ShareGPT4Video
摘要
论文推出了ShareGPT4Video系列,旨在通过密集且精确的标注促进大型视频语言模型(large video-language models, LVLMs)的视频理解和文本到视频模型(text-to-video models, T2VMs)的视频生成。该系列包括:
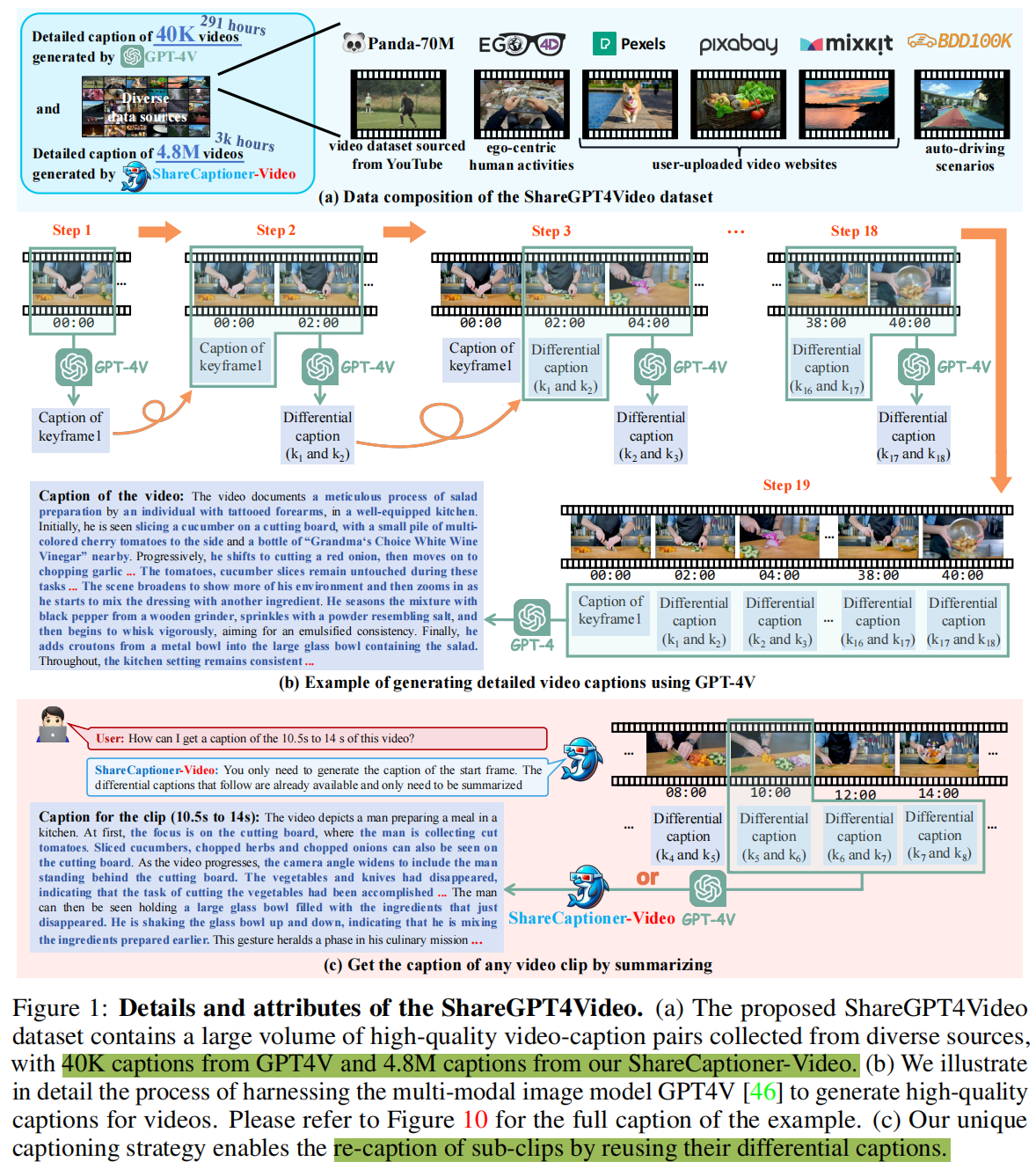
1)ShareGPT4Video,包含4万个GPT4V标注的密集视频字幕,这些视频具有不同长度和来源,通过精心设计的数据过滤和标注策略开发。
2)ShareCaptioner-Video,一个高效且能力强大的任意视频标注模型,由其标注了480万个高质量美学视频。
3)ShareGPT4Video-8B,一个简单却卓越的LVLM,在三个前沿视频基准测试中达到了最先进(SOTA)性能。
为了达成上述目标,不考虑不可扩展且成本高昂的人工标注,作者发现使用GPT4V对视频进行标注,采用简单的多帧或帧连接输入策略,会导致细节不足,生成的字幕不够详细且会出现时间混淆的结果。针对这一问题,作者认为设计高质量视频标注策略的挑战在于三个方面:1) 帧间精确的时间变化识别。2) 帧内详细内容描述。3) 任意长度视频的帧数可扩展性。
为此,论文精心设计了一种差分视频标注策略,该策略稳定、可扩展且高效,适用于生成任意分辨率、宽高比和长度的视频标注。基于此,论文构建了ShareGPT4Video,包含4万个高质量视频,涵盖广泛类别,其标注涵盖丰富的世界知识、物体属性、摄像机运动,以及关键的、详细且精确的事件时间描述。基于ShareGPT4Video,论文进一步开发了ShareCaptioner-Video,一个能够高效生成任意视频高质量标注的优秀标注器。本文通过它标注了480万个具有美学吸引力的视频,并在10秒文本到视频生成任务中验证了其有效性。对于视频理解,论文验证了ShareGPT4Video在几种当前LVLM架构上的有效性,并展示了论文卓越的新大型视频语言模型 ShareGPT4Video-8B。
引言
LLM的驱动下,多模态学习中图文对话(image-text dialogue)和文生图任务(text-to-image generation tasks)已经取得了最新进展。这也激发了向视频理解和生成任务的转变,允许用户跨视频和语言模式的交互。因此,详细和高保真的视频字幕,连接上述模态,有助于推动该领域的进展。
尽管视频内容具有丰富的语义和时间信息,但现有数据中视频通常只配有简短的描述。这些简短的描述限制了对视频的深入理解以及视频生成的可控性。虽然图像-文本对话和文本到图像生成任务中已认识到详细描述的重要性,但在视频理解和生成方面类似的努力仍然不足。
然而,创建大规模、高质量的视频描述是一项挑战性任务。即使是人类,为长视频生成详细的描述也是复杂且耗时的,这阻碍了大规模的标注工作。当前的开源大规模视觉语言模型(LVLMs)缺乏这种能力,而闭源API尚不支持视频输入。
另一方面,如果将视频输入简化为多个帧,即使是GPT4V也难以提供满意质量的描述。例如,一个直观的想法是向GPT4V提供带有时间戳的多帧视频,并生成描述,但论文发现GPT4V在描述时表现不稳定,有时会误解帧之间的时间关系,且随着视频帧数的增加,其性能进一步下降。其他解决方案,如将所有帧拼接成一张大图,对于解决时间问题并无帮助,且随着帧数的增加,描述的细节会丢失。论文在图11-12中展示了这些问题。
论文认为,制定有效的视频描述策略的挑战源于三个基本方面:1) 帧间精确的时间变化理解:时间维度将视频与图像区分开来。不精确的时间描述会显著降低视频描述的质量,并在训练模型时引起混淆。2) 帧内详细内容的描述:详细描述对于图像与文本模态之间的对齐至关重要,对于视频-文本对齐也同样重要。3) 任意长度视频的帧数可扩展性:在实际应用中,视频的长度差异很大。理想的描述策略应能适应这种变化,并为任何长度的视频生成适当的描述。
