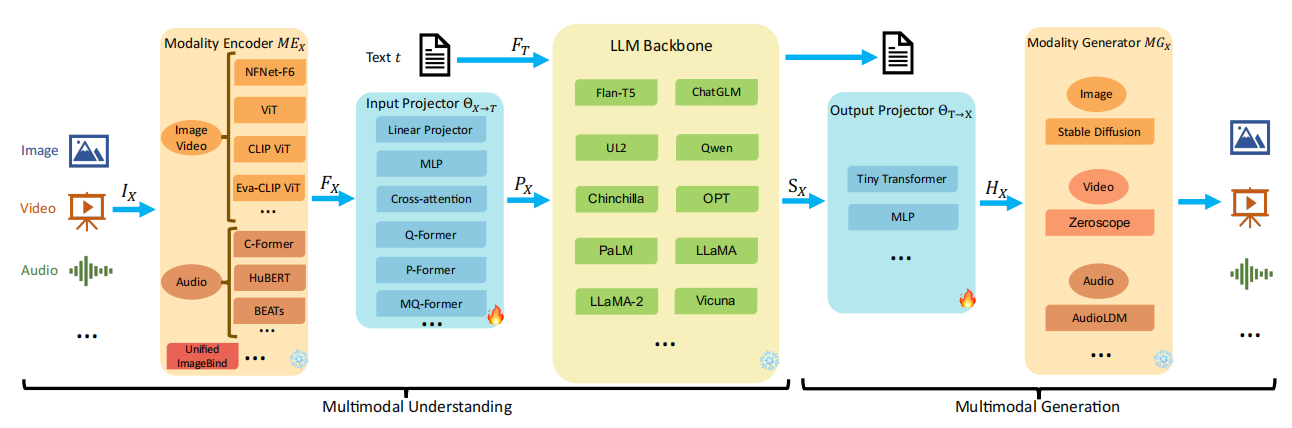
多模态架构相关
MLLM通常包含以下几个组件:
- 一个预训练的模态编码器:用于接收视觉/听觉输入等不同模态的输入并编码为模态特征。
- 一个输入投影器(模态接口):用于将多模态的特征对齐到文本特征空间,并且和文本特征一起输入到llm。
- 一个预训练的大模型backbone:利用LLM对对齐后的特征做语义理解、推理和决策,并输出统一的信号。
- 可选的输出投影器:将语言模型输出的信号进一步转换为其他模态的特征,或者是投影到任务需要的输出范式中。
- 可选的模态生成器:负责生成其他模态的输出。
视觉编码器
CLIP VIT
CLIP的的核心思想是通过海量的弱监督文本对对比学习,将图片和文本通过各自的预训练模型获得的编码向量在向量空间上对齐。不足:clip可以实现图文匹配,但不具有文本生成能力。
这里对提取的文本特征和图像特征进行对比学习。对于一个包含N个文本-图像对的训练batch,将N个文本特征和N个图像特征两两组合,CLIP模型会预测出N^2个可能的文本-图像对的相似度,这里的相似度直接计算文本特征和图像特征的余弦相似性(cosine similarity),即上图所示的矩阵。这里共有N个正样本,即真正属于一对的文本和图像(矩阵中的对角线元素),而剩余的N^2−N个文本-图像对为负样本,那么CLIP的训练目标就是最大化N个正样本的相似度,同时最小化N^2−N个负样本的相似度

