TimeChat: A Time-sensitive Multimodal Large Language Model
摘要
本研究提出的 TimeChat 是一种时间敏感的多模态大型语言模型,专为长视频理解而设计。模型包含两个关键的架构贡献:(1)时间戳感知帧编码器,可以将视觉内容与每个帧的时间戳绑定;(2)滑动视频 Q-Former,生成不同长度的视频token序列,以适应不同时长的视频。此外,本文还构建了一个指令微调(instruction-tuning)数据集,包含 6 个任务和总共 125K 个实例,以进一步提高 TimeChat 的instruction-following性能。各种视频理解任务(如dense captioning, temporal grounding, and highlight detection)的实验结果都证明了 TimeChat 强大的零样本时间定位和推理能力。例如,与最先进的视频大语言模型相比,TimeChat 在 YouCook2 上获得了 +9.2 的 F1 score和 +2.8 的 CIDEr 分数,在 QVHighlights 上获得了 +5.8 的 HIT@1 分数,在 Charades-STA 上获得了 +27.5 的 R@1 分数(IoU=0.5),有望成为长视频理解任务的多功能视频助手,满足用户的实际需求。
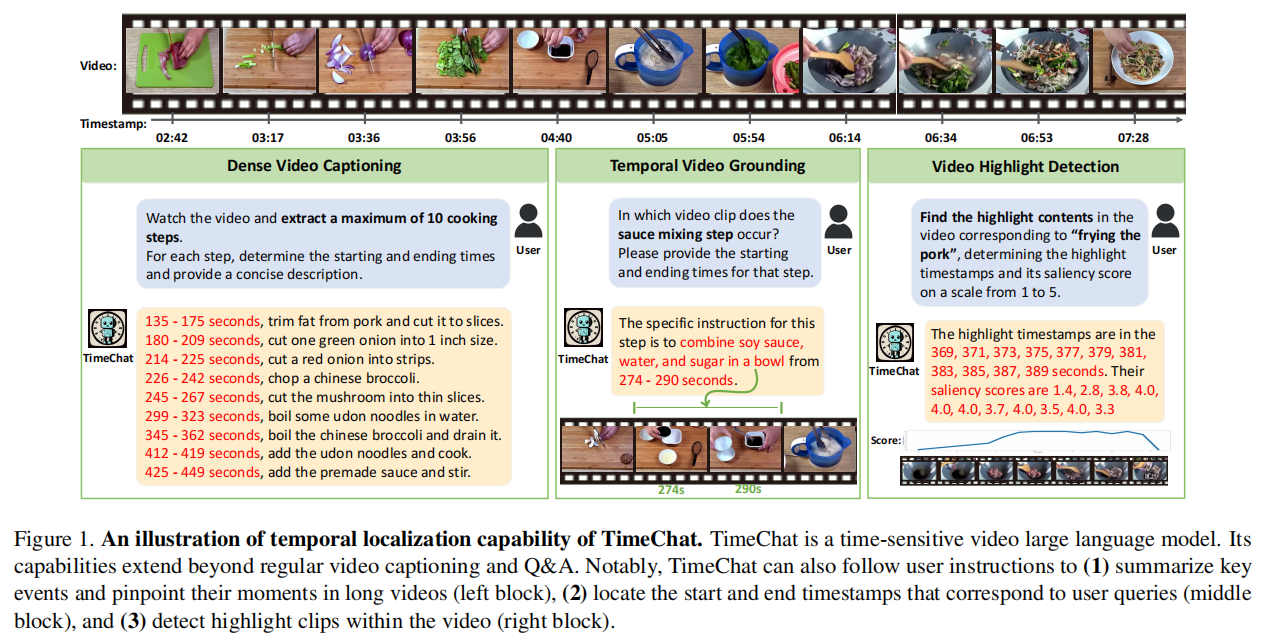
引言
背景
- 从教育教程到故事电影,长格式的视频已经成为我们日常生活中的一个重要媒介。但筛选冗长的视频是相当耗时且无趣的工作。
- 人类的注意力总是被有意义的或突出的视觉片段所吸引,比如烹饪教程中的基本步骤或体育赛事中的精彩时刻。
- 一个智能的时间敏感视频助手,为用户分析长视频,包括时间定位、时间戳检测和关键时刻总结,是社会的长期需求。
- 大模型拥有强大的指令遵循能力,可以用于长视频理解任务,满足用户的现实需求。
现状
- 已经进行了一些初步探索以集成视觉编码器和LLM来实现基本的视频理解(说明字幕、问答)。
- 然而,现有的视频LLM(VidLLM)只能捕获短片段的全局视觉语义,而不能将重要的视频内容与准确的时间戳关联起来。
- 例如,VideoLLaMA和VideoChat努力定位和描述未经修剪的视频中的有意义的事件,导致在Tab2中验证的准确性较低。
- 个人理解:上述两种模型侧重识别特定事件发生,本文模型侧重时间戳定位。在社区事件定位场景中需要取二者均衡。
现有的VidLLM有两个问题:(1)刚性压缩将视频token转换为固定数字不适合长视频输入–它忽略了视频的持续时间,在处理长视频的大量帧时,导致严重的时空语义退化。(2)它们分别处理视频和时间戳信息,而不考虑显式的时间-视觉关联,因此无法准确地定位时间戳。
本文贡献
