MLLM Papers Review
视频理解
MVBench
[CVPR2024 Highlight] MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
- 提出了MVBench,一个全新的多模态视频理解基准测试,由20项单帧无法有效解决的视频任务组成,用于全面评测现有多模态模型的视频理解能力。
- 在时间任务定义的指导下,为每个任务收集和标注视频。
- 选择11个高质量视频annotation数据集,根据任务定义的约束,让GPT为视频自动生成3-5个问题并选择其一,答案设计策略分为(1)模板定义(如移动方向相关,只限制在前后左右等);(2)让GPT自己根据任务+annotation生成答案。
- GPT问答的生成设计了system prompt和answer prompt。
- 提出了更强大的基线模型VideoChat2,其不仅在MVBench上取得15个任务的领先,更在流行的视频问答、对话、推理数据集上取得有竞争力的性能。

VideoChat2渐进式跨模态训练范式
阶段1:视觉-语言对齐
- 视觉编码器:UMT-L,与BLIP2对比具有更强大的时空表示学习能力。
- QFormer:BLIP2训练的三种损失函数:视觉文本对比学习(VTC)、视觉文本匹配(VTM)和基于视觉的文本生成(VTG)
- 数据集:CC3M和CC12M的15M图像字幕,WebVid-10M的10M视频字幕。
- 目的:对齐UMT-L和QFormer,对齐图像和对应caption,压缩视觉输入。
阶段2:视觉-语言连接
- LLM:mistral/vicuna/phi
- 数据集:除了阶段1以外,进一步引入了2M图像caption(COCO、Visual Genome和SBU)和10M视频caption(InternVid)
- 目的:对齐UMT-L、QFormer和LLM,将投影的视觉标记与文本caption对齐。
阶段3:指令微调
使用本文生成的指令微调数据进行微调。在冻结的LLM上进行lora低轶微调,通过VTG损失与视觉编码器和QFormer一起调整。此外,借鉴InstructBLIP,作者在QFormer中也插入了instruction,用于提取与指令相关的视觉token作为LLM的输入。
ShareGPT4Video
[NeurIPS 2024] ShareGPT4Video: Improving Video Understanding and Generation with Better Captions
ShareGPT4Video,包含4万个GPT4V标注的密集视频字幕
- 数据过滤:将两分钟内的视频作为候选。使用Panda学生模型生成单句caption,bert编码计算相似度,选择有差异的加入候选集。
- 关键帧抽取:clip抽取帧特征,计算相似度,差异大的加入候选集。
- 字幕生成:差分滑动窗口pipeline。每次输入到图像多模态模型的内容包括当前关键帧,前一关键帧及其差分字幕。
ShareCaptioner-Video,使用收集的视频字幕数据对IXC2-4KHD 进行微调得到的任意视频标注模型,由其标注了480万个高质量美学视频。
ShareGPT4Video-8B,一个简单却卓越的LVLM,在三个前沿视频基准测试中达到了最先进(SOTA)性能。

MovieChat
[CVPR2024] MovieChat: From Dense Token to Sparse Memory for Long Video Understanding
提出了一种有效的内存管理机制,以降低计算复杂度和内存成本,同时增强长期记忆。
发布了第一个带有手动注释的长视频理解基准MovieChat-1K。

视觉特征提取:EVA-CLIP + QFormer
滑动窗口将视频分割成多个片段,每个片段包含 C 帧
短期记忆:将帧token组成的片段存储在临时固定长度缓冲区中。当固定长度的短期记忆达到其预设限制时,所有token将被弹出并合并到长期记忆中。清空并重新初始化短期存储池。(短期记忆窗口长度16)