CLIP VIT是在大名鼎鼎的CLIP这项工作中,作者团队使用约4亿个图像-文本对数据训练得到的VIT权重,可以说是当前最强的VIT模型之一,Clip VIT已经成为目前多数多模态模型的首选。
EVA-CLIP
蒸馏版CLIP,训练消耗更小,速度更快,效果更好。
EVA-CLIP,这是一种基于对比语言图像预训练(CLIP)技术改进的模型,通过引入新的表示学习、优化和增强技术,显著提高了CLIP的训练效率和效果。EVA-CLIP系列模型在保持较低训练成本的同时,实现了与先前具有相似参数数量的CLIP模型相比更高的性能。特别地,文中提到的EVA-02-CLIP-E/14+模型,使用90亿数据样本和5.0B(50亿)参数,在ImageNet-1K的val数据集上取得了82.0%的零样本准确率,而较小的EVA-02-CLIP-L14+模型,尽管仅使用了4.3亿参数和60亿数据样本,也达到了80.4%的准确率。这些结果表明,EVA-CLIP在图像分类任务中,特别是在零样本学习场景下,展现出了卓越的性能。

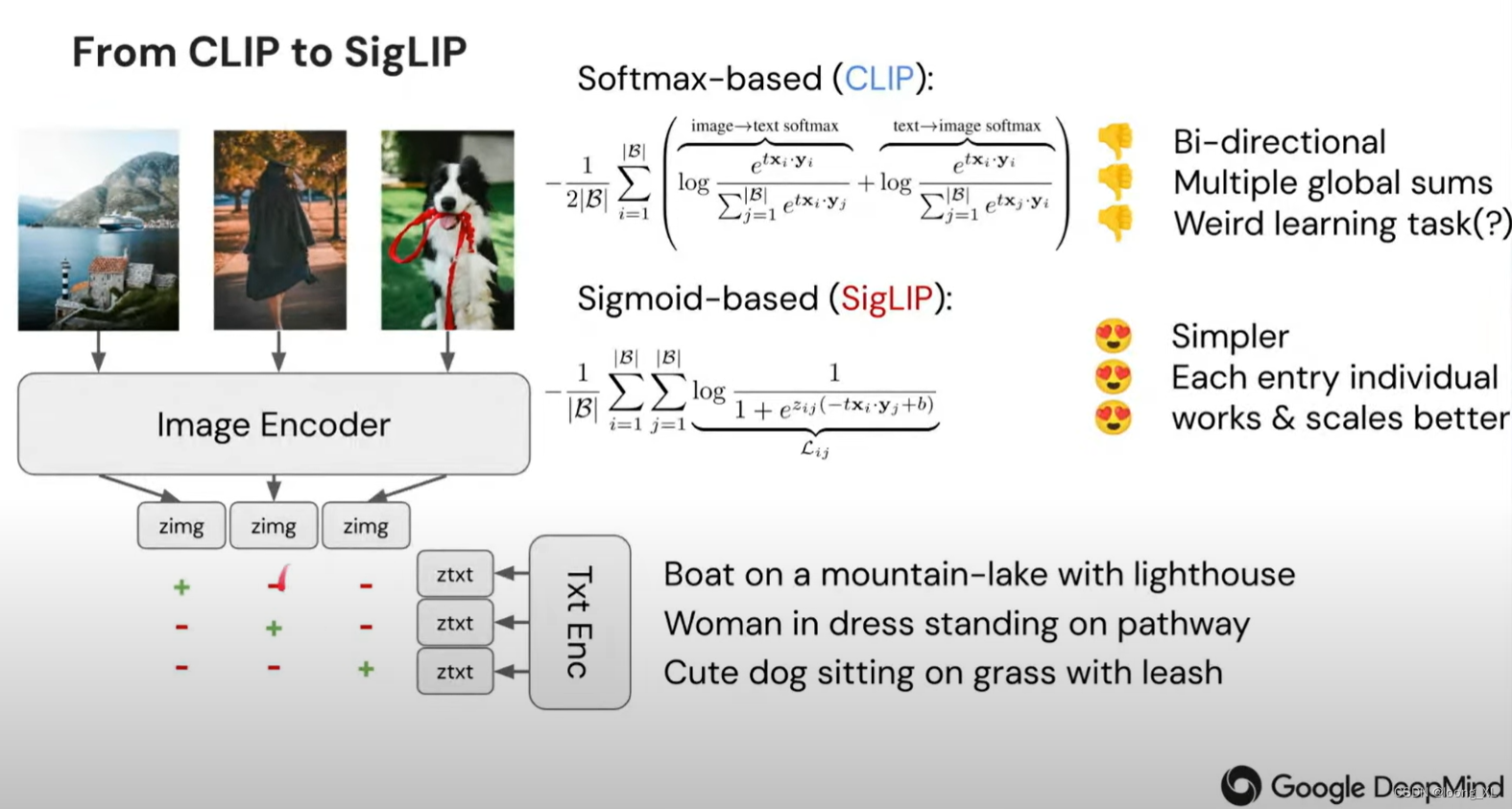
SigLip
CLIP 面临两个技术挑战:(1)它需要较大的批大小。例如,CLIP使用了 32K 的批量大小,这需要大量 GPU;(2)它需要这些 GPU 之间进行大量通信。