为此,论文提出了差分滑动窗口标注策略 Differential Sliding-Window Captioning strategy (DiffSW),该策略稳定、可扩展且高效,适用于为任意视频生成描述。DiffSW的核心理念是将 所有帧到描述(all-frames-to-caption) 的任务转化为差分描述任务。具体而言,本文为第一帧生成详细字幕,然后按时间顺序对后续帧应用长度为二的滑动窗口。GPT4V负责基于三个输入(前一帧、其差分字幕和当前帧)识别帧间变化。这包括了照相机运动、对象运动、角色动作和场景转换。获取所有差分字幕后,这些字幕将输入到GPT4生成整个视频的综合描述。差分概念使DiffSW能够集中于帧间的变化,即时序变化。滑动设计确保了时间顺序的正确性和帧数的不变性,保证GPT4V不遗漏细节并高效利用API,从而实现稳定、可扩展和高效的字幕质量。此外,差分设计允许通过重用其差分字幕来重新标注带字幕视频的任何子剪辑。
基于DiffSW,本文构建了ShareGPT4Video,包含4万组高质量的视频-字幕对,涵盖广泛类别,由此产生的字幕包含了丰富的世界知识、对象属性、相机运动,以及对事件的详细和精确的时间描述。ShareGPT4Video的视频来自不同来源,采用基于语义的数据过滤策略来减轻这些视频之间的内容同质性。然后对视频采用语义感知的关键帧提取策略,以减少时间冗余。将DiffSW应用于关键帧,生成高质量的字幕,并通过层次提示设计进一步提高了其稳定性和质量。采用人工质量检查,以确保视频字幕的质量。
基于ShareGPT4Video,本文提供了ShareCaptionor-Video,,一种特殊的视频标注器,能够有效地为广泛的分辨率、纵横比和持续时间的视频生成高质量的字幕。它能够以较低的成本和令人满意的质量,进一步扩展高质量的视频字幕数据,本文作者为480万个视频(总计约3000小时)生成高质量的字幕。
作者在视频理解和生成任务中进行了广泛的实验,以证明高质量的视频字幕数据集和优越的视频标注器的价值。在视频生成方面,在4.8M视频-字幕对上训练的基于DiT的文本到视频模型在生成10秒高分辨率视频-字幕对内容生成的细粒度控制方面表现良好。为了理解视频,ShareGPT4Video通过替换一小部分训练数据,在多个基准测试上为多个当前lvlm带来了一致的性能提高。本文进一步提出了ShareGPT4Video-8B,一个简单而出色的LVLM,在三个先进而全面的视频基准上达到了SOTA的性能。
ShareGPT4Video数据集
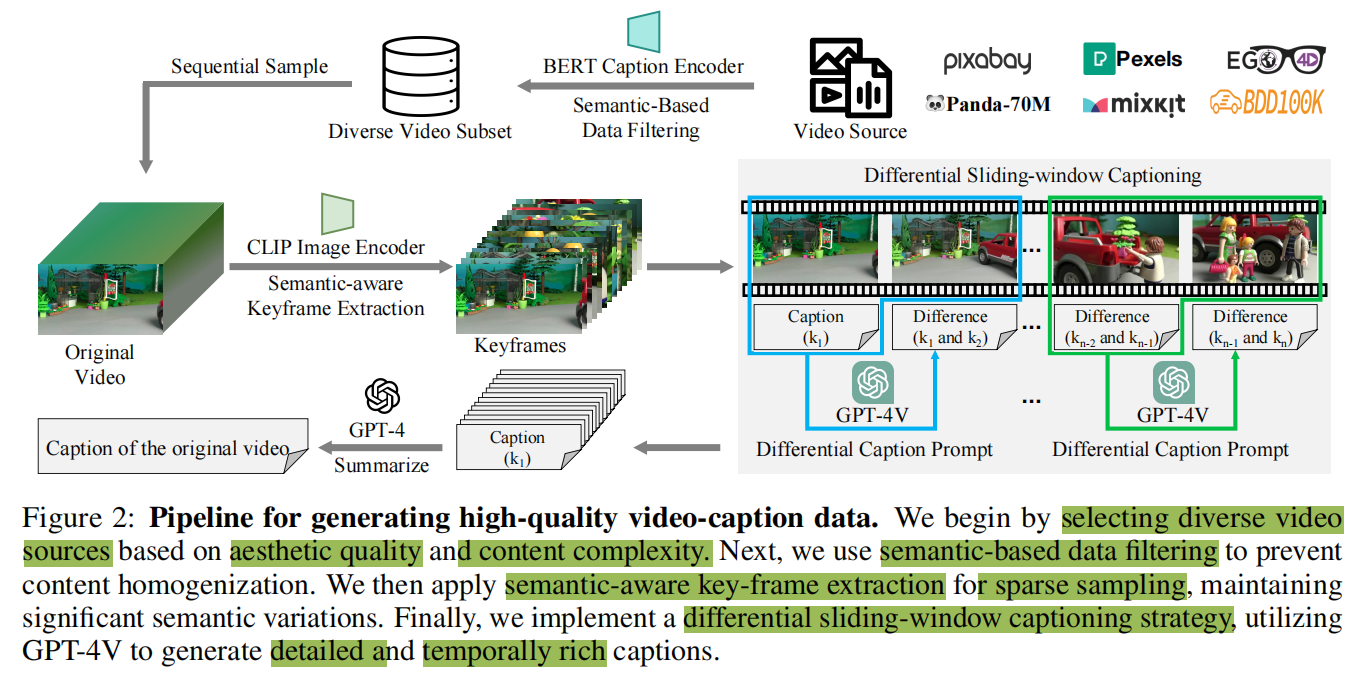
图2展示了ShareGPT4Video数据集构建的完整pipeline。首先要基于感官质量与内容复杂性选择多种不同的视频数据源。随后,使用基于语义的数据过滤来防止内容的同质化。然后,应用语义感知的关键帧提取来进行稀疏采样,以保持显著的语义变化。最后,实现了一个差分滑动窗口标注策略,利用GPT-4V来生成详细的和时间上丰富的描述。
数据采集
数据源选择:为了服务于视频理解和视频生成任务,论文在收集过程中考虑视频的美学质量和内容复杂性:
- 论文首先考虑Panda-70M,这是一个从YouTube获取的高分辨率视频数据集,包含时长约一分钟的片段。这个开放领域来源覆盖了野生动物、烹饪、体育、新闻与电视节目、游戏与3D渲染等多样领域。它通常包含复杂的内容和过渡,为理解各种现实世界场景提供了坚实基础。
- 然而,这些内容和过渡的复杂性对视频生成领域提出了重大挑战。为了解决这一问题,论文还从一些用户上传视频网站获取了大量美学上吸引人的视频。这些视频主要由风景和美学上令人愉悦的人类活动组成,涉及较少的过渡和更简单的事件。
- 最后,论文通过选择来自Ego4D 和BDD100K 的视频来补充数据集,填补自我中心人类活动和自动驾驶场景中的空白,确保论文的视频来源尽可能多地涵盖现实世界场景。
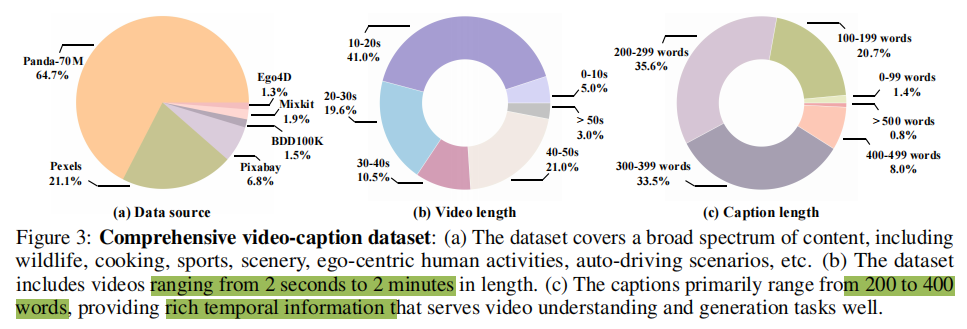
