MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
摘要
论文介绍了MVBench,这是一个全新的多模态视频理解基准测试,旨在评估多模态大型语言模型(MLLMs)在视频理解方面的能力。
- 目前许多基准测试主要集中在静态图像任务的空间理解上,而忽视了动态视频任务中的时间理解。MVBench通过20个具有挑战性的视频任务来填补这一空白,这些任务无法通过单帧图像有效解决。
- 论文提出了一种新颖的静态到动态方法来定义与时间相关的任务,并将各种静态任务转化为动态任务,从而系统地生成各种视频任务,无需人工参与。
- 通过任务定义,研究者们自动将视频注释转换为多项选择的问答(QA),以评估每个任务。
- MVBench的构建高效且公平,避免了对LLMs的评分偏见。论文开发了一个强大的视频MLLM基线VideoChat2,并通过多样化的指令调整数据进行逐步多模态训练。
- 在MVBench上表明,现有的MLLMs在时间理解方面远未达到令人满意的水平,而VideoChat2在MVBench上的准确率超过了这些领先模型15%以上。
引言
多模态大模型(MLLM)通过在各种预先训练的LLM中嵌入视觉编码器,推动了视觉-语言学习任务的发展。一个很自然的问题是如何评估这些模型的视觉理解能力,这种评估对于确认其设计有效性和进一步改进它们以更广泛地理解开放世界的多种模态至关重要。
为了满足这一需求,一些基准测试已经被提出。其主要方法是在各种感知任务上构造QA式以评估MLLM性能。然而,这些基准主要集中在基于图像的理解上,所有的问题都是为静态图像的空间感知设计的(如图一spatial understanding所示)。因此他们难以评估动态视频中的时间演化,而这对于现实世界中的程式化活动的理解是十分重要的。

尽管最近已经有一些基准来评估视频中的时间感知任务,但它们要么只聚焦于非常基本的视频任务(如SEED-Bench中的行为识别和预测),要么聚焦特定领域(如FunQA)或受限的场景(如Perception Test中的室内场景)。因此,利用这些基准来对mllm的时间理解技能进行全面的评估是有限的。此外,它们通过劳动密集型标注收集,导致昂贵的人工成本。为了解决这些问题,本文提出了一个多模态视频理解基准(MVBench),它旨在全面评估开放世界中mllm的时间感知能力。与上面现有的基准相比,MVBench有两种不同的设计:
引入了从静态到动态的方法(a novel static-to-dynamic method):
为静态图像任务增加动态演化的时间上下文,得到了20个视频理解任务,这些任务需要对视频的时间维度有深入理解,涵盖了从感知到认知的广泛的时间理解技能。具体来说,作者在之前的多模态基准测试中使用静态图像任务作为定义参考。然后,用视频中的时间上下文来扩大这些静态任务的问题,例如,图像中的位置任务可以灵活地转换为视频中的移动方向任务(“男人在舞台上吗?”→“这个人的方向是什么?”)
引入自动标注范式,实现自动问答生成(Automatic QA Generation):
利用现有的视频基准测试和大型语言模型(LLMs),自动将视频注释转换为多项选择的问答对,用于评估MLLMs的性能。
选择了11个公共视频基准测试,并根据任务定义自动生成问题和答案选项。大大降低人工标注成本,涵盖了各种复杂的领域和不同的场景,从第一人称到第三人称的视角,以及从室内到室外的环境。这些基准为MVBench提供了基本事实,保证了评估的公平性和准确性,避免了LLM的有偏评分。
最后,在MVBench上对多个著名的MLLM进行全面评估,结果表明这些图像和视频MLLM在各项任务上还远不能让人满意。因此,作者还开发了一个视频MLLM基线模型,即VideoChat2。该模型桥接了大模型和一个强大的视频基础模型。随后,引入了一个具有广泛的多模态指令的渐进式训练范式,允许视频和语言之间的有效对齐。评估表明,VideoChat2在MVBench上显著领先表现最好的VideoChat15%,并且在视频对话和零样本QA基准上(video conversation and zero-shot QA benchmarks)取得了最先进的结果。
相关工作
MLLM
- 多模态LLM(MLLM)旨在增强多种模式的理解和生成能力。开创性模型如Flamingo和PaLM-E无缝地融合了文本和视觉,在一系列多模态任务中展现出优越性。
- 近期开源的LLM进一步加速了公共MLLM的出现。LLaVA,MiniGPT-4,InstructBLIP提出了一系列视觉指令微调数据。
- 除了文本和静态图像,一些研究开始挖掘LLM在视频模态中的潜力。VideoChat,VideoChat-GPT和Valley利用LLM生成视频指令微调数据以增强指令遵循能力。
- VideoChat2检验MLLM的基本的时间理解能力,为更优的MLLM提供有价值的设计理念。
Benchmark
传统的视觉语言(VL)benchmark集中在多模态检索和视觉QA。MLLM的发展催化了评估集成视觉语言任务的benchmark。
LVLM-eHub通过与图像相关的查询提供了一个交互式的模型比较平台。其他基准如OwlEval [94], MME [17], SEED-Bench [37],
MM-Vet [97], and MMBench 强调全面的VL能力,引入仅超越模型结构的评估指标。
视频领域有Perception Test,测试了多模态视频感知和推理;VideoChatGPT量化了从视频输入中生成对话的能力;FunQA通过反直觉和幽默的内容来限制视频推理。
与现有的视频基准相比,MVBench涵盖了广泛的时间任务,强调了对时间敏感的视频和对公共注释的有效使用,并对mllm的时间理解进行了全面的评估。
MVBench
时间任务定义