SigLip方法减少 了CLIP 的批量大小要求, 是Sigmoid Language Image Pre -training 的缩写。SigLIP 的核心思想是使用 Sigmoid运算而不是Softmax运算。CLIP 使用 Softmax 函数,因此,给定正对(图像-文本)的损失取决于批量内的每个负对。相比之下,SigLIP 既不对称,也不需要全局归一化因子。因此,每对(正数和负数)的损失都与小批量内的其他对无关。
NFNet
High-Performance Large-Scale Image Recognition Without Normalization (ICML 2021)
NFNet(Normalizer-Free ResNets)是DeepMind提出的一种不需要Batch Normalization的基于ResNet的网络结构,其核心为一种AGC(adaptive gradient clipping technique,自适应梯度裁剪)技术。最小的NFNet版本达到了EfficientNet-B7的准确率,并且训练速度快了8.7倍,最大版本的模型实现了新的SOTA效果。
NFNet 视觉大模型:匹敌 ViT 性能的大规模预训练:
结论:当能够访问足够大的数据集时,CNN实际上可以与 ViT 竞争。决定一个视觉骨干模型性能的最重要因素是用于训练的计算预算 和训练的数据量 。尽管 ViT 在视觉任务上的成功让人印象深刻,但是在本文看来,没有强有力的证据表明预训练的视觉 Transformer 模型的性能在计算预算相当的条件下优于预训练的 ConvNet 模型。
但不可否认的是,Transformer 模型在特定的上下文中具有实际优势,比如能够在多种模态中使用相似的组件的能力。