基于语义的数据过滤。尽管论文的字幕生成方法能够支持较长时间的视频,但由于视频时长与数量之间的权衡,数据采集主要集中在短于两分钟的视频上。
- 论文首先从选定的数据源中过滤掉超过两分钟的视频,将两分钟内的视频作为候选。随后,论文引入了一种基于语义的数据过滤策略,以减少这些候选视频之间的内容同质性,并保持最终视频数据集的多样性。该方法旨在从候选视频池中选择具有显著主题差异的视频,以构成论文的最终视频集合。
- 具体而言,论文首先使用Panda-Student 模型为每个候选视频生成一个简短的单句字幕,然后维护一个最终的视频候选池。每当处理一个新的视频V时,使用Bert-Base-Uncased语言模型对其相应的短字幕S进行编码,以获得CLS标记Pn+1∈R^1×D,它捕获高级语义表达。然后我们计算这个CLS标记P^n+1和候选池中的视频CLS标记{P1,P2,…Pn}的相似度。只有当一个新视频的最大相似度低于预定义的阈值时,该新视频才会被添加到池中。
- 论文提供了伪代码,如图14所示。

视频处理
视频在时间维度上通常是冗余的,而关键帧采样是紧凑地表示视频的一般思想。然而,传统的关键帧提取方法(key-frame extraction methods)通常难以确保语义的连贯性,导致缺少覆盖关键变化和过渡的关键帧。因此,本文开发了一种语义感知的关键帧提取方法,它可以在减少时间冗余和保持语义连贯性之间取得平衡。
语义感知的关键帧提取
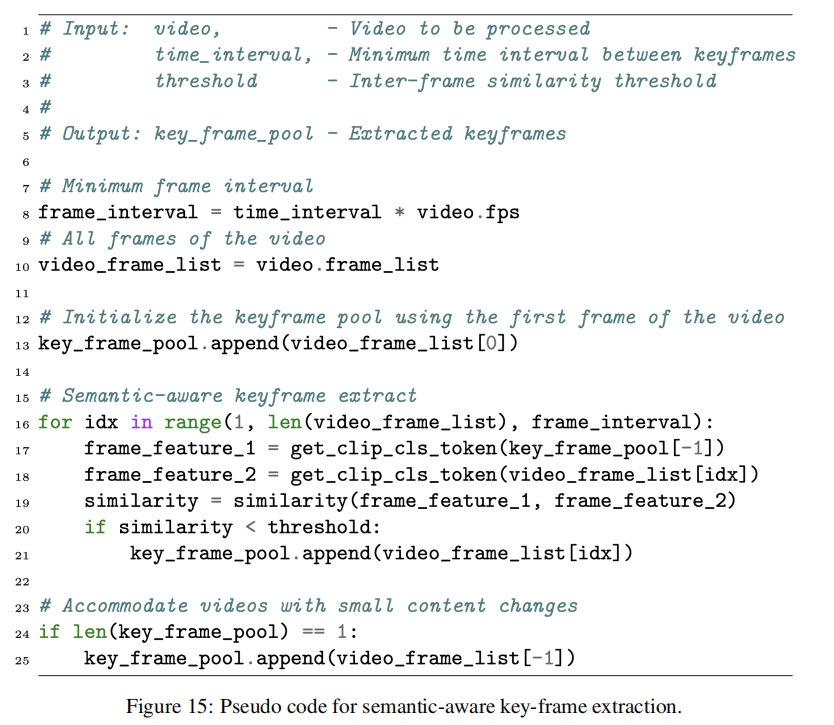
将V表示为从固定2秒间隔的视频中采样的T帧集,计算关键帧集合V’,该集合足够稀疏但能全面覆盖视频内事件的演变。论文将CLIP-Large图像编码器的输出CLS token视为每个帧的全局语义,并移除具有高语义相似性的相邻帧。在实践中,论文初始化关键帧集合V’为V的第一帧。对于V中的每个帧,论文计算其与V’中最新关键帧的语义相似度d 。如果d低于预定义的阈值,论文将该帧视为关键帧并将其添加到V’中。如果不是,则该帧被作为冗余帧跳过。为了完整性,V的最后一帧总是被添加到V’中。论文提供了伪代码,如图15所示。
字幕生成pipeline
正如第一节引言中提到的,本文发现如果直接将所有帧输入GPT4V,GPT4V难以稳定生成具有正确时序关系的字幕,并且随着帧数的增加,其性能进一步恶化。另一方面,如果论文将所有帧合并成一张大图,随着帧数的增加,GPT4V会丢失更多细节,如图11-12所示。


差分滑动窗口字幕生成
为此,论文开发了一种差分滑动窗口字幕生成pipeline,用于为各种视频生成高质量的字幕,并附带详细的时序描述。
具体而言,每次输入到图像多模态模型的内容包括当前关键帧,前一关键帧及其差分字幕。接着,论文引入了差分prompt,引导GPT4V关注当前帧与前一帧之间的变化,如姿态、位置、摄像机角度等。此外,将前一帧的差分字幕作为补充上下文融入,提高了响应质量并减少了幻觉现象。这是因为图像嵌入和文本字幕分别提供了图像的显式和隐式表示。差分字幕不仅增加了额外的上下文,还整合了来自两帧之前的时序信息,进一步增强了模型的时序理解能力。需要注意的是,对于第一帧,它的差分字幕直接由标准字幕替换。
最后,论文将所有差分字幕及其相应的时间戳输入到GPT4中。设计了一个特定的总结prompt,指导大型语言模型生成具有精确时序动态和详细空间信息的高质量视频字幕。在实践中,论文使用GPT-4-Turbo-04-09进行所有标注。
在提示的设计中,作者发现显式的层次提示设计有助于GPT4V理解其角色、预期格式和操作边界。这种方法有助于稳定输出的格式,并提高结果的整体质量。
分层提示设计
分层提示设计(Hierarchical Prompt Design)帮助多模态模型和语言模型在captioning过程中有效地执行它们的角色。
图7和图8分别阐述了差分字幕提示(differential-caption prompt)和摘要(总结)提示(summary prompt)。