长期记忆:对弹出的短期帧两两比较相似度,找到整个S中相似度最大的两帧,加权平均合并,不断循环直到整个短期窗口压缩到仅剩2帧。添加到长期记忆池。
由于长期记忆中存储的 token 数量可能超过预训练模型的最大长度位置编码,因此需要对位置编码进行扩展。在 MovieChat 中,采用了 BERT 的扩展位置编码方法,使得位置编码能够适应更长的长期记忆。
推理:全局模式(仅使用长期记忆),断点模式(使用长期记忆+指定的查询时间位置为止的短期记忆+指定位置帧Xi的聚合)
Video-LLaVA
北京大学的研究人员提出了一种名为Video-LLaVA的解决方案。与以往的视觉语言大模型不同,Video-LLaVA的重点在于将图片和视频特征提前绑定到一个统一的特征空间中,以便语言模型能够从统一的视觉表示中学习模态之间的交互。为了提高计算效率,Video-LLaVA采用了联合图片和视频的训练和指令微调策略。这项工作为解决”投影前对齐”(alignment before projection)的问题提供了一种方法。
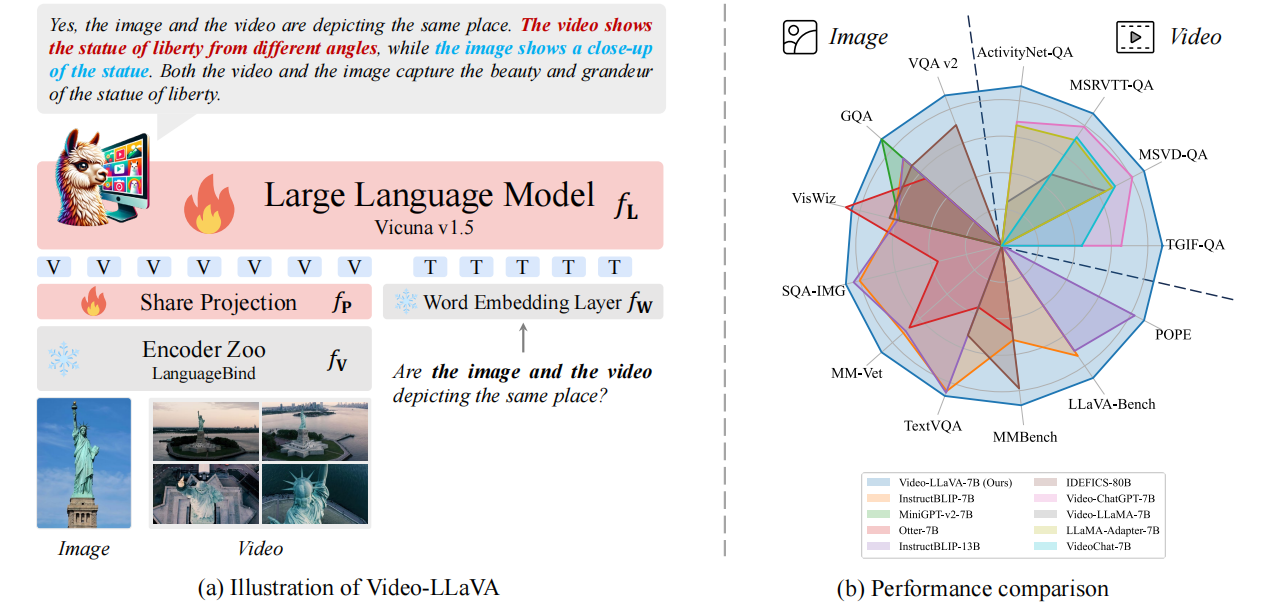
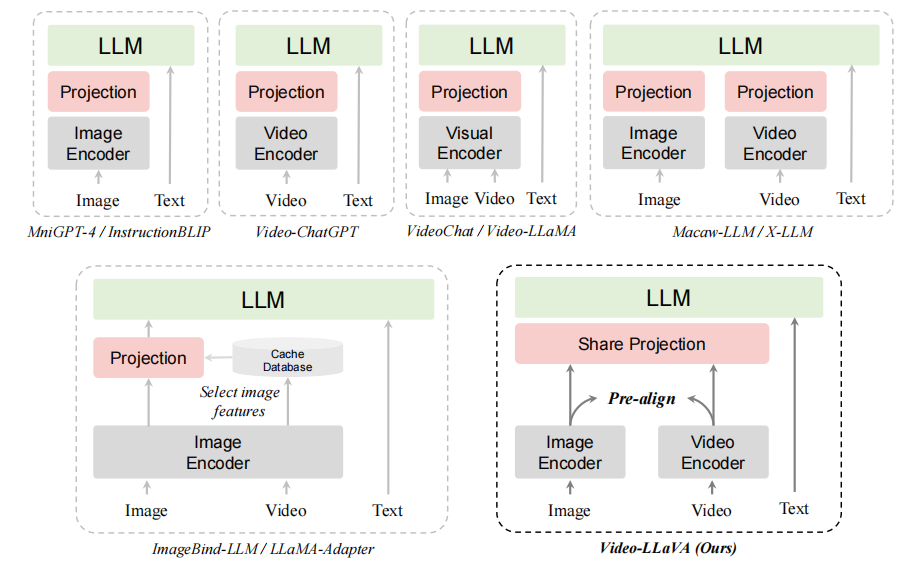
Video-LLaVA包含三个主要组件:
- LanguageBind编码器(f**V):用于从原始视觉信号(图像或视频)中提取特征
- 大型语言模型(f**L):基于Vicuna-7B
- 共享投影层(f**P):将统一的视觉表示映射到LLM输入空间
通过LanguageBind编码器,图像和视频表示被预先对齐到文本特征空间:
- 图像编码器从OpenCLIP初始化,自然与语言空间对齐
- 视频编码器使用VIDAL-10M中的300万视频-文本对进行对齐
- 共享语言特征空间使得图像和视频表示最终收敛到统一的视觉特征空间
Video-LLaVA在单个批次中同时包含图像和视频样本,这种联合训练方式使得图像和视频在统一视觉表示中相互促进,显著提升了模型性能。
Video-LLaMA
理解和解释视频内容是一项复杂的任务,不仅需要视觉和听觉信号的整合,还需要处理上下文的时间序列的能力。Video-LLaMA旨在使LLM能够理解视频中的视觉和听觉内容。论文设计了两个分支,即视觉语言分支和音频语言分支,分别将视频帧和音频信号转换为与llm文本输入兼容的查询表示。·
Video-LLaMA 的核心架构围绕 “适配 LLM 输入空间” 展开,通过两个独立分支将视频的视觉和听觉信号转化为 LLM 可理解的查询向量,整体架构如图所示:
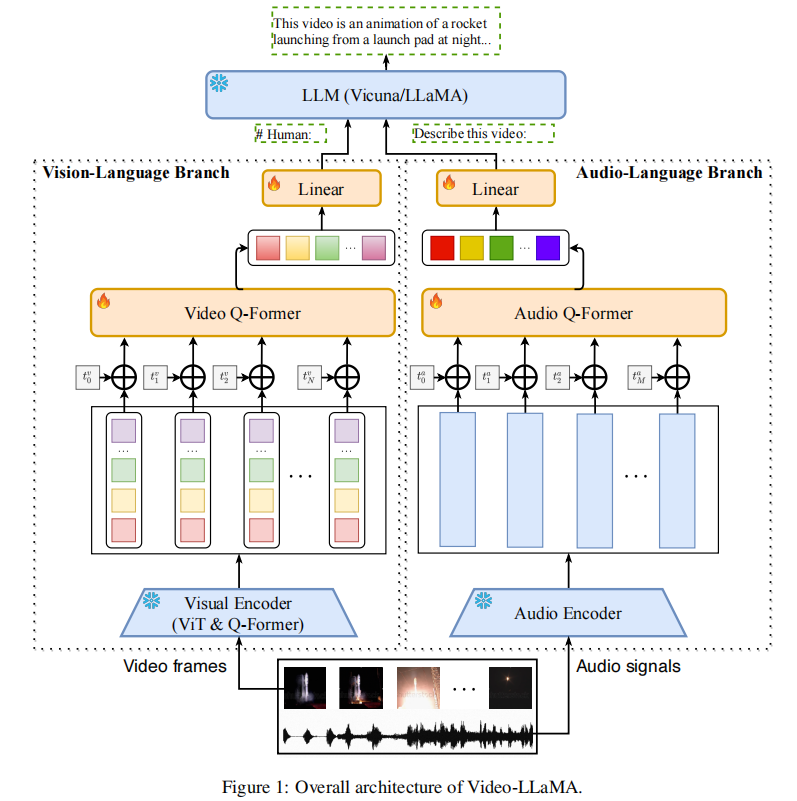
- 视觉 - 语言分支(处理视频帧信息)
核心组件:预训练图像编码器(EVA-CLIP 的 ViT-G/14)→ 帧位置嵌入层 → Video Q-Former → 线性投影层
视频帧特征提取:将视频拆分为 N 帧,用冻结的图像编码器提取每帧的视觉特征;生成视频帧的空间特征集合V=[v1,v2,…,v**N](其中v**i对应第i帧的空间特征)。
时序信息注入:通过可学习的位置嵌入层,为不同帧添加 “时间戳标识”,解决纯图像编码器无时序感知的问题;
Video-LLaMA 引入可学习的帧位置嵌入层,为每个帧特征添加 “时间戳属性”,明确帧的时序顺序。
- 技术原理:为每个帧v**i分配一个对应的时序位置嵌入向量p**i(维度与帧特征v**i一致),向量值随帧的时间顺序动态调整 —— 例如第 1 帧的p1、第 2 帧的p2在训练中学习到 “相邻帧时序相近、间隔帧时序差异大” 的特征分布。
- 融合方式:将时序位置嵌入向量*pi与对应帧的空间特征vi直接相加(即vi*′=v**i+p**i)**,使每个帧特征同时携带 “空间信息” 和 “时序信息”。
特征聚合与适配:Video Q-Former(与 BLIP-2 的 Q-Former 架构一致)聚合帧级特征,生成固定长度的视觉查询向量,再通过线性层映射到 LLM 的词嵌入空间,与文本查询拼接后输入 LLM。
- 组件架构:Video Q-Former 与 BLIP-2 的 Query Transformer 架构完全一致,包含多层 Transformer 编码器,核心是通过 “可学习查询向量(Query)” 与帧特征交互。