视觉token压缩
为提升MLLM对图像、视频的理解能力,最有效的方式就是提升visual token的个数,随之而来的则是训练、推理耗时的增加。因此,对视觉token进行压缩以提取最有用的信息至关重要。
目前的视觉映射器分以下几种:
Resampler or Q-former:该方法通过引入可学习的 query 来自适应地来学习相关视觉表示,通过控制可学习 query 的个数来控制视觉 token 产生的数目。
基于卷积的视觉映射器:典型的工作有 C-abstractor、LDPv1/v2, 通过引入卷积操作来建模局部视觉信息之间的关系,同时采用下采样减少视觉表示的长度。
维度变换:将产生的视觉表示在 sequence 的维度变换到 channel 维度,如 PixelShuffle,虽然视觉信息没有减少但结构信息可能会被破坏。在 InternLM-XComposer2-4KHD 与 InternVL 1.5 的研究工作均采用了类似的操作。此外,在研究工作 MM1 中,也对常用的几种 Visual Projector 进行实验验证与性能分析。
Q-Former
Q-Former由两个transfomer子模块组成,左边为(learnable) query encoder,右边为text encoder & decoder。记视觉模型的image encoder的输出为I。左边网络的(learnable) query为Q,右边网络的输入text为T。注意Q是一个向量集,非单个向量。它可以视为Q-Former的参数。