静态到动态方法,使静态任务适应动态目标。使用静态图像的空间理解任务作为系统地设计从感知到认知的时间任务的参考。从图像benchmark里总结了上述9项空间理解任务,再思考延伸出20项时间理解任务如下:
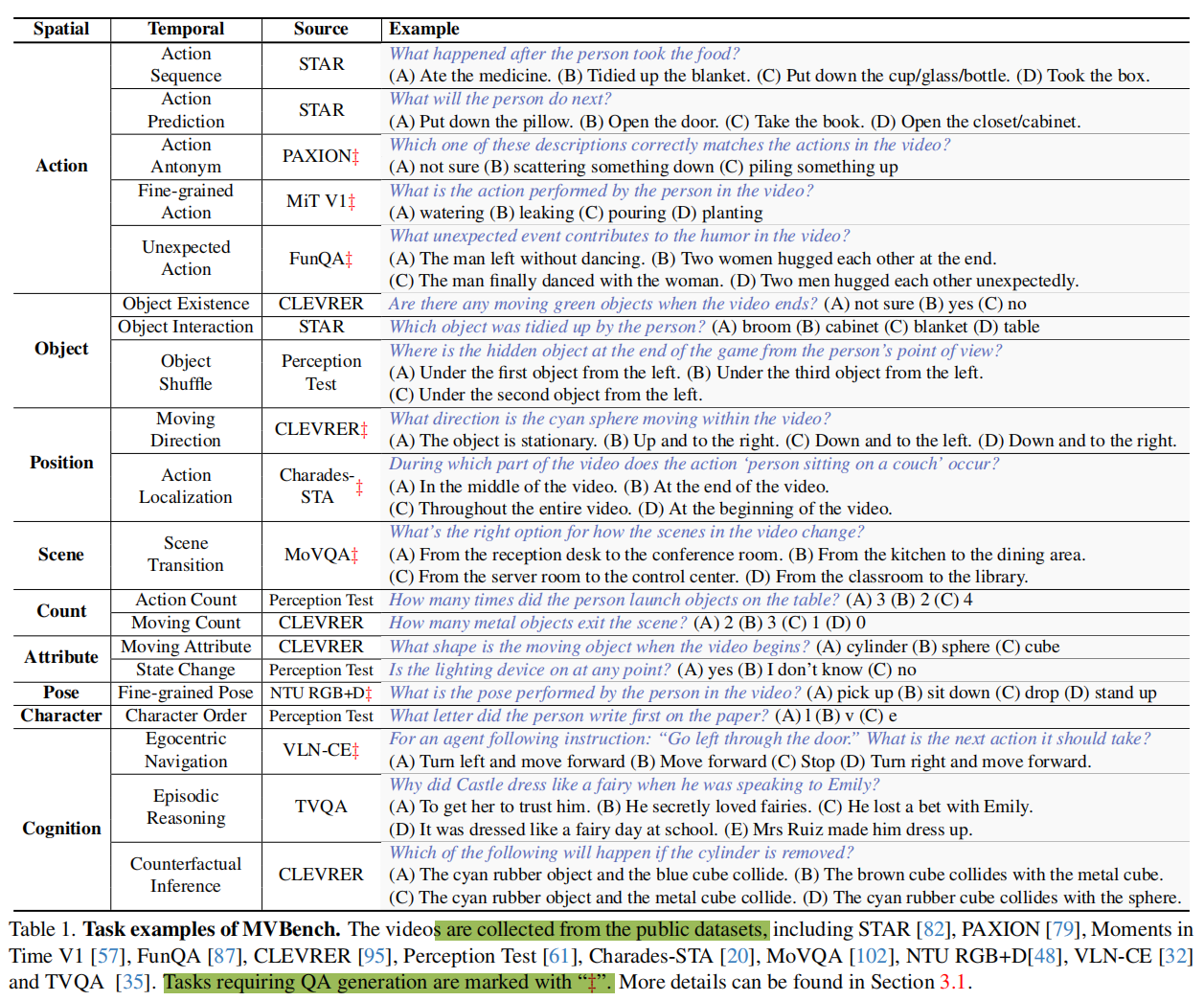
Action. (1) Action Sequence: 检索在特定操作之前或之后发生的事件。 (2) Action Prediction: 根据当前操作推断后续事件。(3) Action Antonym: 将正确的操作与两个错误的操作区分开来。 (4) Fine-grained Action: 从一系列类似选项中确定准确的操作。 (5) Unexpected Action: 检测以幽默、创意或magic为特征的视频中的surprising actions。
Object. (6) Object Existence: 确定特定事件期间是否存在特定对象。 (7) Object Interaction: 标识参与特定事件的对象。 (8) Object Shuffle: 在遮挡游戏中定位对象的最终位置。
Position. (9) Moving Direction: 确定特定对象移动的轨迹。 (10) Action Localization: 确定发生特定操作的时间段。
Scene. (11) Scene transition: 确定视频中场景的过渡方式。
Count. (12) Action Count: 计算特定操作已执行的次数。(13) Moving Count: 计算执行了特定操作的对象数。
Attribute. (14) Moving Attribute: 确定特定移动对象在给定时刻的表现/外观。 (15) State Change: 确定某个对象的状态在整个视频中是否发生变化。
Pose. (16) Fine-grained Pose: 从一系列类似选项中确定准确的姿态类别。
Character. (17) Character Order: 确定字母的显示顺序。
Cognition. (18) Egocentric Navigation: Forecast the subsequent action, based on an agent’s current navigation instructions. 根据agent的当前指令预测后续操作。(19) Episodic Reasoning: 对电视连续剧一集中的人物、事件和对象进行推理。 (20) Counterfactual Inference: 思考如果发生某个事件会发生什么。
自动QA生成
在时间任务定义的指导下,为每个任务收集和标注视频。具体来说,图2中设计了一个自动QA生成范式,它有效地将开源视频数据标注转换为评估mllm的多项选择QA。
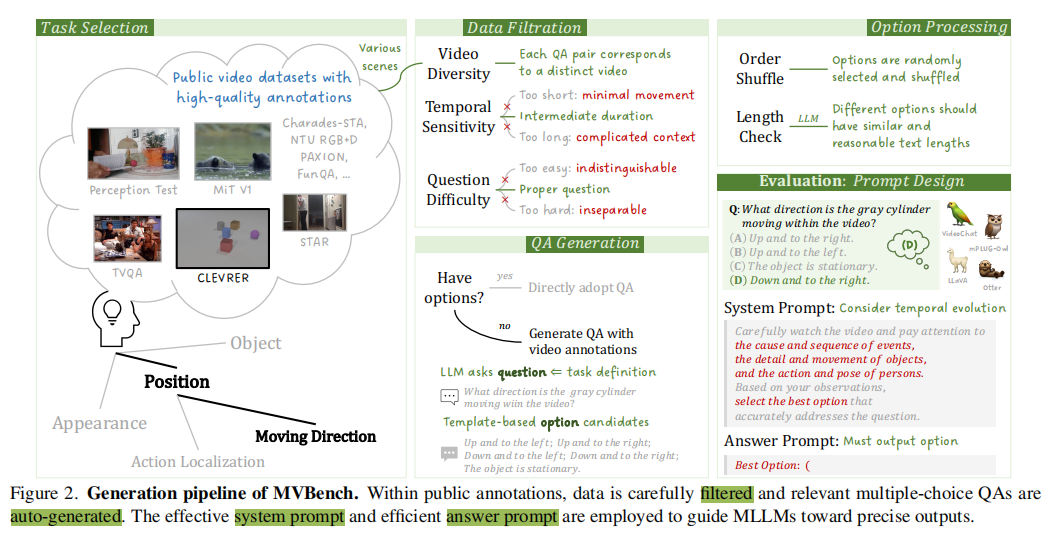
数据过滤
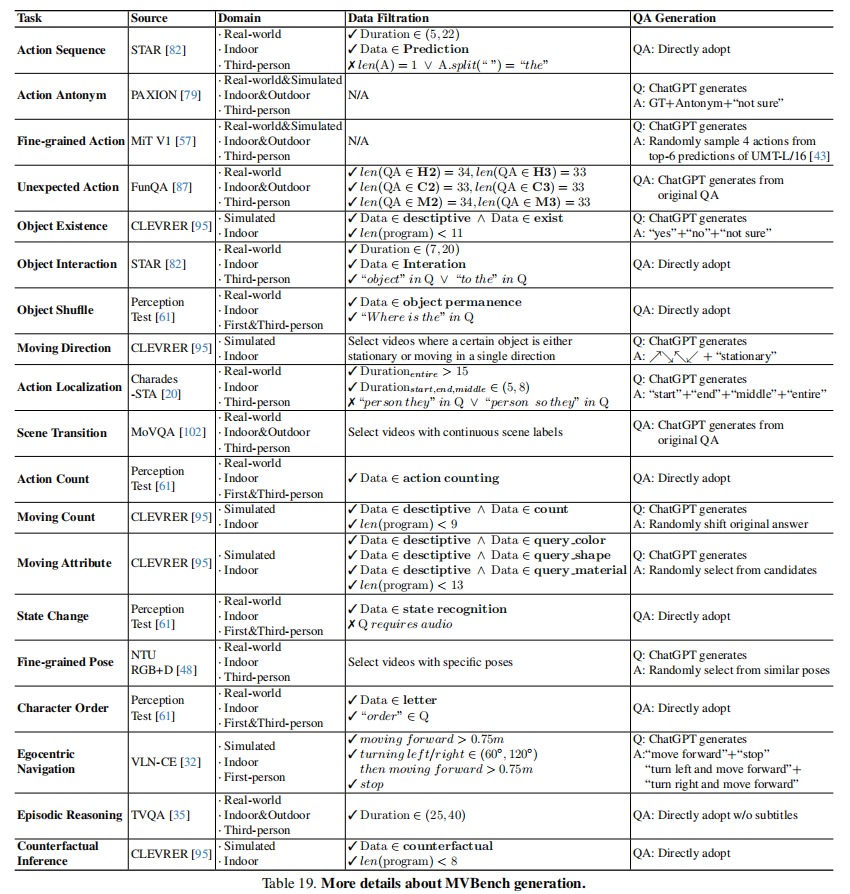
- 考虑到视频多样性,仔细选择了11个视频数据集,覆盖广泛的领域和场景,尽可能地对不同的视频设计独立的问题;
- 考虑到时序敏感性,采取每个数据集中合适的视频长度(5~35秒),过短的视频往往动作幅度较小,而过长的视频包含过于复杂的上下文,问题过难会导致无法区分不同模型的能力;
- 考虑到问题复杂度,采取难度适中的问题,如在CLEVRER中,采取适当条件限制(排除需要超过10个条件的问题)的问题;如对于时间定位问题,不采用精细的秒级别定位任务,而采用粗略的时间段定位,如发生在视频的开始、中间还是结束。
QA生成
之后便来到生成多选题的问题及选项,对于已有多选QA的数据,可以直接采用。但对于没有多选QA的数据,利用ChatGPT来自动生成多选QA格式。
- 对于问题,根据任务定义,让ChatGPT生成3-5个对应的问题随机选其一;
- 对于选项,设计两种策略:(a)基于模版的构造,设计固定的选项模版,从ground truth annotations中构建候选集(例如,针对Action Antonym任务,包含正确选项,相反选项,不确定选项;在Moving Direction任务中,包含up, down, left, right四个方向以及固定状态),结合GPT匹配生成;(b)基于LLM的生成,针对类似Unexpected Action任务,将原始QA输入ChatGPT,并让ChatGPT生成新的问题以及选项。使用多选格式而不是开放格式,保证评估的正确性和公平性(如果引入开放答案,可能导致评估偏差或人工干预)。最终,本文为每个时间理解任务产生了200对多项选择QA对。
问题选项处理
对于每个问题,从可用的候选集中随机抽样三到五个答案选项,调整选项顺序以加强评估的稳健性。为了防止答案泄露,进一步使用LLM保证一个问题的所有答案选项具有相似和合理的长度。
evaluation的prompt设计
对于具体的评测,作者设计了合理的system prompt和高效的answer prompt,其中system prompt用于激发模型的时间理解能力(见图2右下角),这一提示鼓励mllm仔细检查视频内容来回答问题,通过注意诸如人的动作和姿势,以及物体运动的细节和动作等因素。
Carefully watch the video and pay attention to the cause and sequence of events, the detail and movement of objects and the action and pose of persons. Based on your observations, select the best option that accurately addresses the question.

