MLLM Dataset&Code
数据集
CC3M
图像caption数据集(共 3318333 张图像),每张图配一个单句字幕。
huggingface已处理的版本(pixparse/cc3m-wds at main),使用:
from datasets import load_dataset
ds = load_dataset("pixparse/cc3m-wds")自行处理的版本(原始tsv文件:Conceptual Captions)
先为tsv添加列名sed -i '1s/^/caption\turl\n/' cc3m.tsv
然后解析,脚本(img2dataset/dataset_examples/cc3m.md at main · rom1504/img2dataset)
img2dataset --url_list cc3m.tsv --input_format "tsv"\
--url_col "url" --caption_col "caption" --output_format webdataset\
--output_folder cc3m --processes_count 16 --thread_count 64 --image_size 256\
--enable_wandb Truecaption格式:
{
"caption": "hard rock artist of hard rock artist performs",
"url": "https://media.gettyimages.com/photos/lead-singer-steve-perry-of-rock-band-journey-performs-at-the-rosemont-picture-id832243484?s=612x612",
"key": "000000001",
"status": "success",
"error_message": null,
"width": 415,
"height": 612,
"exif": "{\"Image ImageDescription\": \"Lead singer Steve Perry of rock band Journey performs at the Rosemont Horizon in Rosemont, Illinois, June 10, 1983. (Photo by Paul Natkin/Getty Images)\", \"Image Copyright\": \"2017 Paul Natkin\"}",
"original_width": 415,
"original_height": 612
}数据集目前放在Ask-Anything/video_chat2/annotation/videos_images/cc3m路径下。
WebVid-10M
视频caption,缺点是有水印。论文使用基本都会做预处理。
CSV文件:
- huggingface:TempoFunk/webvid-10M · Datasets at Hugging Face
- HyperAI:WebVid 大型短视频数据集 / 数据集 / HyperAI超神经 | HyperAI超神经
视频数据下载(很多因为网络问题下不下来):video2dataset/dataset_examples/WebVid.md at main · iejMac/video2dataset
#!/bin/bash
wget -nc http://www.robots.ox.ac.uk/~maxbain/webvid/results_10M_train.csv
video2dataset --url_list="results_10M_train.csv" \
--input_format="csv" \
--output-format="webdataset" \
--output_folder="dataset" \
--url_col="contentUrl" \
--caption_col="name" \
--save_additional_columns='[videoid,page_idx,page_dir,duration]' \
--enable_wandb=True \
--config="path/to/config.yaml" \caption格式:
{
"videoid": 1051729318,
"page_dir": "095551_095600",
"duration": "PT00H00M09S",
"caption": "Mount saint helens, washington - the stunning scenery of a rocky mountains during golden hours - wide shot",
"url": "https://ak.picdn.net/shutterstock/videos/1051729318/preview/stock-footage-mount-saint-helens-washington-the-stunning-scenery-of-a-rocky-mountains-during-golden-hours.mp4",
"key": "00000034",
"status": "success",
"error_message": null,
"yt_meta_dict": null
}MSR-VTT
MSR-VTT是一个通用的视频字幕数据集,包括10000个视频片段,每个视频剪辑持续约15秒。标准情况下通常使用6153个片段进行训练,497个片段用于验证,2090个片段用于测试。(压缩包6g)
数据集:CARE/README_DATA.md at master · yangbang18/CARE
下载: NeurIPS 2022 Spotlight] Expectation-Maximization Contrastive Learning for Compact Video-and-Language Representations(这个版本提供了csv,但标注json是category不是caption,服务器的caption忘了从哪下载的了)
caption格式:
{"video": "video9770.mp4", "caption": "a person is connecting something to system", "duration": 10.8}, {"video": "video9771.mp4", "caption": "a little girl does gymnastics", "duration": 13.78}COCO
- COCO数据集包含20万个图像;
- 80个类别中有超过50万个目标标注,它是最广泛公开的目标检测数据库;
下载:COCO数据集的下载、介绍及如何使用(数据载入及数据增广,含代码)_coco数据集下载-CSDN博客
数据路径:D:\东南\智慧城市\数据集
标注数据格式:
{"info": {"description": "COCO 2017 Dataset","url": "http://cocodataset.org","version": "1.0","year": 2017,"contributor": "COCO Consortium","date_created": "2017/09/01"},"licenses": [{"url": "http://creativecommons.org/licenses/by-nc-sa/2.0/","id": 1,"name": "Attribution-NonCommercial-ShareAlike License"},{"url": "http://creativecommons.org/licenses/by-nc/2.0/","id": 2,"name": "Attribution-NonCommercial License"},…………],
"images": [{"license": 3,"file_name": "000000391895.jpg","coco_url": "http://images.cocodataset.org/train2017/000000391895.jpg","height": 360,"width": 640,"date_captured": "2013-11-14 11:18:45","flickr_url": "http://farm9.staticflickr.com/8186/8119368305_4e622c8349_z.jpg","id": 391895},{"license": 4,"file_name": "000000522418.jpg","coco_url": "http://images.cocodataset.org/train2017/000000522418.jpg","height": 480,"width": 640,"date_captured": "2013-11-14 11:38:44","flickr_url": "http://farm1.staticflickr.com/1/127244861_ab0c0381e7_z.jpg","id": 522418},…………],
"annotations": [{"image_id": 203564,"id": 37,"caption": "A bicycle replica with a clock as the front wheel."},{"image_id": 322141,"id": 49,"caption": "A room with blue walls and a white sink and door."},{"image_id": 16977,"id": 89,"caption": "A car that seems to be parked illegally behind a legally parked car"},…………]InternVID
github:InternVideo/Data/InternVid/README_CN.md at main · OpenGVLab/InternVideo
数据路径:数据集-OpenDataLab
InternVid是一个大规模的以视频为中心的多模态数据集,可用于学习强大且可迁移的视频-文本表示,用于多模态理解和生成。InternVid数据集包含超过700万个视频,总时长近76万小时,共有2.34亿个视频片段,伴随着总计41亿个单词的详细描述。
作为本次发布的一部分,我们提供了数据集的一个子集InternVid-10M-FLT,包含1000万个视频片段。相关视频对应的Youtube ID和对应的文本描述详见caption.jsonl,对应的处理后的视频片段下载详见链接,另外还包括了使用UMT计算对应视频片段和文本的相关度UMT-SIM(已归一化*)和美学评分Aesthetic_Score(使用LAION美学评估模型),其对应的示例如下:
{"YoutubeID": "HdYoyzCSWyw", "Start_timestamp": "00:03:10.567", "End_timestamp": "00:03:11.200", "Caption": "woman using a computer mouse and keyboard", "Aesthetic_Score": 4.58984375, "UMT_Score": 0.39794921875}
{"YoutubeID": "qJrOyggIB-w", "Start_timestamp": "00:07:33.689", "End_timestamp": "00:07:51.085", "Caption": "a screen shot of heroes of the storm with people in action", "Aesthetic_Score": 4.29296875, "UMT_Score": 0.4501953125}
{"YoutubeID": "pDq9UzfCtGw", "Start_timestamp": "00:08:14.520", "End_timestamp": "00:08:37.120", "Caption": "in october, 2019, in lviv, there was a conference about the legal information technology", "Aesthetic_Score": 4.28515625, "UMT_Score": 0.375732421875}注意:之前发布的UMT-SIM实际由OpenAI的CLIP-L计算得到。
pytube数据集下载:InternVid数据集的下载指南-CSDN博客
403 forbidden:it showing streaming data error · Issue #1570 · pytube/pytube

400 bad request:python - How to solve HTTP Error 400: Bad Request in PyTube? - Stack Overflow

InternLM-XComposer2-4KHD
IXC2-4KHD结构
- 视觉编码器:OpenAI CLIP ViT-L-14-336, 添加动态分辨率方案
- projector 层:MLP
- LLM :为最新的 InternLM2
- 预训练:训练Vit,MLP投影和LLM;
- 微调:Partial LoRA (P-LoRA)
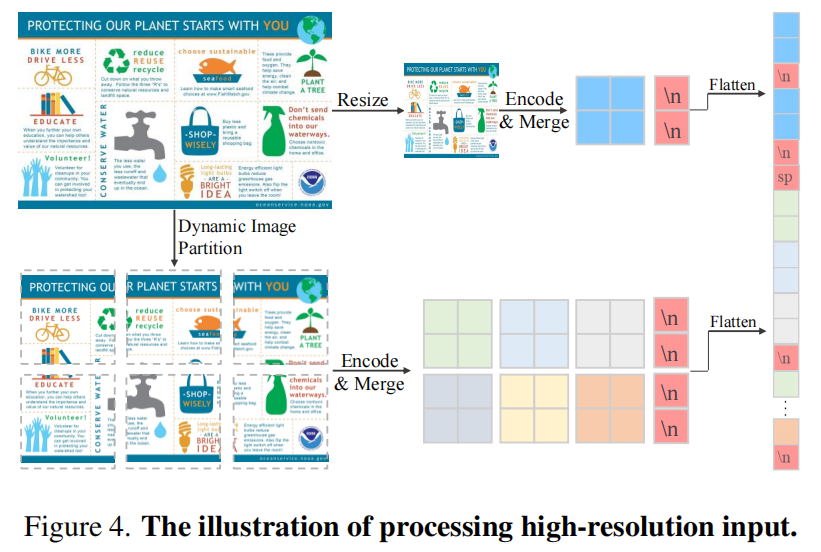
和 llava next 一样,模型输入包括两个视图,具体做法为:
- 对于给定的任意一张图片,训练时候需要指定这张图片希望切分为最多为多少个 patch,例如论文说的 HD-9,HD-25 和 HD-55,HD-9 也就是说经过处理后这张图片,这种图片最多(可以少)可以切分为 9 个 patch,假设正好可以切分为 9 个 patch,那么可能输出分辨率为 1008×1008, 672×1344, 336×3024,至于到底选择的是那个分辨率则是依据图片宽高比来确定的,算法的目标是在接近 9 个 patch 情况下,图片后续 padding 的像素最少即可