- 时序聚合逻辑
- 输入:携带时序信息的帧特征集合V′=[v1′,v2′,…,v**N′];
- 交互过程:Q-Former 中的 Query 向量通过自注意力机制,同时关注 “单帧内部的空间细节” 和 “相邻帧的时序关联”—— 例如在处理 “行人行走” 的视频时,Query 会重点关联连续帧中行人的位置变化特征;
- 输出:生成固定长度(k**V个)、维度为d**V的视频视觉特征V^,该特征已融合 “所有帧的空间信息” 和 “帧间的时序依赖”。
2. 音频 - 语言分支(处理视频音频信息)
- 核心组件:音频编码器(ImageBind)→ 音频段位置嵌入 → Audio Q-Former → 线性投影层
- 音频特征提取:将视频音频均匀分割为 2 秒短片段,转换为梅尔频谱图,用冻结的 ImageBind 编码器提取音频特征;
- 时序与聚合处理:通过位置嵌入标记音频片段的时间顺序,Audio Q-Former 聚合片段特征,生成固定长度的音频查询向量;
- 跨模态对齐技巧:利用 ImageBind 的 “多模态共享嵌入空间” 特性,复用视觉 - 语言分支的训练数据(视觉 - 文本对)训练音频分支,间接实现音频 - 文本对齐(无需大规模音频 - 文本数据)。
3. 基础 LLM 基座
- 基于 LLaMA/Vicuna 模型,全程冻结主体参数,仅训练双分支中的可学习组件(位置嵌入层、Q-Former、线性投影层),兼顾训练效率与生成能力。
Video-LLaMA2
VideoLLaMA 2 遵循其前一版本(即 VideoLLaMA)确立的设计原则,它整合了一个双分支框架,包括视觉 - 语言分支和音频 - 语言分支。两个分支独立运行,以模块化的方式将预训练的视觉和音频编码器连接到指令微调的大型语言模型。
- 视觉 - 语言分支:以 CLIP(ViT-L/14)为视觉编码器,用 STC 连接器替代传统 Q-Former,通过 “RegStage 空间交互 + 3D 卷积时空聚合” 处理视频帧特征。
- 音频 - 语言分支:采用 BEATs 音频编码器,将音频信号转换为频谱图后提取特征,通过 MLP 模块与语言模型维度对齐。
- 语言骨干:基于 Mistral-Instruct、Mixtral-Instruct 或 Qwen2-Instruct 等指令微调 LLM。
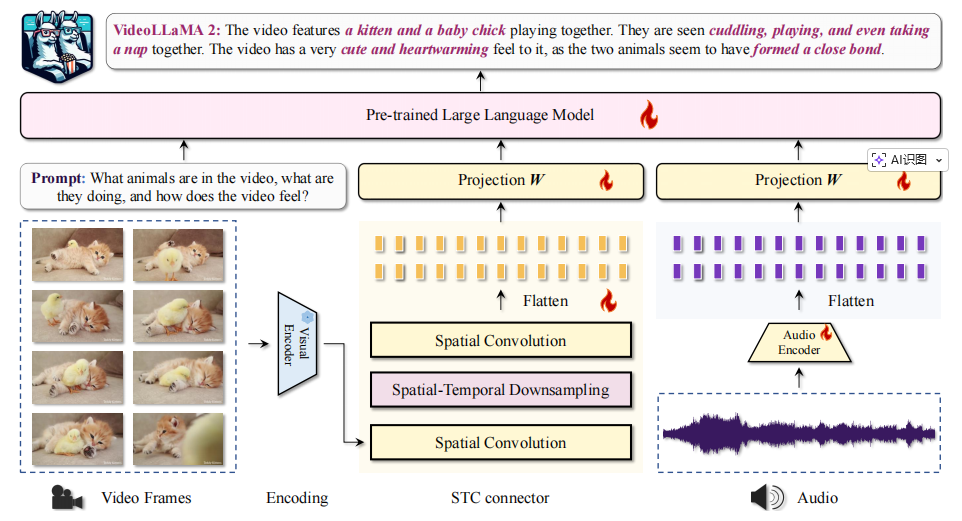
时空卷积连接器(STC Connector):高效捕捉视频时空动态
针对传统 Video-LLM 时空特征融合低效(如依赖 LLM 处理时间动态导致 tokens 冗余)、信息损失严重的问题,VideoLLaMA 2 提出定制化 STC 连接器,通过 “空间交互 + 时空聚合” 的组合设计,在减少 tokens 数量的同时,最大化保留视频的空间细节与时间连续性,核心设计遵循三大原则:
- 保留时空顺序:避免使用重采样架构(无法保证 token 顺序一致性),仅采用卷积或池化操作,适配 LLM 自回归模型对 “训练 - 推理 token 顺序一致” 的依赖;
- 压缩时空 tokens:插入 3D 下采样算子(如 3D 卷积、3D 池化),将视频帧特征的时空维度压缩,减少 LLM 处理压力,例如采用 “2,2,2” 核的 3D 卷积时,tokens 数量可从 1152 降至 576;
- 缓解信息损失:在 3D 下采样前后插入 RegStage 卷积块(一种强空间交互模块),强化局部空间细节的保留,弥补下采样导致的特征丢失。
实证表明,“RegStage+3D 卷积” 的 STC 设计在 EgoSchema、MV-Bench 等长视频理解基准上平均性能最优,且 3D 下采样方案显著优于 2D 方案,验证了帧级特征早期融合对时空建模的价值。
Video-LLaMA3
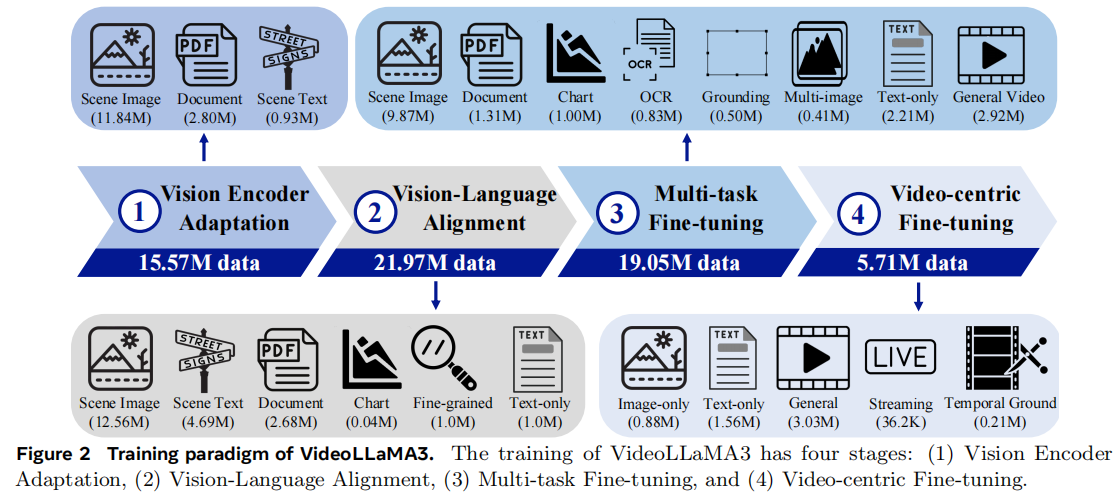