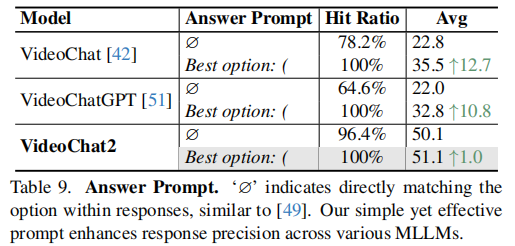
由于对话模型的输出倾向于输出完整的句子,难以直接输出选项,如何从对话的输出中抽取选项也成了一个难题。MMBench中使用多个模版匹配选项,对于无法匹配的选项,使用ChatGPT进行抽取。然而这种抽取效率低下, 和人类相比,只取得了87%的对齐率。SEED-Bench则比较不同选项的似然,选择最大似然对应的选项作为最终答案,这种方式仍不够直接,并且需要人为修改不同模型的forward函数。本文采取一种更简单直接的方式,通过构造带括号”()”的选项,接着显著地通过控制对话模型输出的起始字符”Best Option: (“,即answer prompt来指导mllm的选项生成,在本文实验里,这种方式不仅可以100%地保证不同模型输出选项,同时能够提高答案的准确率。
VideoChat2
作者在MVBench上评估了现有的图像和视频对话模型(见实验部分表2),结果发现即便是最佳的视频对话模型VideoChat,性能与随机猜测相比也相差无几。分析原因可以发现,目前的视频对话模型存在两大缺陷:
- 缺乏多样的指令微调数据:由于视频数据难以标注,开源的指令微调数据仍规模较小;
- 缺乏强视频编码器:目前主流的视频编码方法仍是选强多模态图像编码器CLIP-ViT,在上面进行时序改良,这难以本质地处理时序上的理解。
为了弥补这些差距,本文开发了一个健壮的视频mllm基线模型VideoChat2。
指令微调数据
为了解决缺乏多样指令调优数据的问题,引入了如图3所示的丰富数据,其中包含了来自34个不同来源的2M个样本。效仿VideoChat和VideoLlama,在指令集中包含了图像和视频数据,以改进训练。
受M3IT的启发,本文以统一的格式重新组织了所有的数据样本,如图3的右下角所示。涉及两个key分别是{“image” or “video”}及{“QA”}。QA中包含instruction,question和answer。M3IT中要求研究人员为每一个数据集设计10组instruction,本文使用ChatGPT来生成指令(根据dataset_description,task_description,instruction_example)来生成。

整个指令调优数据集可以粗略地分为6类:
- conversation:提高多轮对话能力。从LLaVA和VideoChat中收集对话数据;从VideoChatGPT中集成caption数据转为对话格式。
- simple caption:提供基本的视觉描述能力。使用广泛使用的COCO和WebVid,以及来自YouCook2的一级视频字幕。
- detailed caption:丰富视频细节的全面理解能力。利用MiniGPT-4, LLaVA和VideoChat的详细caption数据。
- VQA:提高视觉问答能力。
- reasoning:提高不同的推理能力。
- classification:提高对目标识别和动作识别的鲁棒性。
渐进式跨模态训练范式
促进mllm的另一个关键因素是如何有效地弥合视觉和语言表征之间的语义差距。为了解决这个问题,作者采用了如图4所示的渐进式多模态训练范式。
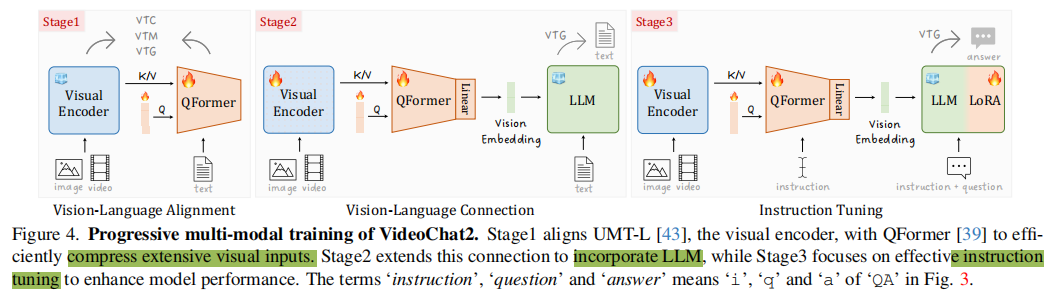
阶段1:视觉-语言对齐
为了平衡效率和有效性,冻结视觉编码器,训练灵活的QFormer。它将冗余的视觉令牌(visual tokens)压缩为更少的查询令牌(query tokens),并通过多模态损失(即BLIP2训练的三种损失:视觉文本对比学习(VTC)、视觉文本匹配(VTM)和基于视觉的文本生成(VTG))将这些查询与文本令牌对齐。与BLIP2不同,本文选择了预训练过的UMT-L作为视觉编码器,因为它具有强大的时空表示学习能力。此外,训练CC3M和CC12M的15M图像字幕,WebVid-10M的10M视频字幕,以增强视频语言建模。
阶段2:视觉-语言连接
在初始对齐之后,将视觉编码器与预先训练过的llm连接起来,以构建视觉-语言理解能力。和BLIP2类似,作者应用一个线性投影来进一步转换查询标记,并将投影的标记与文本标记连接到LLM中,用于基于视觉的标题生成(即VTG)。与BLIP2不同的是,视觉编码器在这个阶段是非冻结的,以便更好地与LLM对齐。除了上述第一阶段的训练数据外,这一阶段进一步引入了2M图像caption(COCO、Visual Genome和SBU)和10M视频caption(InternVid),以丰富caption的多样性。
阶段3:指令微调
使用前面所述的指令微调数据进行微调。在冻结的LLM上进行lora低轶微调,通过VTG损失与视觉编码器和QFormer一起调整。此外,借鉴InstructBLIP,作者在QFormer中也插入了instruction,用于提取与指令相关的视觉token作为LLM的输入。
实验
- 视觉编码器:UMT-L
- 大模型:Vicuna-7B
- 借鉴BLIP2,使用带有预训练Bert_base的QFormer,阶段1:32个query,阶段2和3:64个query
- 训练时:每个视频4帧,阶段1有10个epoch,阶段2有1个epoch;第3阶段转为8帧视频的3个epoch。
- 评估时:输入了16帧的视频,并提供了详细的prompt,以获得更好的结果。
MVBench整体评估
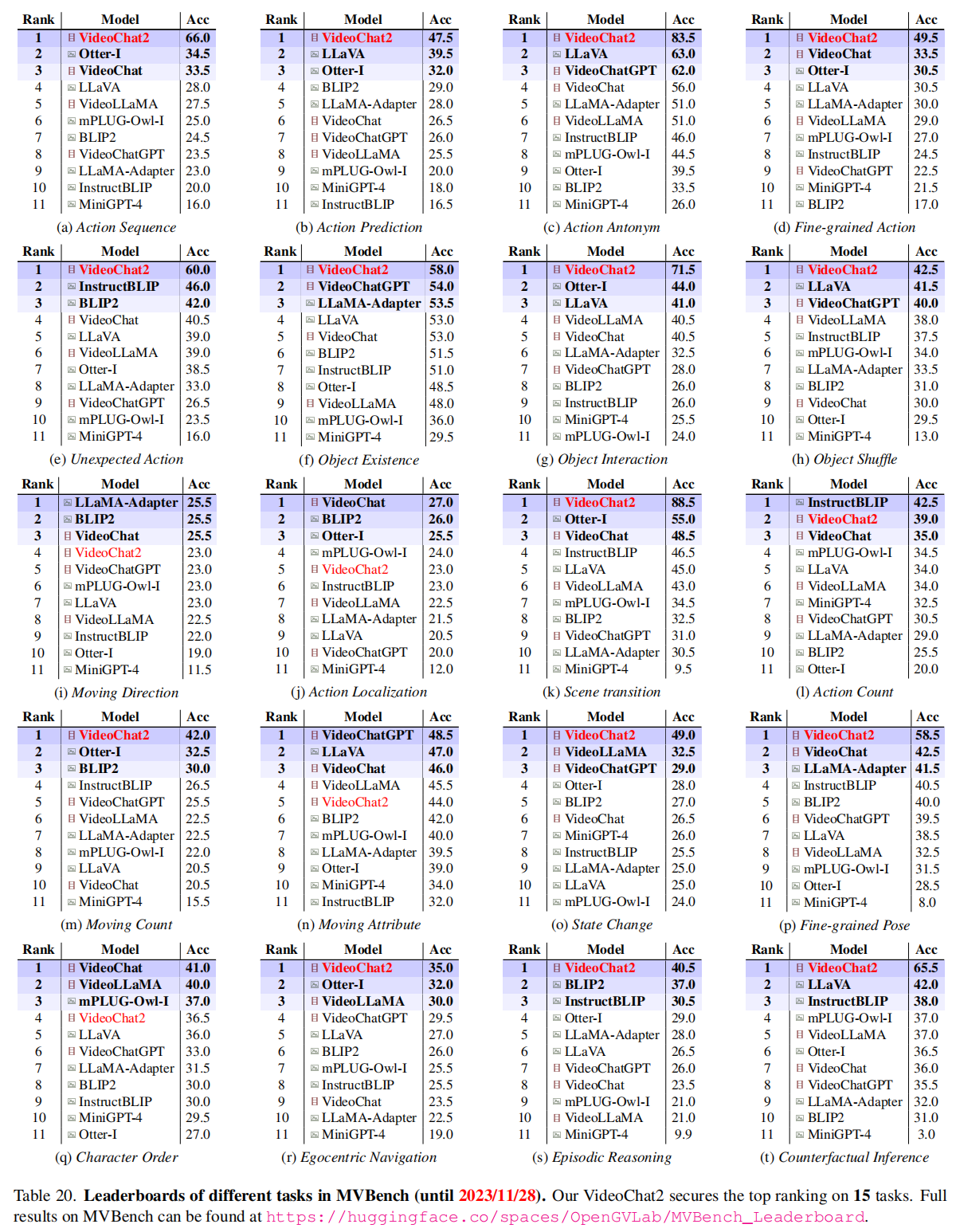
表2展示了在MVBench上的评估结果,现有的图像和视频MLLM表现不佳。VideoChat2在15个任务上取得最佳性能,特别是在动作、物体、场景、属性和姿势识别(action, object, scene, attribute, and pose recognition)等方面表现出色。但也能看到,它在处理移动方向、动作定位、计数等任务上仍有不足。最近的一些图像对话模型,已经开始引入grouding数据增强相关能力,这也是后续视频对话模型可以突破的方向。
