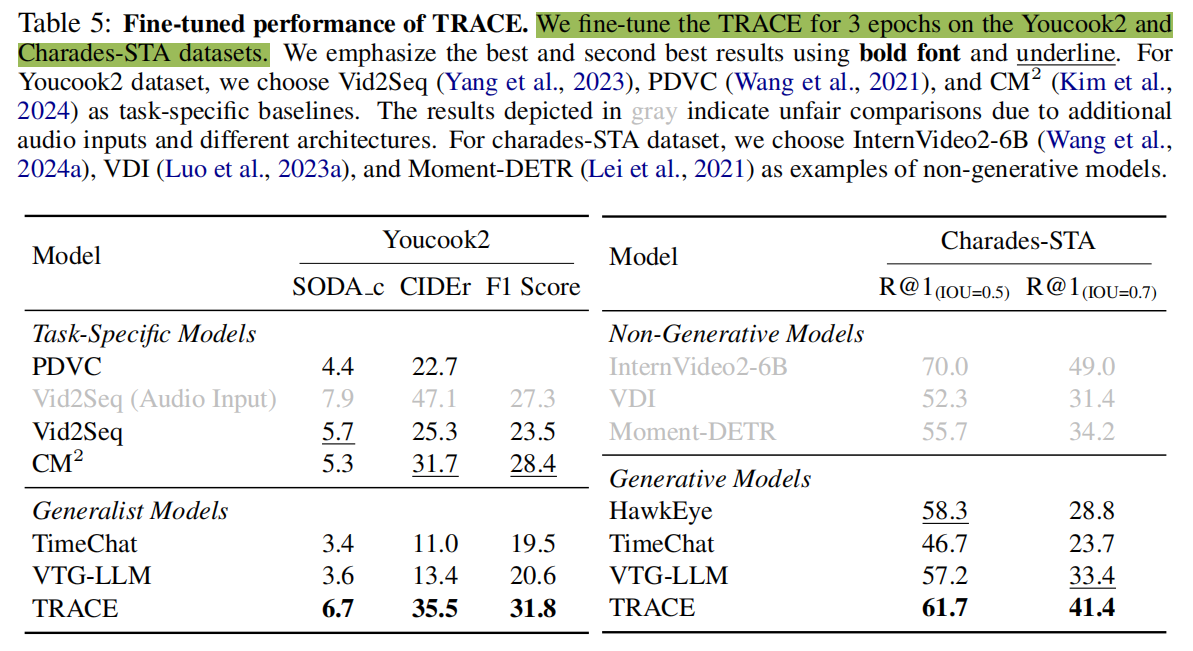
微调性能
微调后的TRACE与传统方法的性能比较。
- TRACE的表现显著优于通用基线。TimeChat和VTG-LLM即使在微调后也难以获得令人满意的性能,TRACE从微调中获得显著的好处,并获得明显比通用基线更好的性能。
- TRACE获得了与非生成的任务特定的SOTA模型相当的性能。TRACE在Youcook2获得了新SOTA,在charades-sta数据集上的性能也与非生成模型如InternVideo和VDI等竞争。然而,这些方法不能同时处理各种任务,而且缺乏零样本能力——这是本文TRACE踪的贡献。
案例研究
本节深入探讨本文提出的因果建模方法,并对以下三个核心概念进行系统性对比与讨论:
- 因果语言建模(Causal Language Modeling)
因果语言建模是仅解码器架构的大型语言模型(LLMs)的经典范式,已成为当前视频LLMs的基础方法。其核心是通过自回归预测下一个词的概率,建模文本序列的生成过程。 - 因果事件建模(Causal Event Modeling)
与上述方法不同,本文提出的TRACE框架引入因果事件建模。该方法通过事件三元组(event triplets)结构化视频LLMs的响应,为理解视频内容提供新范式。事件三元组可显式表征事件间的因果链,例如“动作A导致状态B,状态B触发事件C”,从而增强模型对视频逻辑的推理能力。 - 完全因果关系建模/发现(Complete Causal Relationship Modeling/Discovery)
传统视频理解模型侧重于发现与分析视频事件间的复杂关系(如时序依赖、因果链、多事件交互)。这类方法通过全面建模事件关联性,提供对视频内容更深层次的全局理解。例如,通过时空图网络建模人物交互,或利用注意力机制捕捉跨帧依赖关系。
相似之处:因果语言建模和因果事件建模都依赖于仅使用解码器的LLM,它使用视频视觉内容(F)和指令(I)作为输入。然后,这些模型根据I和f的观察结果产生响应。
区别:输出格式。对于因果语言建模,响应可以看作是一个完整的文本内容,在这里,时间戳、分数和文本都由文本标记表示,并按照自然语言结构进行排序。对于因果事件建模,响应被格式化为一系列的事件三元组。
关键改进:我们可以发现,因果事件建模比因果语言建模的关键改进来自于模型响应的格式。
事件间的关系通过下一个事件预测公式进行建模。
事件内的关系,探讨因果关联 ti->si 和 (ti,si)->ci。