- 假设算出来是 672×1344,那么图片会在先进行保持宽高比情况下 resize,然后 padding 为 672×1344(下面函数到这里为止)
- 上述就得到高分辨率图了,将这个 672×1344 图片直接强制 resize 为 336x336 就得到了全局视图
- 为了让模型更容易理解 patch,如上所示,作者在每一行后面加一个可学习的 \n 特殊 token,并且也加了一个可学习的 sp 特殊 token
- 由于在 HD 输入下,token 非常多,直接训练肯定会炸了,例如 HD-55,此时的 patch 一共 55+1=56 个,每个 patch 输出 576 个 token,那么就有 32256 个 image token,这就有点夸张了。所以作者简单的进行 token merge了,就是相邻的 4 个 token 合并,将信息转换到通道维度了,此时最多的 Image token 是 8064 了,虽然也很多,但是至少看起来还行。
def HD_transform(img, hd_num=9): # hd_num 期望切分的最大patch数
width, height = img.size
if width < height:
width, height = img.size
ratio = (width / height)
print(ratio)
# 假设某条边扩展为 n 个 patch,此时可以得到在宽高比不变情况下另一条边最多可以扩展为 n/ratio 个 patch
# 如果总的 patch 数 (scale*np.ceil(scale/ratio) )接近 hd_num 但是不超过 hd_num,那么就选择这个
scale = 1 # scale计算某条边扩展到多少patch数
while scale*np.ceil(scale/ratio) <= hd_num:
scale += 1
scale -= 1
new_w = int(scale * 336) # 每个patch 336*336
new_h = int(new_w / ratio)
img = transforms.functional.resize(img, [new_h, new_w],)
# 确保能够被 336 整除,周围padding填充
img = padding_336(img)
return imgVideoChat2
配置记录
pycharm映射
依赖版本
cuda-runtime 12.1.0 0 nvidia
cuda-version 12.4 hbda6634_3 http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
ffmpeg 6.1.1 h4c62175_0 http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
ffmpeg-python 0.2.0 pypi_0 pypi
fontconfig 2.14.1 h4c34cd2_2 http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
freetype 2.12.1 h4a9f257_0 http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
numpy 1.23.5 py39hf6e8229_1 http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
numpy-base 1.23.5 py39h060ed82_1 http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
pandas 2.0.3 py39h1128e8f_0 http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
peft 0.4.0 pypi_0 pypi
pillow 10.0.0 pypi_0 pypi
pip 24.2 py39h06a4308_0 http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
python 3.9.20 he870216_1 http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
pytorch-cuda 12.1 ha16c6d3_6 pytorch
scipy 1.13.0 pypi_0 pypi
sentencepiece 0.1.99 pypi_0 pypi
tokenizers 0.15.2 pypi_0 pypi
torch 1.13.1+cu117 pypi_0 pypi
torchaudio 0.13.1+cu117 pypi_0 pypi
torchvision 0.14.1+cu117 pypi_0 pypi
tqdm 4.66.1 pyhd8ed1ab_0 http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
transformers 4.37.1 pypi_0 pypi
urllib3 2.2.3 py39h06a4308_0 http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
wandb 0.16.6 pyhd8ed1ab_1 http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
wheel 0.44.0 py39h06a4308_0 http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
参考
CC3M数据集:pixparse/cc3m-wds at main
WebVid数据集:TempoFunk/webvid-10M · Datasets at Hugging Face
MSR-VTT数据集:准备 MSR-VTT 检索/视频问答数据集 — MMAction2 1.2.0 文档
对应google云:MSRVTT - Google Drive
这个版本不是服务器用的版本,标注json只有category没有caption
COCO数据集:Dataset之COCO数据集:COCO数据集的简介、下载、使用方法之详细攻略-CSDN博客
InternVID数据集:数据集-OpenDataLab
Video-LLaVA训练:Video-LLaVA/TRAIN_AND_VALIDATE.md at main · PKU-YuanGroup/Video-LLaVA
IXC2-4KHD:MLLM-算法推荐-2024.4.12] InternLM-XComposer2-4KHD 处理高分辨率有一手 - 知乎
pycharm连接服务器(核心是deployment ssh配置+mapping填对):Pycharm远程连接服务器进行代码的运行与调试_remote sdk is saved in idesetting-CSDN博客