值得一提的是,这里的VideoChat2_text,输入为空白视频,即QFormer输出噪声embedding,模型仅靠文本上下文进行输出,结果居然与前述最强模型接近。这个结果也揭示了目前对话模型,在时序理解任务上,仍有很大的不足。
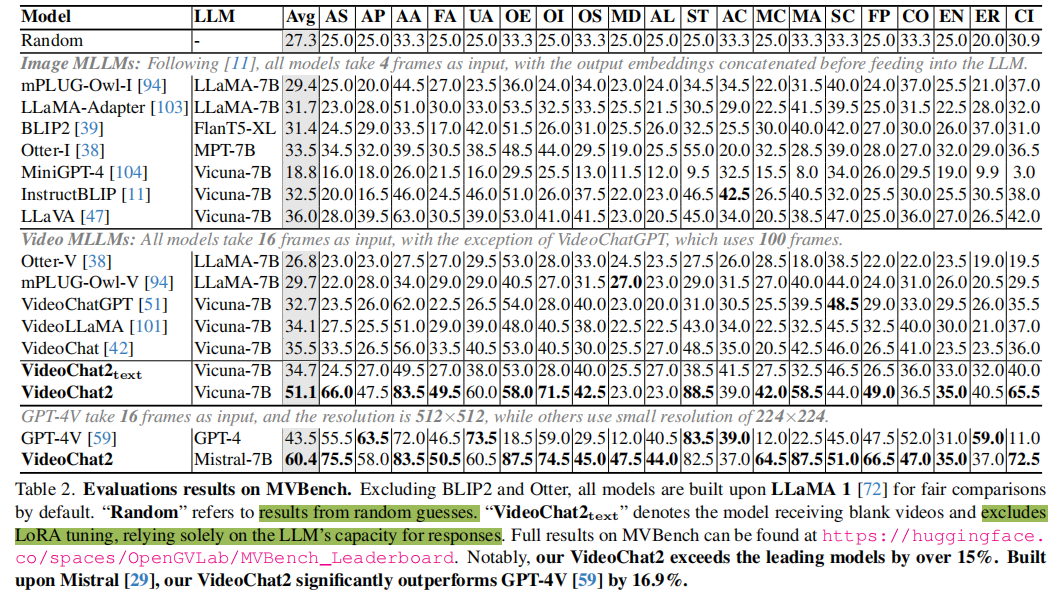
此外,作者还评估了功能强大的GPT-4V。结果表明,GPT-4V取得了令人满意的性能,证明了其时间理解能力,而VideoChat2超过了它,准确率提高了16.9%。这进一步强调了模型在处理更广泛的任务方面的优越性。
更多比较
仿照Video-chatgpt,本文使用ChatGPT在视频mllm之间进行定量比较。
(1)视频对话:表3显示了在Video-chatgpt中的基准上的结果。与VideoChatGPT相比,我VideoChat2在所有指标上都表现出了卓越的性能,在信息正确性、上下文和时间理解方面都取得了明显的进步。这表明,VideoChat2更擅长理解空间和时间细节,并提供一致和可靠的反应。
(2)零样本视频QA:表4列出了视频QA数据集(Video question answering via gradually refined attention over appearance and motion. 及 Activitynet-qa: A dataset for understanding complex web videos via question answering.)上的结果,VideoChat2超过了所有其他方法,特别是在理解ActivityNet中的长视频方面。
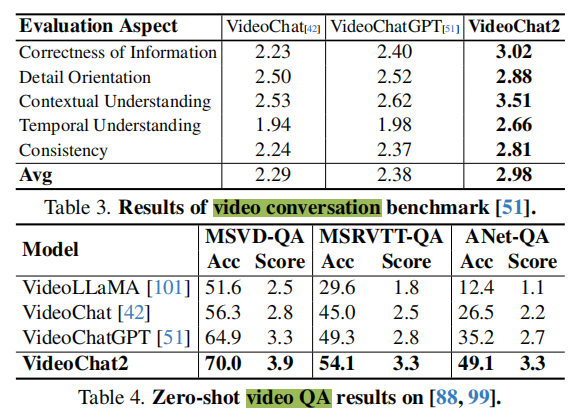
图5中进一步进行了定性比较,其中VideoChat2提供了一个精确而彻底的响应。

消融实验
- 指令微调数据:随着数据多样性和数量的增加,性能显著提高,其中视频数据的贡献大于图像数据(50.5% vs. 42.1%)。考虑到COCO和WebVid的简单caption数据中潜在的冗余性,对它们进行了随机压缩。这只对性能产生很小的影响(50.7% vs. 51.1%),但加速了微调1.7×。
- 架构:(1)视觉编码器:表6中,使用本文构建的指令数据集+EVA-CLIP-g获得与原始VideoChat中模型相比6.9%的性能提升(42.4% vs 35.5%)。用UMT-L进行的进一步替换额外提高了6.2%的性能;(2)LLM:合并更大和更新的llm在结果中提供了一个最低限度的改进,这表明MVBench主要依赖于视觉编码器。值得注意的是,LoRA不断提高结果,可能是由于它增强了模型指令遵循的能力。
- 训练方法:只微调线性投影层,冻结视觉编码器和QFormer(参考MiniGPT-4),结果不佳(见表7,38.5%)。解冻Qformer,获得额外8.5%的性能提升;解冻视觉编码器获得更多的提升。
- 提示设计:system prompt揭示了任务需求,增强任务完成能力。提取选项时,不同于不稳定的ChatGPT-extracting methods,和更耗时的log-likelihood comparisons,本文使用一种简单有效的answer prompt。表9证明了它能够准确地捕获选项,并提高了跨各种mllm的响应精度。VideoChat2即使没有提示,也能更好地按照指令返回选项。

对于QFormer,在第二第三阶段引入了额外可学习的token,用于和LLM对齐,结果显示额外引入64个token效果最佳。并且在QFormer中插入instruction引导,结果提升明显,而继续插入question则有副作用。过长的上下文(“指令+问题”)可能很难实现QFormer的信息提取。
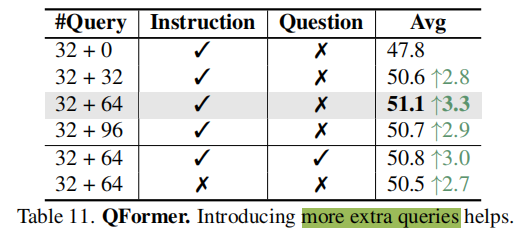
对于训练和测试输入,实验表明训练使用8帧,测试使用16帧效果较好,训练开销也较小。但使用大分辨率,在MVBench上并没有提升,即增加分辨率并不能提高性能;然而,增加帧数可以提高,侧面验证了MVBench更依赖于模型的时序理解能力。
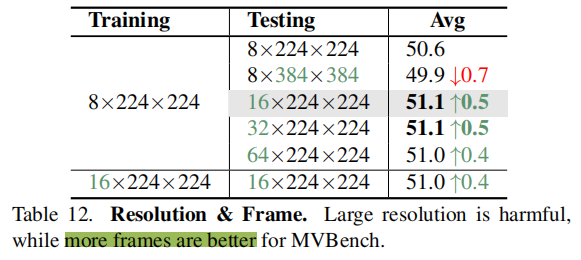
定性结果

总结
本文介绍了MVBench,一个评估mllm的时间理解能力的综合基准。此外,本文针对现有视频对话模型的缺陷,构造了更丰富的指令微调数据,提出了一个健壮的视频MLLM基线模型,VideoChat2,在MVBench上比领先的模型表现超过15%。我们广泛的分析进一步指导了MLLM的时间理解的设计。
==项目配置==
数据相关
标签
以JSON格式提供了一个包含2M数据注释的综合数据集。annotation示例如下:
[{"image": "two_col_103562.png", "QA": [{"i": "Examine the chart's visual features and the underlying data table closely to provide an accurate answer to the question.", "q": "As of 2021, how many championship titles had Ferrari won?", "a": "The answer is 16."}]},