Perceiver Resampler
感知重采样技术(Perceiver Resampler)首次被引入 MLLM 是2022 年 4 月DeepMind 在论文 Flamingo 中提出的,Flamingo采用了感知重采样(Perceiver Resampler)技术和门控交叉注意力技术(Gated Cross-Attention)进行视觉多模态信息和LLM的融合,代表模型:Flamingo、Qwen-VL、MiniCPM-V、LLaVA-UHD
- 数据压缩与选择:图像通常具有很高的维度(例如,像素级别的数据),直接将这些高维数据输入到Transformer中会导致计算负担过重。Perceiver Resampler的主要目标是将这些高维视觉数据压缩到固定数量的紧凑表示,以适应后续的Transformer处理。
- 模态对齐:在多模态任务中(如视觉语言任务),图像和文本往往具有不同的模态特性。Perceiver Resampler通过学习跨模态的映射,将图像数据转换为与文本表示形式相匹配的低维向量。这种转换可以使Transformer更容易处理和对齐不同模态的信息。
- 自适应表征学习:Perceiver Resampler不是简单地对图像进行下采样,而是通过可学习的参数自适应地从输入中提取重要信息。这使得模型能够动态地选择与任务相关的视觉特征。

Linear Projector
Linear Projector(线性投影器)首次被引入 MLLM 是2023年4月 LLaVA1.0 的发布,论文中提出了一种更简单的投影方法,通过线性变换将Modality Encoder编码的特征映射到LLM的表示空间中。代表模型主要有:LLaVA、MiniGPT-4、NEXT-GPT。
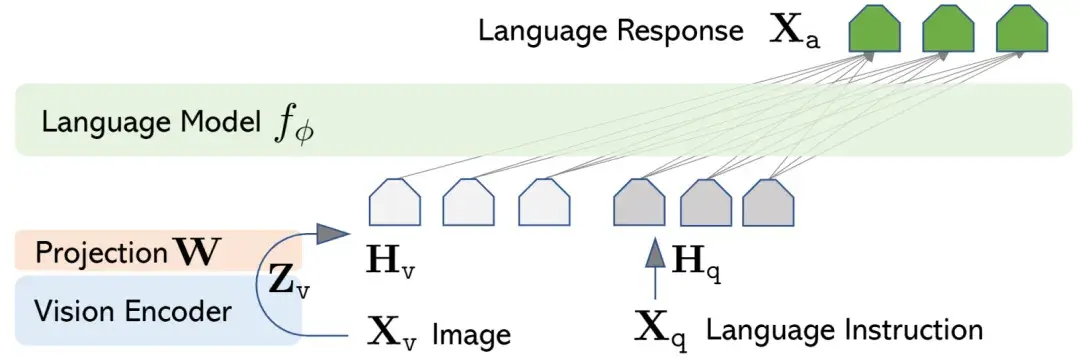
Linear Projector结构比较简单,比Q-Former简单的多,非常易于实现和训练,但是效果上却一点也不弱于Q-Former。
Multi-Layer Perception
多层感知机(Multi-Layer Perception, MLP)首次被引入 MLLM 是在2023 年 10 月 LLaVA1.5 中提出的,LLaVA1.5 在对比LLaVA1.0结构上,将视觉特征从线性映射(单个神经元),改进为多层感知机(MLP)。代表模型包括:LLaVA1.5/NeXT、CogVLM、DeepSeek-VL、Yi-VL。
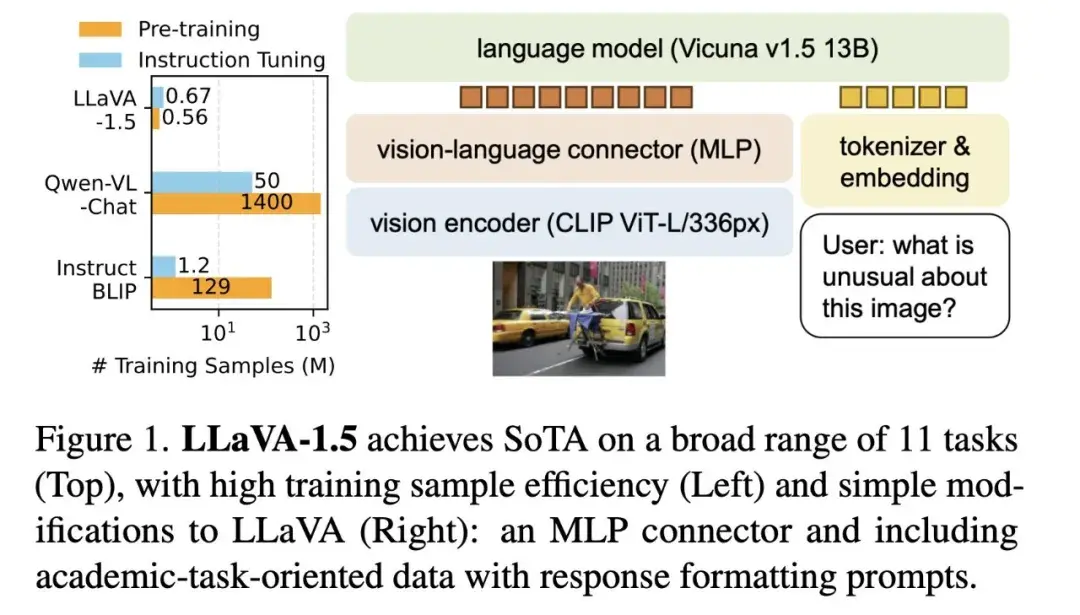
多层感知器由多层线性变换和非线性激活函数组成,能够捕捉输入数据的复杂非线性关系。
最近MLP结构成为了MLLM中模态对齐的主流结构,LLAVA 系列的技术路线被大家更认可,主要原因是:MLP用最简洁的结构在效果上碾压其他一众复杂结构,并且具有更快的收敛速度,对数据量的依赖也少。
音频编码器
Whisper
Whisper是 OpenAI于 2022 年09月开放的一个超大规模的语音识别预训练模型,它使用端到端的方式进行多语言的预训练,在开放域的英语ASR (语音识别)能力上已经实现了与人类相对的水平。
Whisper 使用标准的 Transfomer 编码器-解码器架构对模型进行训练。每条语音数据输入长度为 30 秒,通过 25ms 的汉明窗和 10ms 的步移,在 16000 的采样帧率下,转化为 3000 帧长,80维度的对数梅尔频谱图。并使用两层1维的卷积神经网络和 GELU 激活函数对原始对数梅尔频谱图进行初始的特征提取。