启用独立的时间戳、分数和文本建模。可以分离时间戳ti、分数si和文本ci的建模,并使用不同的编码器和解码器独立地建模每个组件。由于直接向文本标记器中添加新的标记可能会显著破坏预训练的LLM,这种分解有助于消除这个问题,并且TRACE体系结构保留了处理一般视频理解任务的能力。
通过因果发现模型改进TRACE的潜在方向
当前视频LLM直接从文本指令和视觉帧生成答案,未显式建模事件间因果关系。尽管TRACE通过事件三元组(时间戳、分数、文本)改善了这一问题,但其生成仍受限于解码器架构(仅依赖历史事件生成后续三元组)。未来可通过以下方式结合因果发现模型实现改进:
- 将因果发现模型的输出作为视频LLM的输入
- 方法:将因果图(如Chen et al., 2024c; Li et al., 2020生成的因果图)编码为模型输入。
- 原始生成概率:p(R∣F,I)
- 改进后概率:p(R∣F,I,C)(其中C为因果图)
- 优势:为模型提供更丰富的上下文,提升回答准确性。
- 利用因果发现模型构建链式思维(Chain-of-Thought)示例
- 方法:引导视频LLM先生成因果图,再基于因果图回答问题(类似Jin et al., 2022)。
- 联合概率分解:p(C,R∣F,I)=p(C∣F,I)p(R∣C,F,I)
- 优势:显式分离因果推理与答案生成步骤,增强可解释性。
- 利用因果发现模型修改视觉输入的注意力掩码
- 现状:现有模型对视觉输入的注意力掩码设计与文本相同,未考虑因果依赖。
- 改进方向:根据因果图调整视觉特征的重要性权重(如抑制无关帧的注意力)。
- 价值:聚焦关键因果事件,减少噪声干扰。
总结
本文旨在解决视频时序定位(VTG)任务中视频结构与视频大语言模型(LLMs)之间的不匹配问题,并提出一种因果事件建模框架及TRACE模型作为解决方案。实验结果表明,TRACE在零样本学习场景下显著优于其他视频LLM基线模型;经过微调后,TRACE相较于传统非生成式及任务专用模型亦展现出竞争力。通过突破现有视频LLM架构的固有局限,TRACE验证了视频LLMs在VTG任务中的潜力,并有望成为未来视频LLMs研究的基石。
未来研究方向
尽管TRACE已取得显著进展,其能力仍可通过以下方向进一步扩展:
复杂事件关系的建模:TRACE当前依赖预训练的仅解码器LLMs架构,仅利用历史事件预测下一事件,这可能无法充分捕捉复杂的事件关系。改进方案可引入因果发现模型的输出作为补充输入,以增强对视频内容的全局理解。
多任务标注扩展:通过融合问答对的时序戳(occurrence timestamps)及问题-答案匹配分数(matching score)至更多视频理解任务的标注中,可显著提升TRACE的整体性能。
参考
论文地址:2410.05643