{"image": "two_col_2954.png", "QA": [{"i": "Analyze the visual and data components of the chart carefully and answer the question based on both the graphical representation and numerical data provided.", "q": "What game topped the charts with 512.3 million hours watched on Twitch in the first half of 2019?", "a": "The answer is League of Legends."}]}, .....视频分类:
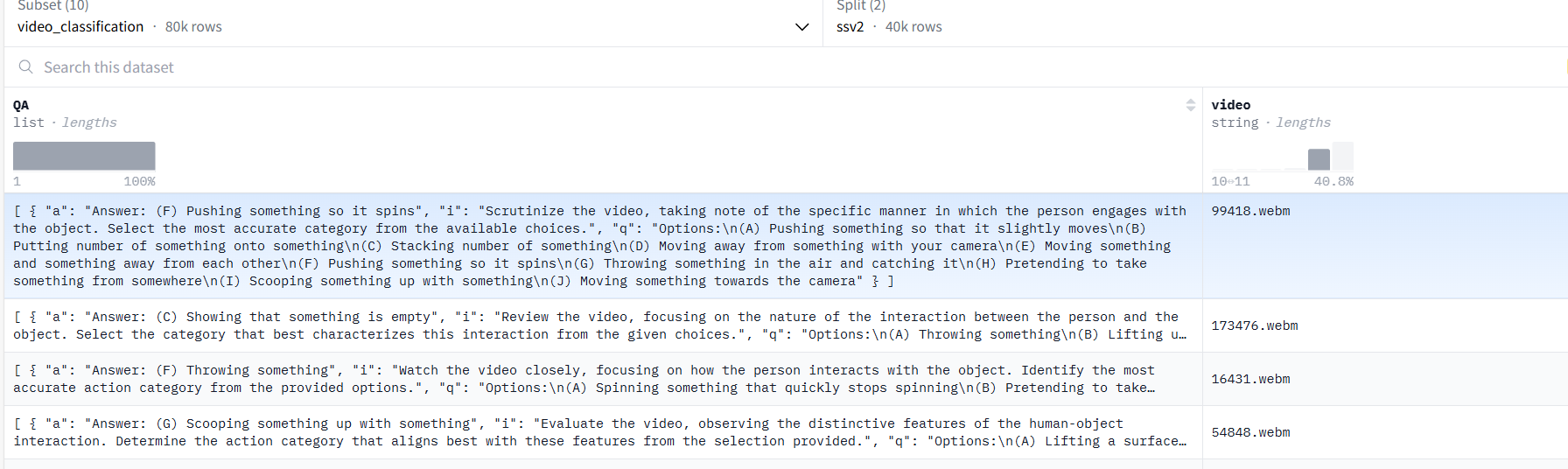
视频caption生成:
数据源
图像数据源:
M3IT(https://huggingface.co/datasets/MMInstruction/M3IT),通过以下方式过滤出质量较低的数据:
- 纠正拼写错误:大多数标点符号使用不正确的句子都得到了纠正。
- 改写错误答案:ChatGPT生成的一些回复,如“对不起,…”,是不正确的。这些用GPT-4重新表述。
视频数据源:
- VideoChat(https://github.com/OpenGVLab/InternVideo/tree/main/Data/instruction_data):基于InternVid创建了额外的指令数据instruction,并使用GPT-4压缩现有数据。
- VideoChatGPT(https://github.com/mbzuai-oryx/Video-ChatGPT/tree/main/data):原始caption数据基于相同的VideoID转换为对话数据。
- Kinetics-710(https://github.com/OpenGVLab/UniFormerV2/blob/main/DATASET.md)和SthSthV2([Datasets](https://www.qualcomm.com/developer/artificial-intelligence/datasets)):选项候选是根据UMT前20名的预测生成的。
- NExTQA(https://github.com/doc-doc/NExT-QA):原始句子中的拼写错误已被纠正。
- CLEVRER(https://clevrer.csail.mit.edu/):对于单项选择题,只使用了与颜色/材料/形状有关的问题。多项选择题则利用了所有数据。
- WebVid(https://maxbain.com/webvid-dataset/):选择非重叠数据进行字幕和QA。
- YouCook2(https://youcook2.eecs.umich.edu/):根据官方的密集caption,原始视频被截断。
- TextVR([callsys/TextVR: PR 2024] A large Cross-Modal Video Retrieval Dataset with Reading Comprehension):所有数据均未经修改。
- TGIF(YunseokJANG/tgif-qa: Repository for our CVPR 2017 and IJCV: TGIF-QA):只使用了TGIF${frame}$和TGIF${Transition}$子集。
- EgoQA(Egocentric 4D Perception (EGO4D)):一些以自我为中心的QA是从Ego4D数据中生成的。
对于所有数据集,任务指令都是使用GPT-4自动生成的。
训练
conda配置
- git clone拷贝远程仓库超时:设置全局代理,clash打开允许局域网接入。注意代理ip是本机电脑ip,不是服务器ip。
准备训练环境:
conda create -n videochat2 python=3.9
conda activate videochat2
pip install -r requirements.txt注意这里pip install可能是系统的pip,而不是环境的pip,会导致当前虚拟环境并没有相应依赖:如何在conda环境中正确地使用pip_在conda构建的虚拟环境下可以进行pip操作吗-CSDN博客
CondaHTTPError: HTTP 000 CONNECTION FAILED
- conda换清华源:
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --append channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/fastai/
conda config --append channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --append channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
conda config --set show_channel_urls yes修改conda配置信息:
vim ~/.condarc,删除 - defaults(重要!!) 增加 ssl_verify: false。保存后重新创建环境ModuleNotFoundError: No module named ‘torch’
阶段1训练
Download UMT-L/16 model and set pretrained in stage1_config
bash scripts/videochat_vicuna/run_7b_stage1.shAttributeError: module ‘numpy’ has no attribute ‘float’.
- 重新安装
numpy。出现这个问题是因为np.float从1.24起被删除。所用的代码是依赖于旧版本的Numpy。您可以将你的Numpy版本降级到1.23.5.