提出TimeChat,一种时间敏感的多模态大语言模型,用于长视频理解和准确的时间定位。
为了处理长视频输入,提出了一种滑动视频Q-Former来适应视频特征提取和压缩过程中的自适应视频标记长度。视频Q-Former将滑窗内的帧压缩为视频token。移动窗口可以动态创建不同长度的视频token序列。它保留了长视频的重要视觉语义,并得到了更具表现力和可伸缩的视频表示。(捕获帧间时间信息)
为了增强视觉-时间戳的关联,提出了一个具有时间感知能力的帧编码器,它显式地将视觉上下文与每个帧的时间戳描述绑定起来。(绑定帧+时间戳信息)
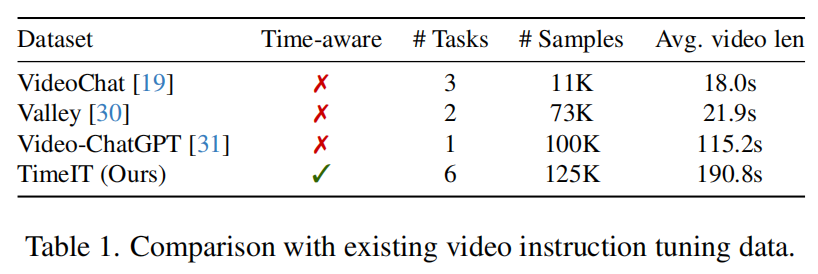
为了提高TimeChat固有的时间戳定位能力,增强它的指令遵循能力,构建了一个新的指令调优数据集TimeIT,涉及不同的时间戳相关的用户指令。该数据集是由各种与时间戳相关的长视频数据集编译而来的,平均视频长度为190.8s。它由6个不同的任务、12个广泛使用的学术基准和总共125K实例组成。(增强时间-视觉关联能力)
相关工作
许多研究都在努力将llm与视频编码器集成起来,从而利用llm的强大理解和生成能力来进行视频任务。这些研究通常使用开源的llm,如Vicuna和LLaMA。它们的关键区别在于它们如何将视频编码为与llm兼容的视觉token。有代表性的工作,如VideoChat利用一个video transformer来编码视频features,随后实现一个Query Transformer(Q-Former)来压缩video tokens。VideoLLaMA首先使用vision transformer(ViT)和图像Q-Former对独立帧进行编码,然后使用视频Q-Former进行时间建模。然而,这些方法将视频token压缩到一个固定的数字,导致在处理长视频时视觉语义退化。相比之下,本文模型为视觉标记提供了可调的压缩率,增加了对不同视频长度的适应性。此外,模型明确地建立了一个帧级的视觉-时间戳关系,以提高时间定位能力。
视觉-语言指令微调需要使用人工指令生成高质量的数据,这可以分为两个技术分支。(1)合并可用的多模态基准数据集,将它们转化为指令格式;(2)利用GPT生成更多样化的对话式数据。
时间定位是视频理解任务的一个基本能力,特别是对于未修剪的长视频。有各种时间敏感的视频任务,包括视频时间定位、视频说明字幕、视频摘要、视频亮点检测、步长定位等。这些任务需要在视频语义和相应的时间戳之间进行显式的关联。以前的研究倾向于在专门的下游数据集上单独处理每个任务。尽管最近的工作对弥合一些任务进行了初步的尝试,但基于llm的通用范式仍在探索中。本文在语言建模上统一了一些时间敏感的视频任务,迈出了充分利用llm的通用能力的第一步。
本文方法