层次化prompt主要由四个组件组成。角色(character)部分为模型提供了对它所扮演的角色和它所面临的工作环境的整体感知。技能(skills)部分指定了模型需要拥有的技能,确保精确地符合多个要求,而不存在遗漏或混淆。约束(constraints)部分澄清了用户不希望执行的行为,以及在构建输出时要遵循的规则。结构化输入(Structured Input)部分要求用户根据他们的特定场景进行设置。
例如,当指导模型生成差分字幕时,角色部分通知模型它是分析视频帧的专家。技能部分要求模型来描述帧间的目标动作和行为、环境和背景的变化、目标外观属性的变化,以及反映时间变化的摄像机运动。约束部分要求精确的描述,而不是逐项列出它们。在“结构化输入”部分中,输入由帧索引、时间戳、前一帧和它的差分字幕组成。


ShareCaptioner-Video
模型设计
论文使用收集的视频字幕数据对IXC2-4KHD 进行微调,从而得到论文的ShareCaptioner-Video。为了灵活使用,论文对数据进行了重新组织,以支持以下功能:
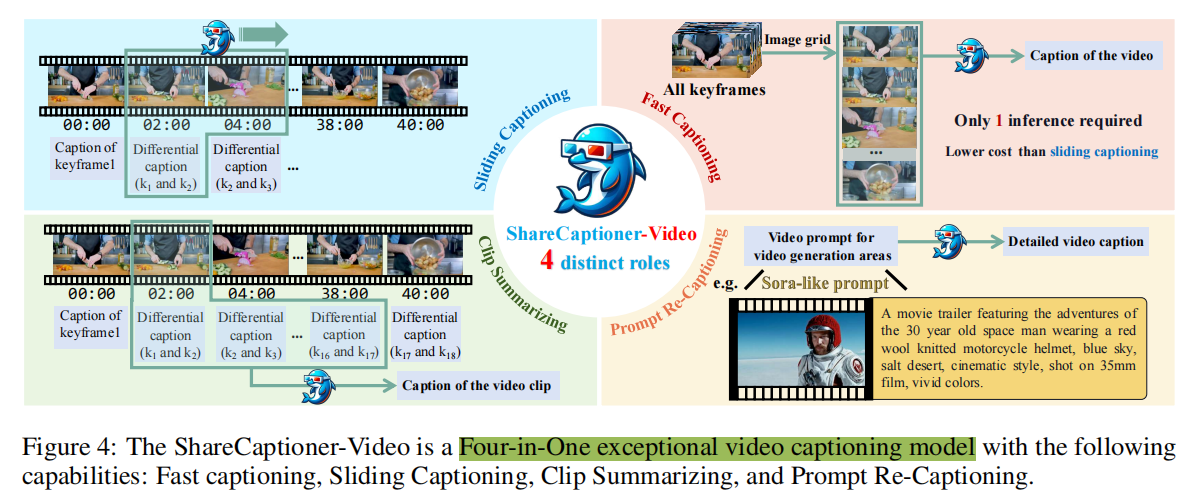
- 快速字幕生成:该模型采用图像网格格式(image-grid format)进行直接字幕生成(direct video captioning),提供了适用于短视频的快速生成速度。在实践中,论文将视频的所有关键帧连接成一个垂直拉长的图像,并在字幕任务上对模型进行训练。
- 滑动字幕生成:该模型支持以差分滑动窗口格式(differential sliding-window format)进行流式字幕生成,生成适用于长视频的高质量字幕。与第2.3节中使用的字幕流程类似,将两个相邻关键帧及前面的字幕作为输入,并训练模型描述它们之间发生的事件。
- 片段摘要:该模型可以快速总结来自ShareGPT4Video或经历了差分滑动窗口字幕生成过程的视频的任何片段,无需重新处理帧。论文将所有差分描述作为输入,输出为视频字幕。
- prompt重述:模型可以根据用户输入的特定视频生成领域的提示进行重述,确保基于高质量视频字幕数据训练的T2VM在推理过程中与其训练中保持格式对齐。在实践中,论文使用GPT-4生成Sora风格的提示,用于论文的密集字幕,并以相反的方式训练re-captioning任务,即 使用生成的prompt作为输入,密集字幕作为训练目标。(这个没懂
在实践中,作者在一个epoch内对模型进行端到端微调。遵循默认的高分辨率策略,使用“HD-55”用于快速字幕任务,其他的则使用“HD-25”。所有模型组件的学习速率都是一致的,并在前1%的step内从0升温到2.5×10−5。批处理大小设置为1024,且对数据进行统一采样。
规模化caption
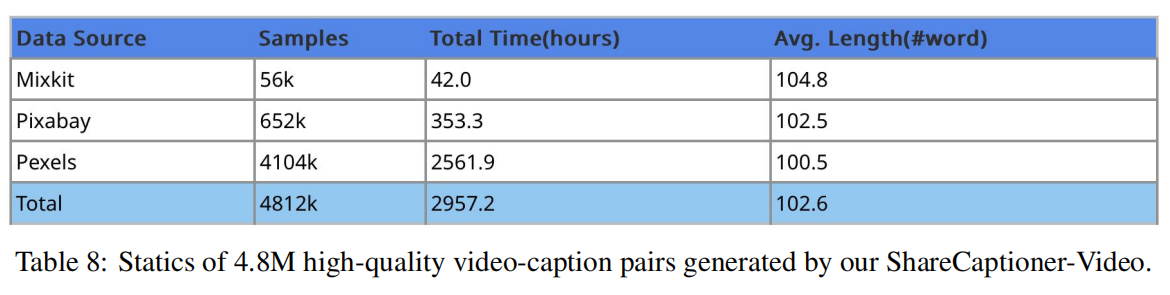
为了验证论文的ShareCaptioner-Video在视频字幕生成任务中的有效性,并进一步支持视频生成领域的发展,论文利用它对大量审美吸引人的视频进行了注释。具体来说,论文从三个来源精心收集和处理了480万个视频剪辑,总计约3000个小时,分别是: MixKit,Pexels 和Pixabay。随后,采用ShareCaptioner-Video的滑动字幕生成模式,为这些视频生成高质量的字幕。整个字幕生成过程需要大约4000个H100 GPU小时。图8中提供了一些关于生成的字幕的统计信息。
实验
视频理解
数据集和基准
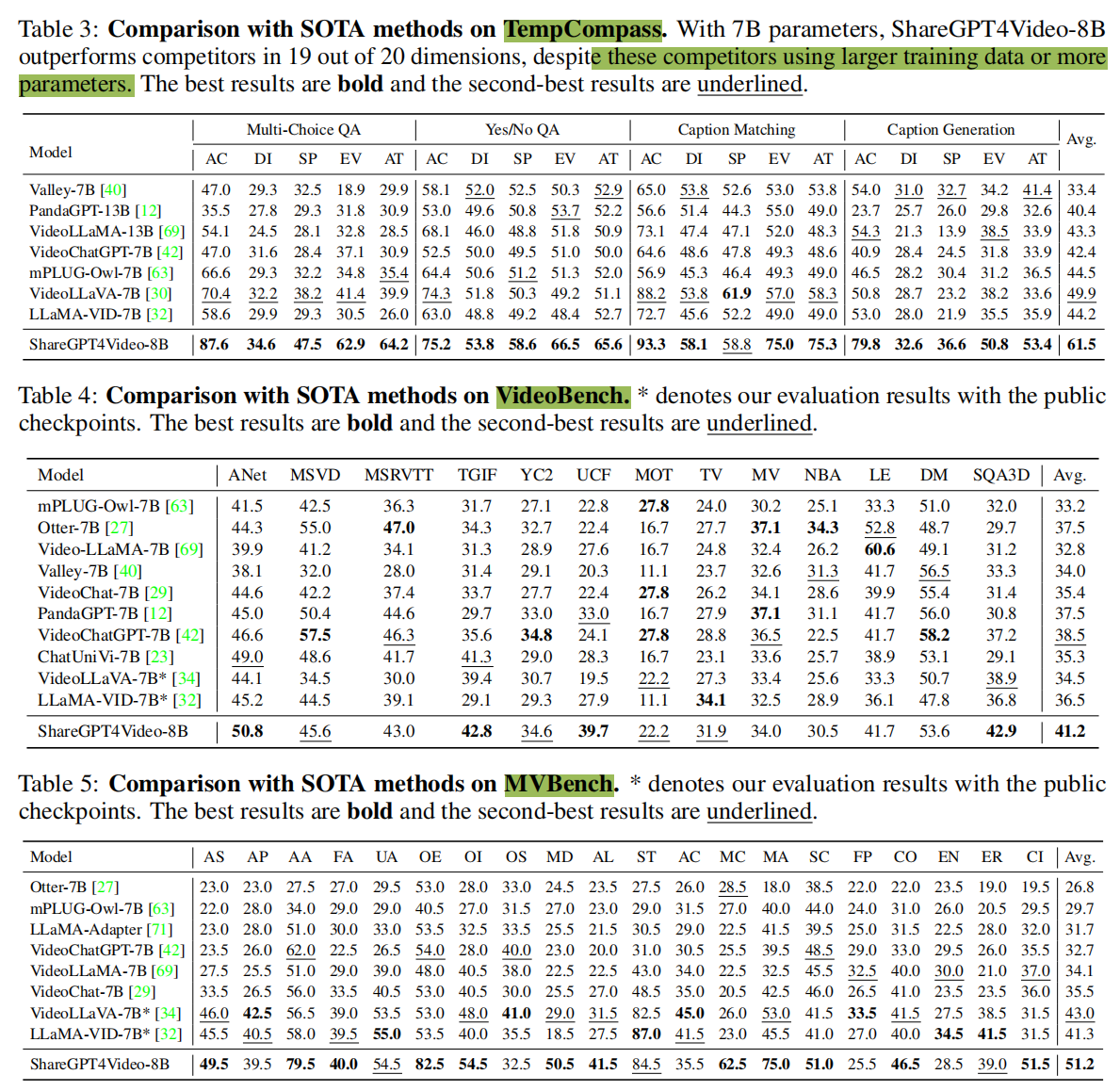
为了全面探索高质量视频字幕数据给LVLMs带来的益处,论文在三个多模态视频基准上对模型进行了全面评估。VideoBench从13个现有数据源(如MSVD-QA,MSRVTT-QA,Activitynet-QA等)中策划了约15,000个跨10个评估维度的QA对。MVBench 旨在挑战LVLMs处理视频任务,这些任务不能通过单帧依赖有效解决,其包含了从11个公共视频测试中派生出的4,000个QA对基准。TempCompass 特别评估了LVLMs在各种时间方面的微妙性能,如速度、方向和属性变化。它包含410个视频和7,540个精心收集的指令,强调时间理解和交互。