- 重新安装
conda install numpy==1.23.5linux环境下 python import不了自定义的包,即无法找到项目路径。
- 手动导入项目根路径:
import sys , os
base_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(base_dir)- 衍生报错:Traceback (most recent call last): File “/home/bailey/Code/wyf/Ask-Anything/video_chat2/tasks/train_qformer.py”, line 298, in <module>。。。 File “/home/bailey/Code/wyf/Ask-Anything/video_chat2/utils/config_utils.py”, line 180, in setup_main Config.dump(config, os.path.join(config.output_dir, “config.json”))。。。。**TypeError: Object of type module is not JSON serializable Traceback (most recent call last):**。。。
- 本质是在
config对象当中包含了对 Python 模块对象的引用,而这些引用与正在执行的操作(JSON 序列化和深拷贝)不兼容。因此需要去掉config对象中的sys和os这两个key对应的元素(这俩key的value都是module)
- 本质是在
def filter_module_refs(obj):
if isinstance(obj, dict):
# 对于字典类型,遍历每个键值对,对值进行递归处理
return {k: filter_module_refs(v) for k, v in obj.items() if not isinstance(v, types.ModuleType)}
elif isinstance(obj, list):
# 对于列表类型,遍历每个元素,对元素进行递归处理
return [filter_module_refs(element) for element in obj if not isinstance(element, types.ModuleType)]
else:
# 如果不是字典也不是列表,直接返回该元素(非模块类型的都返回)
return obj if not isinstance(obj, types.ModuleType) else None衍生报错:在train_former197行set up model内部进行deepcopy时,报错 y[deepcopy(key, memo)] = deepcopy(value, memo)
File “/home/bailey/anaconda3/envs/videochat2/lib/python3.9/copy.py”, line 161, in deepcopy
rv = reductor(4)
TypeError: cannot pickle ‘module’ object。。。- 本质还是因为python 试图序列化一个模块对象,但模块对象是不可序列化的。
- 解决思路:在train_former.py下改了很多次config对象都没有用,最后在utils/config_utils.py的Config.dump()前去掉config对象中的模块对象就解决了。
- 且这样改了以后,Found module object under key的提示会出现两次,也就是两个子线程分别去掉了模块对象,之后才在主线程中dump
# 这个判断module object的操作放在判断main进程前面
for key, value in config.items():
if isinstance(value, types.ModuleType):
print(f"Found module object under key: {key}")
config[key] = ''
if is_main_process():
setup_output_dir(config.output_dir, excludes=["code"])
setup_logger(output=config.output_dir, color=True, name="vindlu")
# logger.info(f"config: {Config.pretty_text(config)}")
Config.dump(config, os.path.join(config.output_dir, "config.json"))
return configapt-get install报错文件尺寸不符:apt-get换国内镜像源
libcusparse.so.11: cannot open shared object file: No such file or dir报错:【最快解决方案】安装torch-geometric报错 libcusparse.so.11: cannot open shared object file: No such file or dir_oserror: libcusparse.so.11: cannot open shared obj-CSDN博客
- 先
locate libcusparse.so.11找一下服务器有没有对应文件,有的话直接复制到这个博客中说的路径下(发现bailey机器上libcusparse.so.11只有20kb,有一个libcusparse.so.11.7.4.91文件200+mb,把这俩一起复制过去也不行,最后用的llama项目虚拟环境下200+m的后缀11的文件替换就行了
- 先
Failed to load image Python extension: libtorch_cuda_cu.so
- pytorch和torchvision的版本问题
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 3938937) of binary:
- 本来以为是PyTorch 的 CUDA 版本与系统上的 CUDA 版本不兼容的问题。从原来的
torch==1.13.1+cu117换成torch==1.12.0+cu113,但问题依然存在。(系统cuda为11.5)
- 本来以为是PyTorch 的 CUDA 版本与系统上的 CUDA 版本不兼容的问题。从原来的
pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 torchaudio==0.12.0 --extra-index-url https://download.pytorch.org/whl/cu113- 而且torch降低为1.12以后,与peft冲突(peft 0.4.0 requires torch>=1.13.0),且bitsandbytes和cuda版本又会不匹配
- 最后torch又装回1.13.1了,cuda11.7(各种版本下载对应:Previous PyTorch Versions | PyTorch)
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117- wandb:命令行输入
wandb login在官网登录,并将api key复制回命令行
bert相关
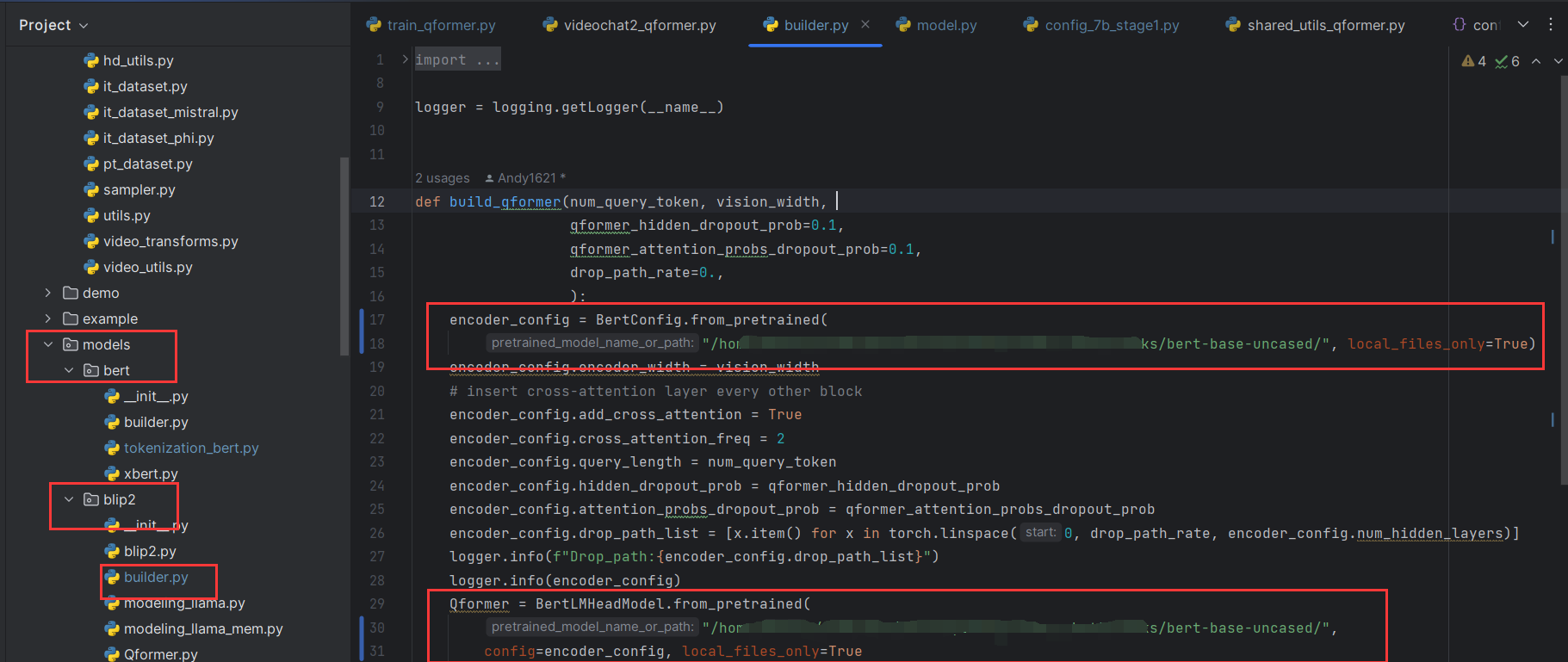
在shared_utils_qformer中setup_model时,BertTokenizer.from_pretrained(config.model.text_encoder.pretrained, local_files_only=True)报错 OSError: Can’t load tokenizer for ‘bert-base-uncased’. If you were trying to load it from ‘https://huggingface.co/models‘, make sure you don’t have a local directory with the same name. Otherwise, make sure ‘bert-base-uncased’ is the correct path to a directory containing all relevant files for a BertTokenizer tokenizer.
原因:主机或服务器不能访问https://huggingface.co/页面,因此不能下载相应的权重。解决方法:手动下载文件到本地。
下载后放到tasks/bert-base-uncased路径,修改configs/model.py
TextEncoders["bert"] = dict( name="bert_base", pretrained="/home/…………/tasks/bert-base-uncased/", ………………
**’BertTokenizer’ object has no attribute ‘vocab’**:修改models/bert/tokenization_bert.py文件,将self.vocab = load_vocab(vocab_file)从init方法后移到前面去(参考:Debug:AttributeError: ‘BertTokenizer‘ object has no attribute ‘vocab‘_attributeerror: ‘berttokenizer’ object has no attr-CSDN博客)
OSError: We couldn’t connect to ‘https://huggingface.co‘ to load this file, couldn’t find it in the cached files and it looks like bert-base-uncased is not the path to a directory containing a file named config.json.