VideoLLaMA3是阿里巴巴达摩院提出的先进多模态基础模型,核心以视觉中心(vision-centric) 设计为核心,通过Any-resolution Vision Tokenization (AVT) 适配任意分辨率图像 / 视频输入、Differential Frame Pruner (DiffFP) 压缩视频冗余令牌,结合 “视觉编码器适配→视觉 - 语言对齐→多任务微调→视频中心微调” 四阶段训练范式,在700 万级高质量图像重标注数据集(VL3-Syn7M) 与多模态指令数据上训练;模型不仅在图像理解(文档 / 图表 / OCR、数学推理)和视频理解(长视频、时序定位)基准上均实现 SOTA(如 7B 模型在 VideoMME w/sub 达 70.3%、DocVQA test 达 94.9%),还兼容图像与视频跨模态任务,填补了现有模型在 “高精度图像基础 + 高效视频理解” 融合上的空白。
| 技术模块 | 核心功能 | 实现细节 | 关键优势 |
|---|---|---|---|
| Any-resolution Vision Tokenization (AVT) | 适配任意分辨率图像 / 视频输入 | 1. 替换 ViT 的绝对位置嵌入为2D-RoPE(旋转位置嵌入);2. 微调视觉编码器(SigLIP 初始化),支持动态宽高比;3. 视频输入按 “帧级 AVT” 处理,保留细节 | 1. 解决固定分辨率编码器的信息损失(如高分辨率文档、非标准视频);2. 兼容图像与视频统一令牌生成逻辑 |
| Differential Frame Pruner (DiffFP) | 压缩视频冗余令牌 | 1. 计算相邻帧像素空间的 1 - 范数距离;2. 过滤距离 < 0.1 的相似补丁(默认阈值);3. 配合 2×2 双线性插值下采样,限制令牌长度 | 1. 减少长视频计算成本(如 3 分钟视频令牌量降低 40%+);2. 聚焦视频动态内容,避免静态冗余干扰 |
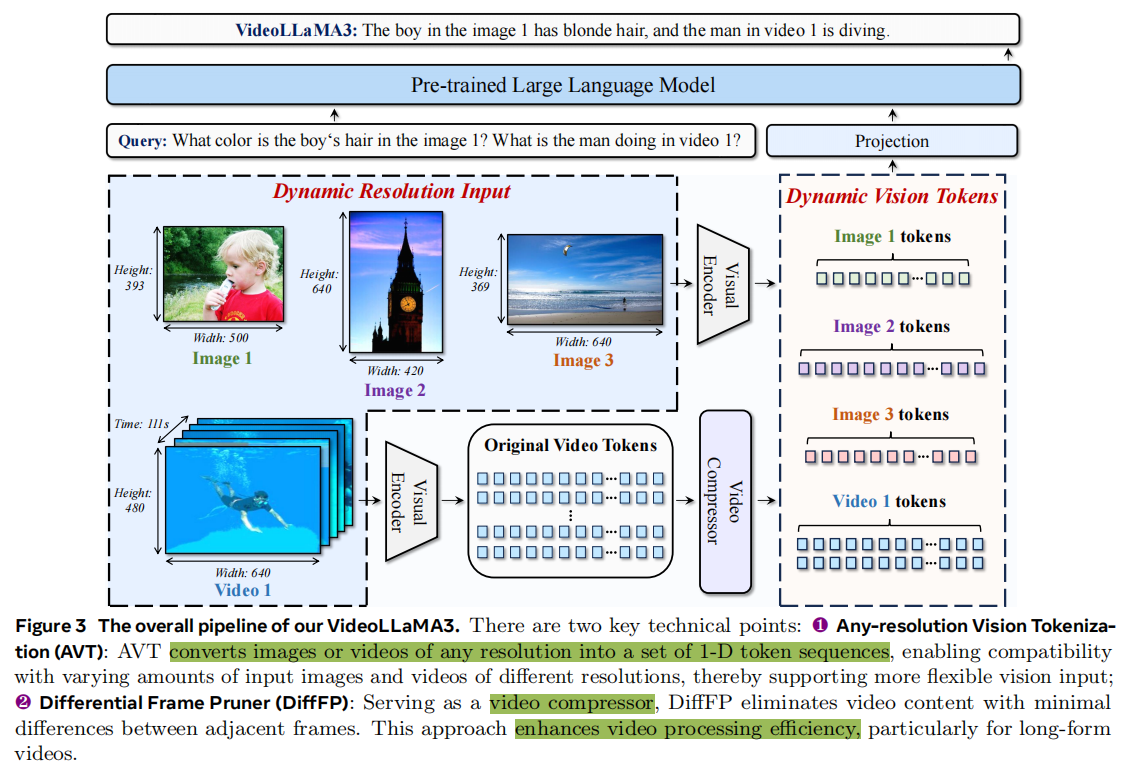
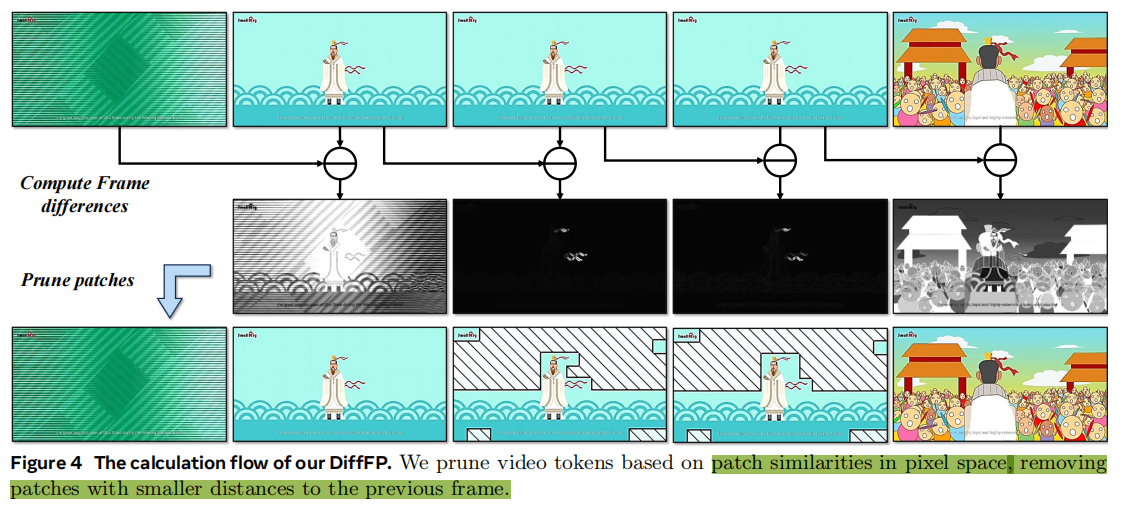
差分帧剪枝器(DiffFP):针对视频数据冗余问题,通过比较相邻帧像素空间的1-范数距离,修剪冗余视频标记,提高视频处理效率,减少计算需求。
为给 VideoLLaMA 3 提供高质量训练数据,团队构建了包含700万图像-字幕对的VL3Syn7M数据集。
- Aspect Ratio Filtering(长宽比过滤):图像长宽比可能影响模型特征提取。像一些长宽比极端的图像,过宽或过长,会使模型在处理时产生偏差。通过过滤,确保数据集中图像长宽比处于典型范围,为后续准确的特征提取奠定基础。
- Aesthetic Score Filtering(美学评分过滤):利用美学评分模型评估图像视觉质量,舍弃低评分图像。这一步能去除视觉效果差、构图不佳的图像,减少噪声干扰,保证模型学习到的图像内容和描述质量更高,进而提升模型生成优质描述的能力。
- Text-Image Similarity Calculation with Coarse Captioning(带粗略字幕的文本-图像相似度计算):先用 BLIP2 模型为图像生成初始字幕,再借助CLIP模型计算文本 - 图像相似度,剔除相似度低的图像。这一操作确保剩余图像内容与描述紧密相关,使模型学习到的图文对更具可解释性和代表性。
- Visual Feature Clustering(视觉特征聚类):运用CLIP视觉模型提取图像视觉特征,通过k-最近邻(KNN)算法聚类,从每个聚类中心选取固定数量图像。这样既保证数据集多样性,又维持语义类别的平衡分布,让模型接触到各类视觉内容,增强其泛化能力。
- Image Re - caption(图像重新标注):对过滤和聚类后的图像重新标注。简短字幕由InternVL2-8B生成,详细字幕则由InternVL2-26B完成。不同阶段训练使用不同类型字幕,满足模型多样化学习需求。
其次是各训练阶段的数据混合。在VideoLLaMA 3的不同训练阶段,数据混合策略为模型提供了丰富多样的学习场景。此外,团队使用统一的数据组织形式以统一各个阶段的训练。
通用多模态
InternVL