ShareGPT4Video
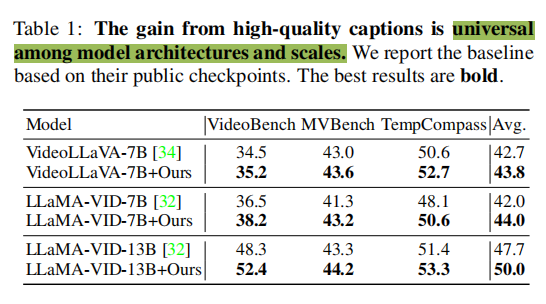
通过ShareGPT4Video提升当前LVLM的性能。论文验证了ShareGPT4Video收集的高质量视频字幕数据对于提升当前LVLM性能的有效性。为了公平和简化,论文将ShareGPT4Video中与复杂场景相关的28K高质量视频字幕数据(包括Panda-70M 、Ego4D和BDD100K )整合,以同等数量替换VideoChatGPT-100K 对话数据中的字幕数据。然后,论文使用默认的训练设置和超参数训练VideoLLaVA 和LLaMA-VID。如表1所示,ShareGPT4Video在不同的LVLM架构和规模上持续提高了视频与语言模态之间的对齐。具体而言,集成高质量字幕后,VideoLLaVA-7B在三个全面的多模态视频基准测试上平均性能提升了1.1,而LLaMA-VID-7B和LLaMA-VID-13B分别实现了平均2.0和2.3的提升。论文证明高质量的视频字幕数据特别有助于LVLM在需要复杂时间理解的基准测试上实现显著的性能提升,例如TempCompass 。
ShareGPT4Video-8B
为了获得最终的ShareGPT4Video-8B模型,论文从LLaVA-Next-8B图像多模态模型开始。与之前的LVLM方法一致,论文遵循lG-VLM策略,从每个视频中均匀采样16帧,并将这些帧排列成4x4的图像网格,以形成训练和推理的输入。对于训练数据,论文首先从各种视频到文本数据集中收集153K的VQA数据来构建论文的基准。这一收集包括来自VideoChatGPT的13K对话数据和140K问答对,其中45K数据点来自CLEVRER ,8K来自EGO-QA ,34K来自NextQA ,53K来自TGIF-Transition 。然后,这些VQA数据与28K视频字幕数据结合,形成一个包含181K样本的综合训练数据集。
在训练期间,本文使用了128的批处理大小和AdamW优化器。本文选择对整个模型进行微调,将视觉编码器的学习速率设置为2e-6,将MLP投影层的学习率设置为2e-5,对于使用LoRA的LLM,将学习速率设置为2e-4。这样的训练策略使作者能够在大约5小时8A100gpu内获得一个特殊的LVLM,ShareGPT4Video-8B。
表3、4、5展示了ShareGPT4Video-8B模型(由论文的ShareGPT4Video数据集增强)与现有最先进的LVLMs之间的定量比较。值得注意的是,与之前的LVLMs相比,论文的ShareGPT4Video-8B在所有三个综合基准测试中均取得了最优性能。具体而言,得益于ShareGPT4Video提供的丰富时间信息,本文模型在TempCompass基准上实现了平均准确率61.59%。这比之前表现最佳的LVLM,VideoLLaVA-7B提高了11.6%。此外,尽管VideoBench和MVBench基准从各种现有视频数据集中收集了多样化的QA数据,论文在这两个基准上均取得了稳健的性能,平均准确率分别超过之前的最先进水平2.7%和8.2%。
消融实验
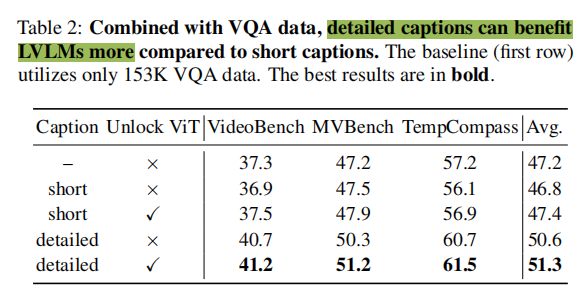
关于字幕质量和ViT的消融研究。基于ShareGPT4Video-8B,论文研究了字幕质量和可学习的视觉编码器如何影响模态对齐。如表2所示,在VQA数据之上引入简短的字幕可能不会带来显著的性能提升。由于模态对齐不佳,它甚至可能在某些基准上降低性能。比较表2中的第一、第二和第四行,得益于论文高质量字幕数据,理解时间序列的性能提升是显而易见的。此外,在训练时使用详细字幕解锁视觉编码器有助于更好地实现LVLMs的模态对齐。