使用 .from_pretrained(“xxxxx”)方法加载,本地加载bert需要修改两个地方,一是tokenizer部分,二是model部分:
step1、导包: from transformers import BertModel,BertTokenizer
step2、载入词表: tokenizer = BertTokenizer.from_pretrained(“./bert_localpath/“) 这里要注意!!除了你自己建的文件夹名外,后面一定要加个/,才能保证该方法找到咱的vocab.txt
step3、载入模型: bert = BertModel.from_pretrained(“./bert_localpath”) 然后,这个地方又不需要加上/
数据集
—- 最好别用这个下,开了多线程电脑会卡,内存可能不够
Dataset Zoo — LAVIS documentation
img2dataset/dataset_examples/cc3m.md at main · rom1504/img2dataset
数据处理
dataset/init.py
def get_media_type(dataset_config):
if len(dataset_config) >= 3 and dataset_config[2] == "video":
return "video" # 视频数据集,由标注+源数据+类型标记video构成
elif len(dataset_config) >= 3 and dataset_config[2] == "text":
return "text"
else:
return "image" # 图像数据,list里只有标注+源数据dataset config.json
"train_file": [
[
"annotation/anno_pretrain/webvid_10m_train.json",
"annotation/videos_images/webvid_10m",
"video"
],
[
"annotation/anno_pretrain/cc3m_train.json",
"annotation/videos_images/cc3m"
]
],
"test_file": {
"msrvtt_1k_test": [
"annotation/anno_pretrain/msrvtt_test1k.json",
"annotation/videos_images/MSRVTT_Videos",
"video"
]
},
"test_types": [
"msrvtt_1k_test"
],pt_dataset.py
class PTImgTrainDataset(ImageVideoBaseDataset):
media_type = "image"
def __init__(self, ann_file, transform, pre_text=True):
super().__init__()
if len(ann_file) == 3 and ann_file[2] == "video":
self.media_type = "video"
self.media_name = "key" # 自己做的数据集,json文件里面对应图名称的是key
else:
self.media_type = "image"
self.media_name = "key"
self.label_file, self.data_root = ann_file[:2]
logger.info(f"=========label file : {self.label_file}, data root : {self.data_root}")
# 对于第一阶段训练, =========label file : annotation/anno_pretrain/cc3m_train.json, data root : annotation/videos_images/cc3m =========label file : annotation/anno_pretrain/webvid_10m_train.json, data root : annotation/videos_images/webvid_10m
logger.info('Load json file')
with open(self.label_file, 'r') as f:
self.anno = json.load(f)
self.num_examples = len(self.anno)
self.transform = transform
self.pre_text = pre_text
logger.info(f"Pre-process text: {pre_text}")
def get_anno(self, index): # 针对自己做的数据集做一些特定处理
if "cc3m" in self.label_file:
filename = self.anno[index][self.media_name] + ".jpg"
elif "webvid" in self.label_file:
filename = self.anno[index][self.media_name] + ".mp4"
else:
filename = self.anno[index][self.media_name]
caption = self.anno[index]["caption"]
anno = {"image": os.path.join(self.data_root, filename), "caption": caption}
return annoevaluate text-encoder修改(原来是None):
# tasks/retrieval_utils
text_encoder = model.get_text_encoder()
# models/videochat2_qformer.py
def get_text_encoder(self):
return build_bert(self.config, False, False)
# models/bert/builder.py
def build_bert(model_config, pretrain, checkpoint):
"""build text encoder.
Args:
model_config (dict): model config.
pretrain (bool): Whether to do pretrain or finetuning.
checkpoint (bool): whether to do gradient_checkpointing.
Returns: TODO
"""
bert_config = BertConfig.from_json_file(model_config.text_encoder.config)
bert_config.encoder_width = model_config.vision_encoder.d_model