【LLM多模态】InternVL模型架构和训练过程-CSDN博客

视频时间定位
TimeChat
[CVPR2024] TimeChat: A Time-sensitive Multimodal Large Language Model for Long Video Understanding
一种时间敏感的MLLM,用于长视频理解和准确的时间定位。
- 两个关键架构:(1)时间戳感知帧编码器,可以将视觉内容与每个帧的时间戳绑定;(2)滑动视频 Q-Former,生成不同长度的视频token序列,以适应不同时长的视频。
指令微调数据集,涉及不同的时间戳相关的用户指令,包含 6 个任务和总共 125K 个实例。

时间戳感知帧编码器
- 视觉编码器:ViT-G/14 from EVA-CLIP。
- QFormer:对齐图像和文本标记。通过输入文本“This frame is sampled at 2s.”,把时间戳信息混合进去。压缩图像帧token。
滑动视频 Q-Former
帧编码器提取帧特征,各帧独立编码,没有建模帧间时间信息。–>引入Q-Former滑窗,在时间维度上增强特征融合。
设计了一个长度为Lw的滑动窗口,并在每个窗口内利用视频Q-Former从Lw帧中提取Nv长度的视频token。(滑窗Lw,步长S,Q-former查询向量数Nv)最终可以将输入的视频表示为(T /S)×Nv的视频token。
- 通俗来说,就是对所有独立的帧token,成组构成patch,然后对token组再做一次自注意力,把帧patch压缩到单一查询向量Nv。
然后做线性映射使tokens的特征维度符合LLM的输入特征维度需求。
指令微调
- TimeIT包含了6个与时间戳相关的视频任务,即:(1) 视频说明字幕生成,(2) 视频时间定位,(3) 步骤定位和文字生成,(4) 视频摘要,(5) 视频亮点检测,以及 (6) 转录语音生成。
VTimeLLM
[CVPR] VTimeLLM: Empower LLM to Grasp Video Moments
挑战:1. 缺少一个有精确时间范围标注的大规模的视频数据集;2. 需要设计有效的时序相关的视频任务帮助LLM理解多个时刻的内容。
方案:1:一个视觉编码器和一个视觉适配器来处理输入视频;2. 一个特制的LLM通过三阶段训练策略来同时理解文本和视频内容。

- 阶段一:视觉特征通过图片-文本对训练与LLM在语义空间对齐。
- 视觉编码器:CLIP ViT-L/14。每一帧有cls token的feature和每个patch的feature,直接采用cls token的作为图片特征。
- 视觉适配器:一个线性层,对每一帧的v_cls做变换,映射到LLM空间,最后视频由N*d的特征Z代表(N为帧数,d为LLM的隐层维度),这里均匀采样100帧。
- 阶段二:设计了单论(single-turn)和多轮(multi-turn)的QA任务来使得模型能够感知到时间边界并理解时间边界内事件内容。
- 数据:InternVid-10M-FLT数据集,自动化对视频进行分割和标注。每个视频都包含多个事件及其粗略的时间注释和描述。
- 单轮QA(20%)是密集Video Caption,多轮QA(80%)包括片段描述&时序grounding任务。
- 作用:让模型具有时序感知的能力,可以定位视频的segmentation。
- 训练:只训练LLM的LoRA,别的组件冻住,Prompt里告诉LLM有一百帧。
- 阶段三:创造了一个高质量的对话数据集来指令微调。
TRACE
TRACE 方法引入了结构化建模创新:把视频理解大模型的输出拆解成「时间戳 - 显著性分数 - 文本描述」三元事件单元,实现因果事件建模 —— 通过视觉输入、文本指令和已有事件预测下一个事件

UniVTG
Video Temporal Grounding(VTG)任务目标是根据文本输入(query),在视频中检索一个或多个与文本相对应的片段。根据检索得到的片段长度及标签粒度不同,过往的VTG任务可以分为Moment Retrieval、Highlight Detection和Video Summarization三类。