模型组件主要由三部分构成:1)时间感知帧编码器,2)视频滑窗Q-Former,3)LLM
给定一个输入视频,帧编码器首先独立地提取每个帧的视觉和时间戳特征。接下来,视频Q-Former建模滑动窗口内帧的时间关系,以生成视频token。最后,将这些视频token与可选的转录语音和用户指令连接起来,然后将这些指令输入LLM以生成响应。
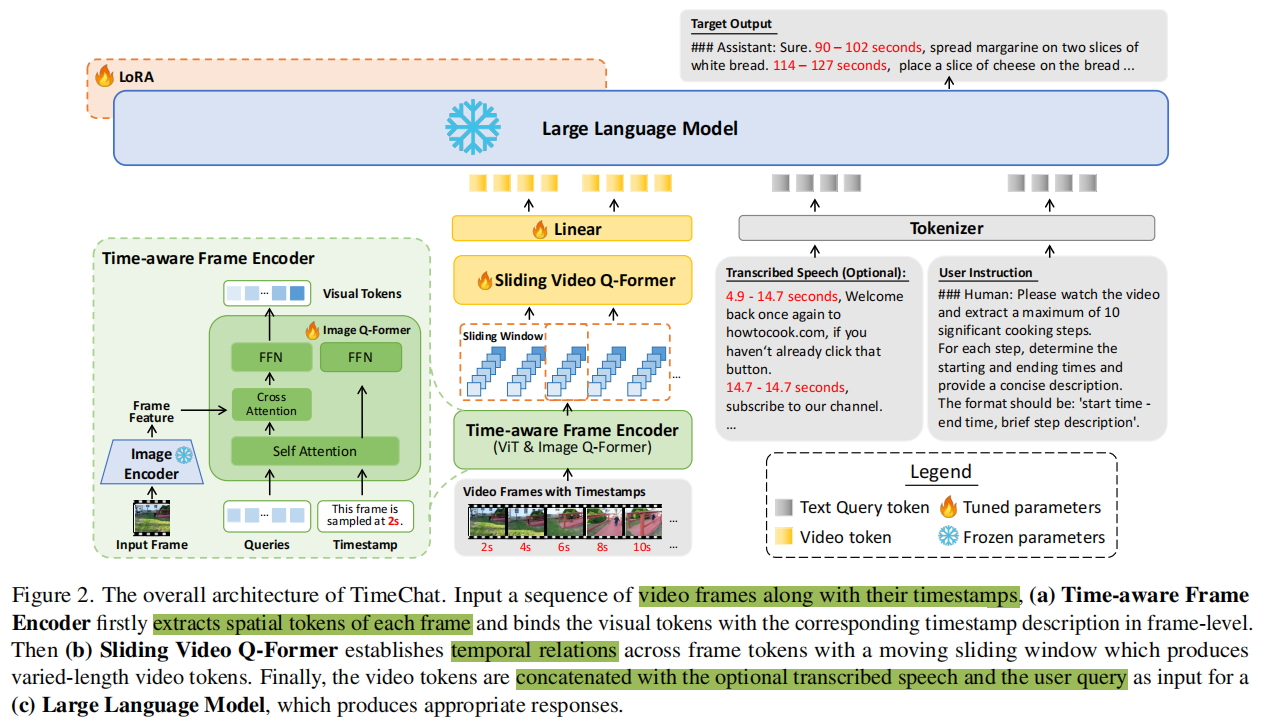
Timestamp-aware Frame Encoder
以前的研究通常将视觉语义的建模和输入帧各自的时间戳信息分开。该方法不能直接捕获视觉事件发生时的时间。一些方法为视觉标记了可学习的位置(时间)嵌入。然而,这只能使模型能够识别帧的顺序,在确定精确的时间矩时缺乏精度。
为了解决这些问题,引入受 InstructBLIP启发的时间戳感知帧编码器。给定一个视频输入V,首先使用一个预训练好的图像编码器即ViT对 每一帧进行编码获得帧特征(n*n*d),随后,一个图像Q-Former进一步压缩帧token。如图2所示,Q-Former以Dq维的可学习查询作为输入。这些查询通过交叉注意力与frame feature进行交互,并将初始查询更新到维度Dq中的Ni视觉标记。值得注意的是,在视觉标记抽取过程中,添加了帧的时间戳例如“This frame is sampled at 2s.”作为Q-Former融合视觉和时间戳信息的一个条件。
借鉴了InstructBLIP的Q-Former。首先通过ViT-G/14 from EVA-CLIP来抽取图片特征(n*n*d),再通过Q-Former来对feature做提取,并通过输入文本“This frame is sampled at 2s.”,来把时间戳信息也混合进去。一帧图像出来的特征是Ni*D的,Ni就是query向量的个数。这里的Q-Former是用InstructBLIP权重初始化的。
Sliding Video Q-Former
对于T帧的视频输入,使用时间戳感知帧编码器后,获取到T*Ni*D的视觉token。此时各帧独立编码,没有建模帧间时间信息。为此,引入Q-Former滑窗,在时间维度上增强特征融合。设计了一个长度为Lw的滑动窗口,并在每个窗口内利用视频Q-Former从Lw帧中提取Nv长度的视频token。(滑窗Lw,步长S,Q-former查询向量数Nv)最终可以将输入的视频表示为(T /S)×Nv的视频token。(上图黄色部分)
由于视频的三维特性,有大量冗余时空信息,原始视觉token会非常长(原始帧中的所有patch),需要压缩信息以降低LLM计算量。之前的工作一般都设置固定的视觉token数Nv比如32,当输入帧数T很大时,会造成严重的视觉语义退化。