bert_config.gradient_checkpointing = checkpoint
bert_config.fusion_layer = model_config.text_encoder.fusion_layer
if not model_config.multimodal.enable:
bert_config.fusion_layer = bert_config.num_hidden_layers
if pretrain:
text_encoder, loading_info = BertForMaskedLM.from_pretrained(
model_config.text_encoder.pretrained,
config=bert_config,
output_loading_info=True,
)
else:
text_encoder, loading_info = BertModel.from_pretrained(
model_config.text_encoder.pretrained,
config=bert_config,
add_pooling_layer=False,
output_loading_info=True,
)
return text_encoder
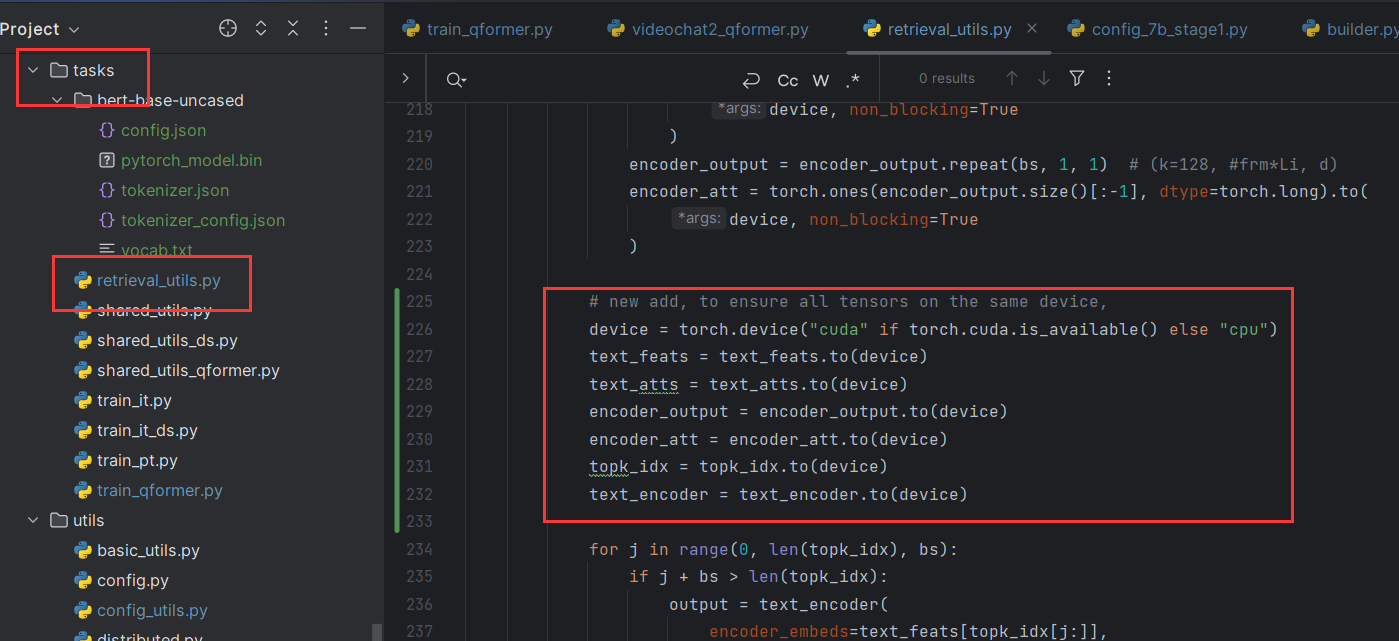
张量设备
训练时
output = text_encoder( …………) 执行这个操作时报错 Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:1! (when checking argument for argument mat1 in method wrapper_addmm)
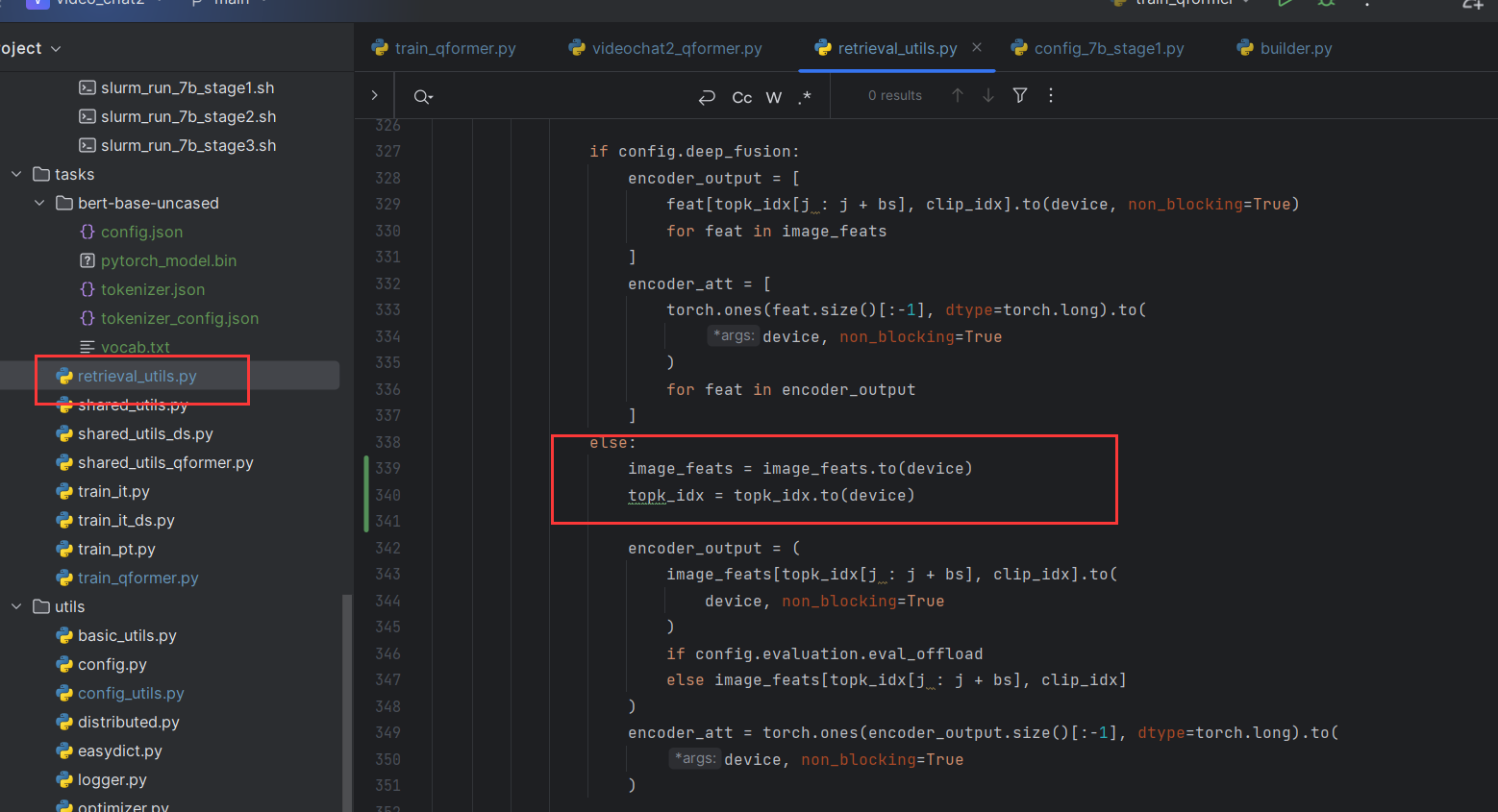
evaluate时
RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
数据维度
clip计算相似分数时报错:
Traceback (most recent call last):
File "/home/bailey/Code/wyf/Ask-Anything/video_chat2/tasks/train_qformer.py", line 302, in <module>
main(cfg)
File "/home/bailey/Code/wyf/Ask-Anything/video_chat2/tasks/train_qformer.py", line 232, in main
res = evaluation_wrapper(
File "/home/bailey/anaconda3/envs/videochat2/lib/python3.9/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/home/bailey/Code/wyf/Ask-Anything/video_chat2/tasks/retrieval_utils.py", line 75, in evaluation_wrapper
i2t_x, t2i_x, i2t_emb, t2i_emb = evaluation(
File "/home/bailey/anaconda3/envs/videochat2/lib/python3.9/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/home/bailey/Code/wyf/Ask-Anything/video_chat2/tasks/retrieval_utils.py", line 258, in evaluation
score = model.itm_head(itm_embeds)[:, 1]
File "/home/bailey/anaconda3/envs/videochat2/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/home/bailey/anaconda3/envs/videochat2/lib/python3.9/site-packages/torch/nn/modules/linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
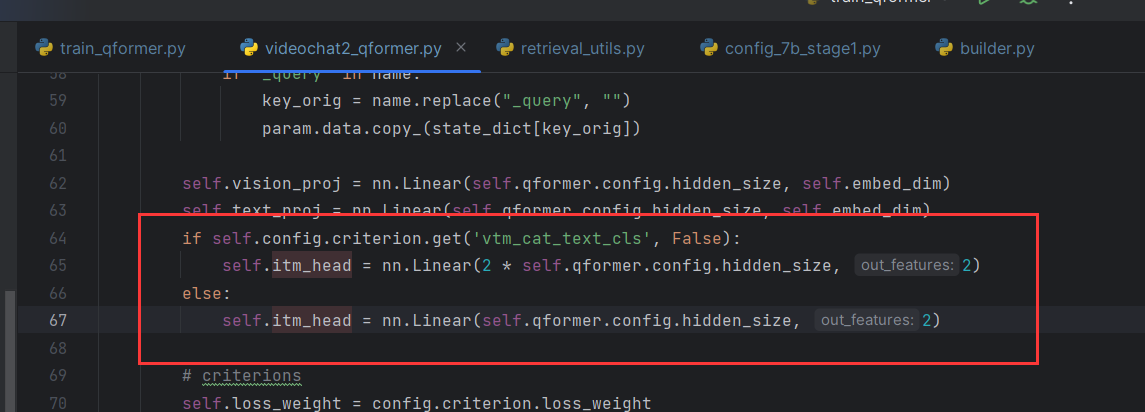
RuntimeError: mat1 and mat2 shapes cannot be multiplied (128x768 and 1536x2)具体来说,**itm_embeds** 的形状为 (128, 768),而 itm_head 的权重矩阵的形状为 (1536, 2),这两者的维度不匹配,无法进行矩阵乘法。
在videochat2_qformer里面可以看到,配置vtm_cat_text_cls=true,会使得矩阵形状变成2倍。因此在配置文件里把这个改成false即可。
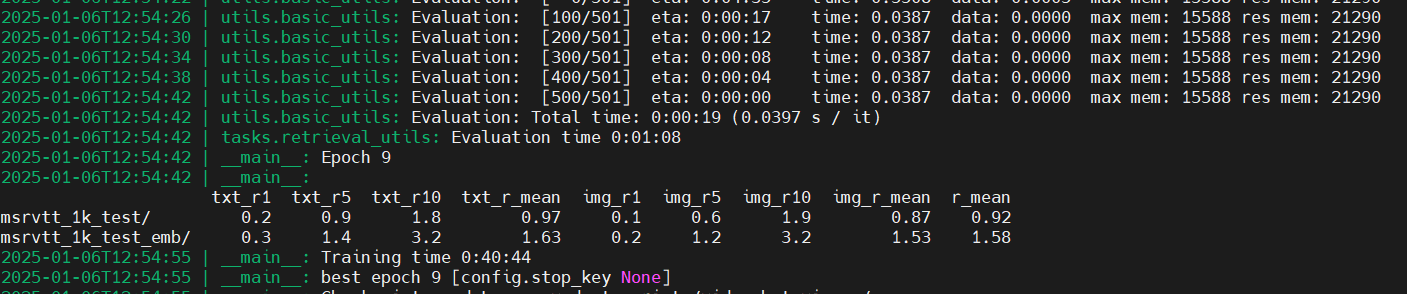
阶段一训练结果
原始数据量:(本机路径D:\AMLLM-Video\annotation)
图像cc3m 20184张
视频MSRVTT 10000个
视频webvid 1809个
训练用cc3m和webvid,测试用了MSRVTT中的1000条数据。
阶段2训练
新增数据集InternVID,见MLLM-Code。
参考
论文阅读MVBench: A Comprehensive Multi-modal Video Understanding Benchmark-CSDN博客
CVPR2024 Highlight] MVBench多模态视频理解能力的全面评测 - 知乎
代码: Ask-Anything/video_chat2 at main · OpenGVLab/Ask-Anything
『技术随手学』解决CondaHTTPError: HTTP 000 CONNECTION 问题 - 知乎
import torchModuleNotFoundError: No module named ‘torch‘_import torch 找不到模块-CSDN博客
conda中使用pip的问题:如何在conda环境中正确地使用pip_在conda构建的虚拟环境下可以进行pip操作吗-CSDN博客
Previous PyTorch Versions | PyTorch
wandb使用:wandb: 深度学习轻量级可视化工具入门教程_wandb教程-CSDN博客
Pycharm远程连接服务器进行代码的运行与调试_remote sdk is saved in idesetting-CSDN博客
google-bert/bert-base-uncased at main
LLMs之Mistral:Mistral 7B v0.2的简介、安装和使用方法、案例应用之详细攻略_mistral-7b-instruct-v0.2-CSDN博客