- MR旨在通过文本查询定位视频中符合的片段;
- HD旨在给视频各部分打分,越符合视频主题的分数越高;
- VS旨在根据或者不根据文本,来得到视频中多个时间点,这些时间点的片段组合在一起能够较好总结视频内容。
本文实现首个预训练VTG模型UniVTG,将不同层次的VTG任务标注及模型结构相统一,以增强模型在不同粒度的VTG任务上的泛化能力。

- 从任务和标签的角度,定义了一种统一的范式。将视频分解为多个等长clips序列,每个clip分配3种基础的标签。从而能够进行统一的预训练。
- foreground indicator(Point-Level):0/1二值标签,假如是前景则为1,反之为0。
- boundary offsets(Interval-Level):二维向量,将特定帧clip的时间戳转换到时间边界。**[a,b]对应当前点距离时间段边界的距离。a为距离起始点的距离,b为距离终止点的距离。**
- saliency score(Curve-Level):是一个[0,1]的连续值,表示当前clip与查询Q的相关性。
- 数据收集方面,将帧视为视频的原子组成,VTG任务收集目标clip集合。
- 使用CLIP构建具备Curve-Level标注能力的CLIP Teacher。CLIP Teacher标注根据以下步骤构造:(1)利用CLIP编码帧特征,计算预设语料库concept池文本特征与视频间相似度;(2)选取top-5 concept作为query,对应相似度曲线作为saliency score;(3)将相似度以0.05的间隔进行离散化,并取最大值作为interval。有了interval就能相应生成point。
- 从模型的角度,提出了一个统一的框架。
- Cross-modal alignment路径用于输出saliency score,由于saliency代表query和视频之间的相关程度,模型在对query进行注意力池化得到句特征后,直接计算句-视频特征间相似度作为saliency score。该路径采用对比学习损失优化编码过程:同视频内,负样例为相对于正样例clip具有更低saliency的clip;不同视频,负样例为其他视频的query。
- Cross-modal interaction路径用于输出foreground indicator和boundary offsets,其利用注意力建模连接后的query-视频特征,输入卷积层进行预测,损失为分类(indicator)及重叠区间(offsets)损失。
- 从预训练的角度,利用统一任务和统一框架,进行了大规模的预训练。

TFVTG
(ECCV2024)Training-free Video Temporal Grounding using Large-scale Pre-trained Models
大多数现有的vlm都是通过图像-文本对或视频剪辑-文本对进行训练的,在这种训练范式中,模型的主要目标是将最具区别性的视觉线索与其相应的文本描述联系起来。这使得它很难做到:
- 理解同一视频中多个事件的关系,区分时间界限;
- 对视频中事件的变换敏感(从一个事件到另一个事件的动态转变)。
本文方案:
- 基于prompt让LLM将原始查询分成若干子事件,并分析这些事件之间的时间顺序和关系。
- 推理子事件,确定顺序及关系,为事件提供描述。
- 将一个子事件分为动态过渡和静态状态部分,并提出了使用VLM的动态和静态评分函数,以更好地评估事件和描述之间的相关性。
- 对于动态部分,测量相似度变化率;对于静态部分,测量内部和外部的比较相似度。
- 对于LLM提供的子事件描述,利用VLM定位最相关的k个proposal。若子事件同时发生,取定位结果交集;若顺序发生,则取并集,得到最终预测。

选用 BLIP - 2 Q - Former 作为 VLM 定位器。计算文本与视觉特征的余弦相似度来衡量子事件描述与视频帧的相关性
- 动态评分:考虑到视频的连续性,在目标片段的动态部分,视频内容从一个事件过渡到查询所描述的目标事件,视频帧与查询的相关性应快速提升。其特征是在静态段内具有较高的平均视频文本相似性,同时在其之外保持较低的平均相似性。