CLAP
CLAP(Contrastive Language-Audio Pretraining)是在2023年提出的一种基于对比学习的预训练方法,旨在通过结合音频数据和相应的自然语言描述来学习音频的表示。这种方法的核心思想是利用对比学习范式,将音频和文本映射到一个共享的潜在空间中,并通过训练使得相关的音频-文本对在该空间中更接近,而不相关的对更远离。简单来说,CLAP是参考了CLIP的思路,将图像-文本对迁移至音频-文本对,并完成音频数据预训练的工作。

HuBERT
HuBERT 是 Meta 在 2021 年发表的模型,模型结构类似 Wav2vec 2.0,不同的是训练方法。Wav2vec 2.0 是在训练时将语音特征离散化作为自监督目标,而 HuBERT 则通过在 MFCC 特征或 HuBERT 特征上做 K-means 聚类,得到训练目标。

早期图文匹配记录
为了与配对文本的embedding序列对齐,图像V也将被表示为embedding向量的序列。将输入表示统一为两种模态的embedding序列。
早期做法:图片提取出来的区域特征,最好和文本的token特征在同一个level上。
为了生成图像的描述,模型被期望于推断图像中各种对象之间的复杂关系。
因此,许多工作设计了不同的视觉编码器来对这些关系和对象的属性进行建模。
ViLBERT[Lu et al.,2019]和LXMERT[Tan和Bansal,2019]等早期工作首先利用Faster RCNN[Ren et al.,2015]从图像中检测对象区域序列,然后将其编码为感兴趣区域(ROI)特征序列。使用ROI feature作为内容信息,将bounding box作为位置信息
此外,一些VL-PTM去掉了边界框(bounding box),并将图像编码为像素级网格特征(pixel-level grid features)。例如,pixel-BERT[huang等人,2020]和SOHO[huang等人,2021]放弃了更快的R-CNN,转而支持ResNet,这样视觉编码器就可以将图像作为一个整体来查看,避免了忽略一些关键区域的风险。
除了这些方法之外,许多工作都试图遵循ViT的成功[多索维茨基等人,2020年]利用transformer来提取视觉特征。在这个场景中,vl-ptm中的transformer的任务是建模图像中的对象关系。首先将一个图像分割成几个flattened 2D patches。然后将图像patch的embedding按顺序排列,以表示原始图像。
- ALBEF [Li等人,2021a]和SimVLM [Wang等人,2021b]将patch提供给ViT编码器,以提取视觉特征,从而导致了full-transformer VL-PTM的产生。
文本embedding + 图片ROI embedding
文本序列首先分为tokens,并与“[CLS]”和“[SEP]”token串联,表示为W = <[CLS],w1,…,wn,[SEP]>。每个令牌wj都将映射到一个词嵌入。
此外,在嵌入一词中添加表示位置的 pos embbding 和 嵌入模态类型的seg embbding,以获得wj的最终嵌入。
视觉部分:如何设计一个比较好的视觉embedding,去适应一个语言方面的预训练模型?
OSCAR
OSCAR将object tag作为信息进行输入,object是将信息转化为一个文本标签,构建了视觉信息和文本信息之间的桥梁,达到了视觉和文本的一致性。

问题:
1.需要额外训练一个roi提取模型,模型准确性影响预训练模型准确性
2.不同图片roi个数是不确定的,预训练模型需要相对固定roi个数导致信息丢失
3.roi数据集准备复杂,目标检测模型得到的都是矩形的目标,其不适合于不规则的物体,导致得到的bounding box中存在噪声。另外,除了bounding box以外,一些背景信息是无法提取出来的,相当于即存在噪声,也存在损失。对效果产生一些影响。
4.下游任务不一定适配用roi粒度特征,比如在一个domain预训练的目标检测模型,将其转换到另外的domain中,效果可能有相当大的gap,影响模型的效果。
文本embedding + 图片Grid embedding
为了解决region特征表示问题,提出Grid embedding方式表示图像数据。放弃ROI,转而使用cnn或者resnet抽取Grid Embedding,以便图像编码器可以将图像作为一个整体查看,避免忽视一些关键区域的风险。
Pixel-BERT
Pixel-Bert用cnn抽取图像Grid embbeding

SOHO
SOHO用resnet抽取Grid embedding

文本embedding + 图片Patch embedding
随着VIT的兴起,出现了patch based的特征提取,将一张图片分为若干patch,并且使用线性变化的方式对其进行编码。
图像首先被拆分为拍平为2D patch,然后序列化embdding图像的patch,来表示原始图像特征。模型是端到端表示且用的transformer架构可以并行化计算,所以VIT做patch推理速度会快很多

参考
多模态大模型入门指南-长文慎入【持续更新】 - 飞书云文档
AI多模态模型架构之模态编码器:图像编码、音频编码、视频编码_多模态编码器-CSDN博客
EVA-CLIP: Improved Training Techniques for CLIP at Scale
3. 多模态架构 - 飞书云文档
[2206.04769] CLAP: Learning Audio Concepts From Natural Language Supervision
[2004.00849] Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers
CVPR 2021 Open Access Repository
[2108.10904] SimVLM: Simple Visual Language Model Pretraining with Weak Supervision