视频字幕生成
为了验证ShareCapitoner-Video的能力,论文通过人类偏好投票定量比较了ShareCapitoner-Video与GPT4V之间的视频字幕质量。如表7显示,其性能与GPT4V相当。打分标准:邀请10名志愿者从三个方面对字幕进行评估。这些方面包括:(1)遗漏和虚构 - 检查字幕中有没有缺少的关键元素,或识别到视频中不存在的图像元素;(2)失真 - 评估元素属性,如颜色和大小的准确性;(3)时间不匹配 - 评估描述是否准确地反映了视频中时间事件的演变。每对最多可以获得3分,每个标准1分。
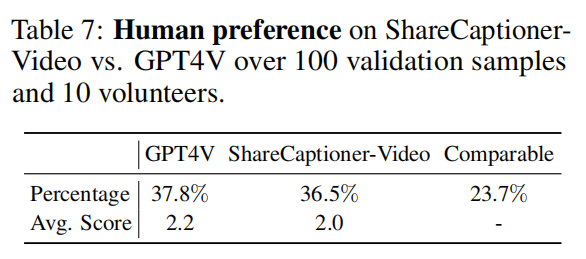
表6比较了ShareCapitoner-Video与GPT4V生成的字幕的词汇成分,结果表明二者有相当的信息级别。
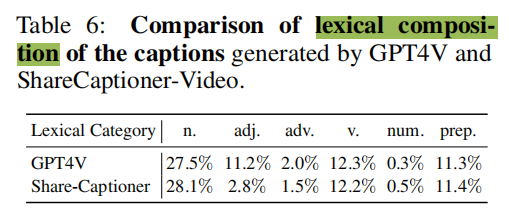
图9给出了不同来源的视频字幕质量的定性比较。
- Panda-Student:为视频生成一句话的描述。虽然这种方法最大限度地减少了错误,但它没有为信息密集的视频提供足够的文本信息,阻碍了视频和语言模式的对齐。
- Video ChatCaptioner:使用ChatGPT构建问题,使用BLIP2做VQA,然后再次使用ChatGPT基于QA总结一个完整的字幕。虽然这种方法产生的字幕比Panda-Student更长,但ChatGPT的广泛参与往往会导致过度想象和幻觉,对视频和语言模式之间的一致性产生负面影响。
- GPT-4V:展现了杰出的字幕生成能力。
- ShareCapitoner-Video:在ShareGPT4Video数据集上进行微调后,同样展现了优秀的字幕生成能力。

视频生成
模型设置
为了验证高质量字幕在T2VMs领域的有效性,论文使用ShareCaptioner-Video和Panda-Student 分别为450万个65帧视频和30万个221帧视频生成高质量且简短的视频字幕。遵循Open-Sora-Plan中概述的流程,论文对预训练的T2VM进行了微调,以生成高保真度10秒视频。作为比较,论文对具有相同数量视频-简短字幕对的基线模型进行了微调。
实现细节:利用Latte-XL模型和一个来自T5-XXL的文本编码器。第一阶段,在较少的帧数上进行预训练,并实现联合图像-视频训练,图像批处理大小是视频的4倍。这个阶段包括5万训练steps。在第二阶段,视频和图像的批量大小都减少到2。对于所有的训练阶段,使用了固定的学习速率为2e-5的AdamW优化器,图像和视频的分辨率均设置为512×512。为了训练精度,使用Bf16,因为fp16导致损失成为NaN。第一阶段需要大约6K H100 GPU小时,而第二阶段需要大约36K Ascend GPU小时。
定性分析
如图5所示,T2VM在ShareCaptioner-Video生成的高质量详细字幕辅助下,能够准确遵循详细prompt,并在语义内容和相机运动控制方面表现出卓越的控制能力。生成的视频展示了复杂而生动的画面。相比之下,当提供简短字幕时,T2VM难以遵循复杂的生成prompt,导致结果不佳。


局限和影响
局限:虽然本文目前生成高质量视频字幕的pipeline充分利用了视觉和文本信息,但由于GPT4V无法同时合并音频信息,它受到了限制。音频信息在涉及日常人类活动的对话场景中是有益的,一旦GPT4o支持音频输入,作者计划在未来的工作中引入音频信息,以进一步提高字幕的质量。
社会影响:1)由于大型语言模型涉及到大规模字幕的生成过程,作者没有手动验证每个字幕的社会偏见内容;2)虽然作者利用了来自现有公共数据集的视频数据,但作者不能确保所选的视频不包含人脸。因此,虽然对本文生成的字幕的使用没有限制,但用户在使用视频时必须遵守原始视频源的许可。
总结