- 为消除视频抖动影响,先对相似度S应用高斯滤波$\S: \hat S = G(S)$ 再计算相似度差值。$\hat S: D_i = \hat S_i − \hat S_{i-1}$
对于从第i帧开始到第k帧结束的proposal,当其中所有的差值超过特定阈值时,将该proposal内的差值求和得到动态分数。- 也就是先高斯滤波平滑一下余弦相似度,再找相似度变化陡峭的位置判定其可能是事件转换的开端。(可靠性存疑
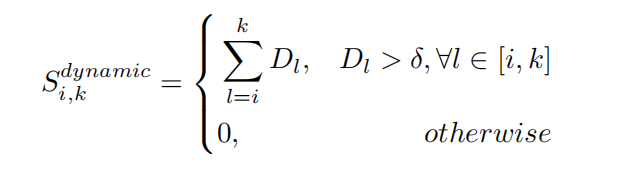
- 静态评分:受 SPL 启发,在静态部分,要求给定查询的最相关事件需满足事件内视频与查询相关性高,事件外相关性低。对于从第k帧开始到第j帧结束的proposal,通过计算proposal内平均相似度与proposal外平均相似度的差值作为静态分数。

- 定位结果选取:对于每个proposal (i, j),考虑到不同事件过渡段长度不一,枚举所有可能的过渡结束时间戳k,将proposal划分为动态部分(i, k)和静态部分(k, j),计算动态分数与静态分数之和,并选取最大值作为该proposal的分数。最终,选取分数最高的top-k个proposal作为 VLM 定位器的定位结果。
预测过滤与整合:
- 枚举预测组合:VLM 定位器针对每个子事件描述返回前 k 个预测结果。假设有 m 个子事件,通过枚举每个子事件的一个预测结果,总共会产生$k^m$种组合。
- 顺序约束过滤:依据 LLM 分析得到的子事件发生顺序,对上述组合进行过滤。若 LLM 判断子事件Pi应在Pj之前发生,但在某组合中Pi的开始时间晚于Pj的结束时间,则该组合不符合顺序逻辑,将被舍弃。
- 分数计算与结果整合:过滤后,计算每个组合的总分,该分数为 VLM 定位器为该组合中各子事件预测返回的最终分数之和。然后,选取总分最高的组合。对于子事件关系,若 LLM 判定子事件同时发生,将该组合中各子事件的预测取交集作为最终预测;若子事件顺序发生,则取并集作为最终预测。
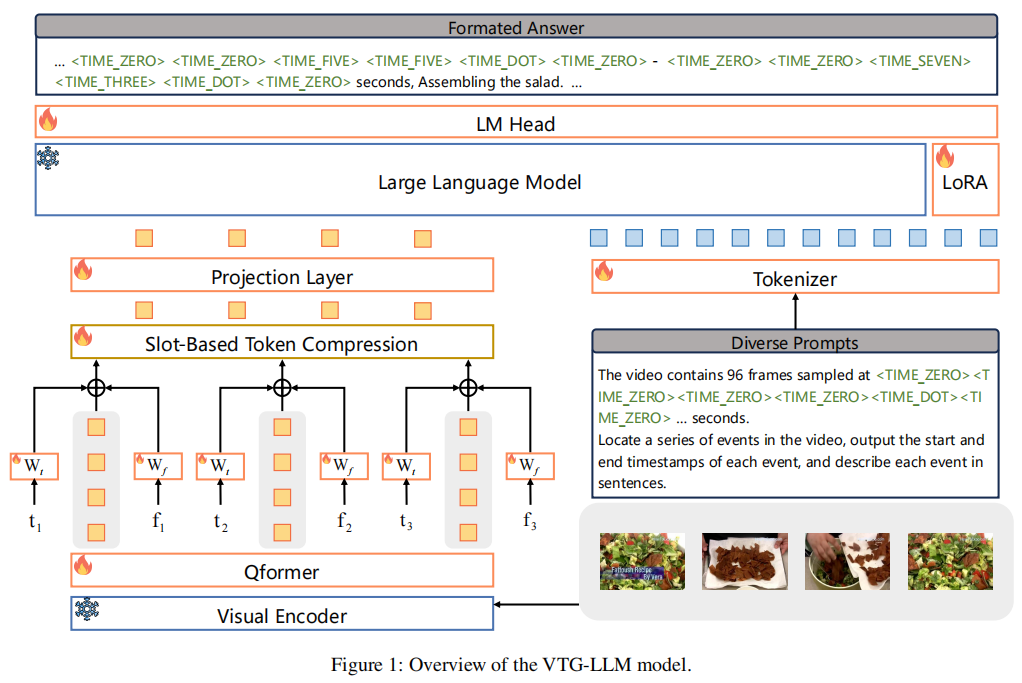
VTG-LLM
痛点:
- 视觉 token 缺乏准确时间戳信息:仅依赖帧序列隐含时序(相对时间),无法建模绝对时间戳(如 “事件发生在第 25-30 秒”),导致时序定位精度低;
- 时间数字存在 “概念偏移”:时间相关数字(如 “20 秒”)与普通计数数字(如 “20 个人”)共享词嵌入,模型难以区分语义边界,影响时间理解;
- VTG 任务需多帧但 LLM 上下文有限:时序定位需要采样更多帧才能覆盖关键事件,但 LLM 上下文长度固定,传统令牌压缩会丢失关键信息。
本文方案:
- 序列 - 时间嵌入(Sequence-Time Embedding):绑定绝对时间与视觉特征,采用 “相对序列嵌入 + 绝对时间嵌入” 双嵌入机制
- 绝对时间令牌(Absolute-Time Tokens):在 LLM 分词器中新增 11 个专用时间令牌,0-9 数字令牌(
<<t_0>-<<t_9>)+ 小数点令牌(<<t_dot>) - 槽位基令牌压缩(Slot-Based Token Compression):引入可训练的 “槽位分配器”(Φ∈RK×d,K 为槽位数量),通过注意力权重将 N 个视觉 token 动态分配到 K 个槽位中,每个槽位是 token 的加权融合
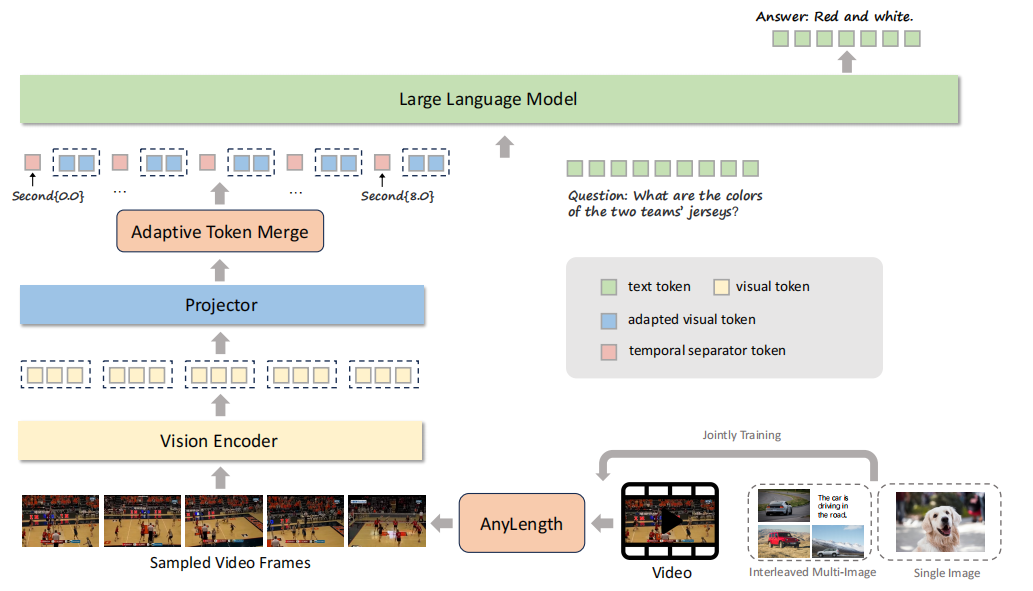
TimeMarker
视频理解痛点:
- 缺乏精确时序定位能力:现有模型多关注相对事件顺序(如 “先 A 后 B”),无法准确建模绝对时间戳(如 “事件发生在第 4-6 秒”),导致时间相关任务(如事件定位、时序问答)性能不佳;
- 难以适配多样化视频长度:短则几秒、长则数小时的视频会导致视觉 token 数量急剧膨胀,现有固定帧采样(适配短视频)或简单压缩(适配长视频)的方法,要么丢失长视频关键信息,要么牺牲短视频细节。
本文方案:
- 时间分隔符token:在将视频帧的视觉特征输入LLM时,会在其特征序列前显式地插入一个文本令牌,例如
Second{2.0}。输入LLM的序列格式变为:"Second{2.0} || 视觉特征V1 || Second{4.5} || 视觉特征V2 ..."。 - AnyLength 机制:****动态帧采样 + 自适应令牌合并。先根据 LLM 上下文长度和 GPU 显存,设定最大采样帧数,按视频时长(dur)动态调整采样帧率(sample_fps)。对每个帧的视觉令牌特征图(h×w×d),通过平均池化压缩令牌数量。
- 多样化数据集: 不仅使用传统的视频描述和问答数据,还将时序动作定位、视频摘要等任务的标注数据,转化为时序相关的问答形式,专门强化模型的时间推理能力。
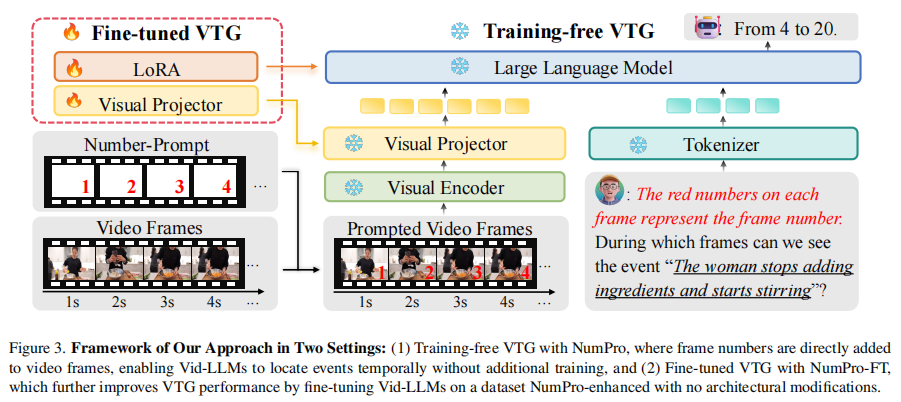
Number it
思路:为视频的每一帧画面都标上唯一的序号。这样,视频大模型在理解视频内容的同时,就能像我们读漫画一样,直接“看到”每一帧对应的时间位置,从而轻松地将事件与具体的时间点关联起来。
- 无需训练的模式:在推理阶段,直接将帧序号(如“1, 2, 3…”)以红色文字叠加在视频每一帧的右下角。同时,在给模型的文本指令中明确说明:“每帧上的红色数字代表帧序号”。模型凭借其内置的光学字符识别能力,就能识别这些数字并输出准确的时间区间。
- 微调模式:构建一个包含22万条样本的指令微调数据集,其中所有视频帧都预先用NumPro处理。问题格式统一为“在哪些帧中我们可以看到{事件描述}?”,答案格式为“从x帧到y帧”。在此基础上对模型进行微调,
- 使其将数字与时间的关联内化到参数中,从而获得更强的时序定位能力。
通过在海量图片数据集上的测试,最终确定了最优配置:字体大小40、红色、位于画面右下角。这一配置在数字识别准确率和内容理解准确率之间取得了最佳平衡。
视频异常检测
Holmes-VAD
LAVAD
数据集
Surveillance DB
Towards Surveillance Video-and-Language Understanding: New Dataset, Baselines, and Challenges
监控视频对公共安全至关重要,但现有监控视频任务局限于预定义异常事件的检测与分类,缺乏语义理解能力。多模态视频数据集虽有发展,但面向监控视频的多模态学习研究不足,原因在于现有监控数据集缺少句子级语言注释,且监控视频特性增加学习难度。为此,文章提出拓展现有监控视频数据集至多模态场景,构建了 UCA 数据集。

提出了监控视频与语言理解(VALU)这一新的研究方向,并构建了首个多模态监控视频数据集。
- 新标注的数据集UCA(UCF-Crime注释)包含23,542个句子,平均长度为20个单词,标注的视频长达110.7小时。
- 包含细粒度的注释和事件描述;包含事件的时间戳和活动的描述。
- UCA可以支持多种多模态理解任务,如时间定位(TSGV),视频字幕(VC),密集视频字幕生成(DVC),多模态异常检测(MAD)。
在数据集上对四个多模态任务的前沿模型进行了基准测试,这些结果为监控 VALU 提供了新的基线。
在MAD实验中提供基本的监控视频字幕模型作为即插即用模块。结果表明,多模态监控学习可以提高异常检测的性能。
数据集构造:从 UCF - Crime 中过滤低质量视频,得到 1854 个视频组成 UCA。标注时详细描述事件并记录起止时间,标注间隔 0.1 秒。完成 23542 条句子级标注。UCA 按视频长度和原始类别分为训练、验证和测试集,涵盖 13 种异常。标注视频总时长 110.7 小时,事件时长多在 5 - 10 秒,平均视频时长 236.8 秒,平均事件标注时长 16.9 秒。平均注释词数约 20 个,名词、动词、形容词比例约为 2:2:1。
视频监控相关
参考
【CVPR论文复现】VTimeLLM: Empower LLM to Grasp Video Moments-CSDN博客
论文笔记 UniVTG:Towards Unified Video-Language Temporal Grounding - Kamino’s Blog