在本研究中,作者的目的是解决大型视频语言模型(LVLMs)和文本到视频模型(T2VMs)缺乏高质量的视频字幕数据的挑战。作者开发了ShareGPT4Video,一个高质量的视频字幕数据集,和ShareCaptioner-Video,一个在视频语言多模态领域的先进和多功能的模型。通过采用一系列的策略和设计,本文从高级的图像多模态模型、GPT4V和4.8M字幕数据(由ShareGPT4Video生成)得到了40K详细字幕。这些字幕包括丰富的世界知识、对象属性、相机运动和对事件的详细时间描述。本文广泛的实验验证了提出的数据集和标注器在增强视频理解和生成任务方面的有效性。
架构相关
关键帧采样
import os
from torch.nn import functional as F
import cv2
import math
from transformers import CLIPFeatureExtractor,CLIPVisionModel
import numpy as np
model_path = 'openai/clip-vit-large-patch14-336'
feature_extractor = CLIPFeatureExtractor.from_pretrained(model_path)
vision_tower = CLIPVisionModel.from_pretrained(model_path).cuda()
vision_tower.requires_grad_(False)
def calculate_clip_feature_sim_2(image_1, image_2):
input_1 = feature_extractor(images=image_1, return_tensors="pt", padding=True)
input_2 = feature_extractor(images=image_2, return_tensors="pt", padding=True)
image_feature_1 = vision_tower(**input_1.to(device=vision_tower.device), output_hidden_states=True).hidden_states[-1][:, 0]
image_feature_2 = vision_tower(**input_2.to(device=vision_tower.device), output_hidden_states=True).hidden_states[-1][:, 0]
similarity = F.cosine_similarity(image_feature_1.to(device='cpu'), image_feature_2.to(device='cpu'), dim=1)
print(f'Sim: {similarity}')
return similarityCLIPVisionModel 是 OpenAI CLIP 模型的视觉部分,用于从图像中提取特征。它是基于 Vision Transformer (ViT) 或其他卷积神经网络架构(例如 ResNet)构建的模型。CLIP 的主要目标是通过视觉和语言的对比学习来使模型同时理解这两种模态。
在 CLIP 的视觉模型中,图像通过一个深度神经网络进行处理,该网络的目的是将图像嵌入到一个高维空间中,在这个空间里,视觉特征可以与文本特征对齐,从而使得图像和文本可以相互比较。
CLIPVisionModel 内部结构主要由以下几个组件组成:
- 输入层:
- 图像首先会被输入到一个预处理的特征提取器(如
CLIPFeatureExtractor),它会对图像进行缩放、裁剪和标准化等操作,确保图像符合模型的输入要求。
- 图像首先会被输入到一个预处理的特征提取器(如
- 视觉模型(通常是 Vision Transformer):
- CLIP 使用的是 Vision Transformer (ViT) 架构。ViT 是一种基于 Transformer 的视觉模型,使用自注意力机制来捕捉图像中的局部和全局信息。
- 具体来说,图像首先被分割成固定大小的补丁(patches),每个补丁被视为一个 token,类似于文本中的单词。然后这些补丁经过嵌入、线性变换,形成与文本输入类似的高维特征表示。
- CLIP 中的 Vision Transformer 通常采用 ViT-B/16(Base model,16x16 图像补丁)或其他类似的架构。
- 图像嵌入(Image Embeddings):
- 通过 Vision Transformer 处理后,最后的隐藏状态(通常是
[CLS]token 对应的输出)被用作图像的特征向量(embedding)。 - 这个特征向量是一个高维的表示,它捕捉了图像的语义信息,并与文本嵌入对齐,可以用来进行图像与文本的匹配和相似度计算。
- 通过 Vision Transformer 处理后,最后的隐藏状态(通常是
- Transformer 层和多头自注意力机制:
- Vision Transformer 通过多层的自注意力机制对图像中的补丁进行建模,能够捕捉图像中复杂的关系和语义信息。每一层的输出会提供一个更加丰富的图像表示。
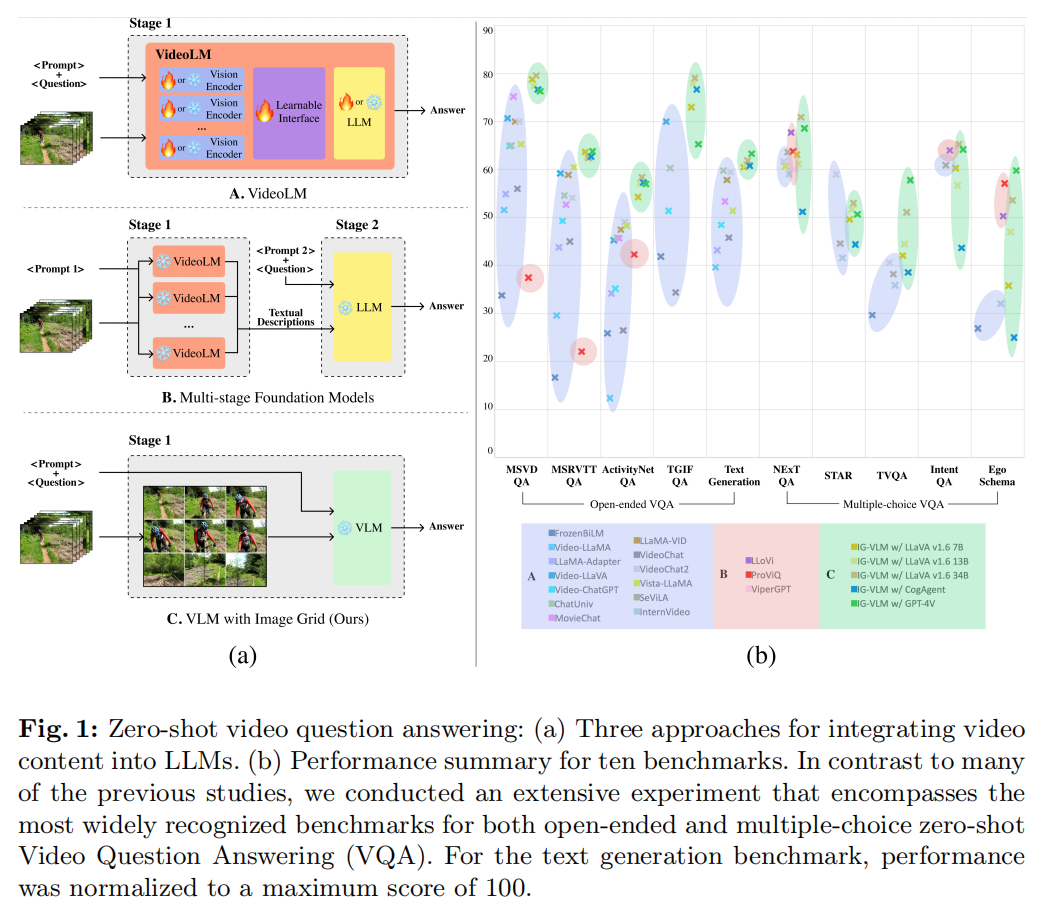
IG-VLM策略
An Image Grid Can Be Worth a Video: Zero-shot Video Question Answering Using a VLM
标题:一个图像网格可以抵得上一段视频使用 VLM 进行零镜头视频答题
author:Wonkyun Kim, Changin Choi, Wonseok Lee, Wonjong Rhee
paper:An Image Grid Can Be Worth a Video: Zero-shot Video Question Answering Using a VLM
publish:Our code is available at https://github.com/imagegridworth/IG-VLM
date Time:2024-03-27
在最近的大型语言模型(LLM)的复杂推理能力的刺激下,人们设计出了多种连接视频模式的策略。视频语言模型(VideoLMs)是其中一个突出的策略,它利用视频数据训练可学习的界面,将高级视觉编码器与 LLMs 连接起来。最近,出现了另一种策略,即利用视频语言模型(VideoLMs)和 LLMs 等现成的基础模型,在多个阶段实现模态桥接。在本研究中,我们介绍了一种简单而新颖的策略,即只使用一个视觉语言模型(VLM)。我们的出发点是一个朴素的观点,即视频由一系列图像或帧组成,并与时间信息交织在一起。视频理解的精髓在于对每一帧图像的时间信息和空间信息进行有效管理。起初,我们通过将多个帧按网格布局排列,将视频转换成单一的合成图像。由此产生的单一图像被称为图像网格。这种格式在保持单幅图像外观的同时,有效保留了网格结构中的时间信息。因此,图像网格方法可以直接应用单一的高性能 VLM,而无需任何视频数据训练。我们对 10 个零样本视频问题解答基准(包括 5 个开放式基准和 5 个多项选择基准)进行了广泛的实验分析,结果表明所提出的图像网格视觉语言模型(IG-VLM)在 10 个基准中的 9 个基准中超越了现有方法。
参考
[2406.04325] ShareGPT4Video: Improving Video Understanding and Generation with Better Captions
[ShareGPT4Omni/ShareGPT4Video: NeurIPS 2024] An official implementation of ShareGPT4Video: Improving Video Understanding and Generation with Better Captions