本文采用固定的步长来保证长视频不会被过度压缩,即最终送入LLM的tokens数量会根据视频的长度变化而变化。在送入LLM之前还会经过一个线性映射层来使tokens的特征维度符合LLM的输入特征维度需求。
将压缩率R定义为原始视觉标记的数量与最终视频标记的数量之比。则以前Video-LLaMA的压缩率是:
$$
R=(TN_P)/N_V
$$
其中,Np为每一帧的patch数。这个比率随着输入帧数T的增加而增加,并会导致长视频的过度压缩。使用滑动视频Q-Former,压缩率R’变成一个常数值:
$$
R’=\frac{TN_P}{(T/S)N_V}=\frac{SN_P}{N_V}
$$
为长视频保留更丰富的语义。通过调整步幅S,可以根据计算预算来控制视频token的最终数量。最后,利用线性层对视频标记的维数DQ进行变换,以匹配LLM嵌入空间的维数DLLM。
Large Language Model
将多种模态的输入连接起来,包括视频token Xv,文本查询向量Xq(包括可选的转录语音和用户指令),并将其输入一个大型语言模型,以生成合理和连贯的响应Xa。在这里,Xv、Xq和Xa具有相同的标记embedding维数DLLM。
VidLLM的训练通常采用两阶段训练框架。第一阶段使用大规模图像/视频-文本对进行预训练,以实现视觉-语言对齐。第二阶段使用指令数据对模型进行微调,以实现指令遵循。考虑到计算效率,本文重用了在第一阶段训练后现有开源模型的检查点(模型用的是LLaMA-2 (7B)),仅进行指令微调。采用LoRA微调的方式来对LLM模型进行微调。在训练过程中,利用语言建模损失生成长度为LT的目标答案Xa:
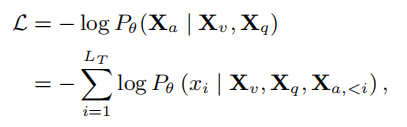
数据集TimeIT
为了提高TimeChat对时间敏感的人类指令的理解能力,提出TimeIT,一个涉及时间戳的以视频为中心的指令调优数据集。该数据集集成了广泛的与时间戳相关的视频数据集,并以长篇视频为特征。
TimeIT包含了6个与时间戳相关的视频任务,即:**(1) 视频说明字幕生成,(2) 视频时间定位,(3) 步骤定位和文字生成,(4) 视频摘要,(5) 视频亮点检测,以及 (6) 转录语音生成**。它还整合了来自不同领域的12个特定数据集。数据集适应了在现实世界应用中与AI助手交互时涉及视频时间戳的普遍用户请求。
数据集构建方式分两步:1)Instruction Writing 和 2) Answer Formatting。
指令构造:先通过人工进行构造,然后利用GPT-4进行扩写来产生更多样化的表达,最后通过人工检查和refine来形成最终的版本。对于每个task会产生6个高质量的指令(instructions)。
答案模板:根据编写的指令,我们进一步将任务输出重新表述为用户友好的自然语言响应范式。考虑到所涉及的视频数据集是人工收集的,TimeIT数据的整体质量得到了保证。
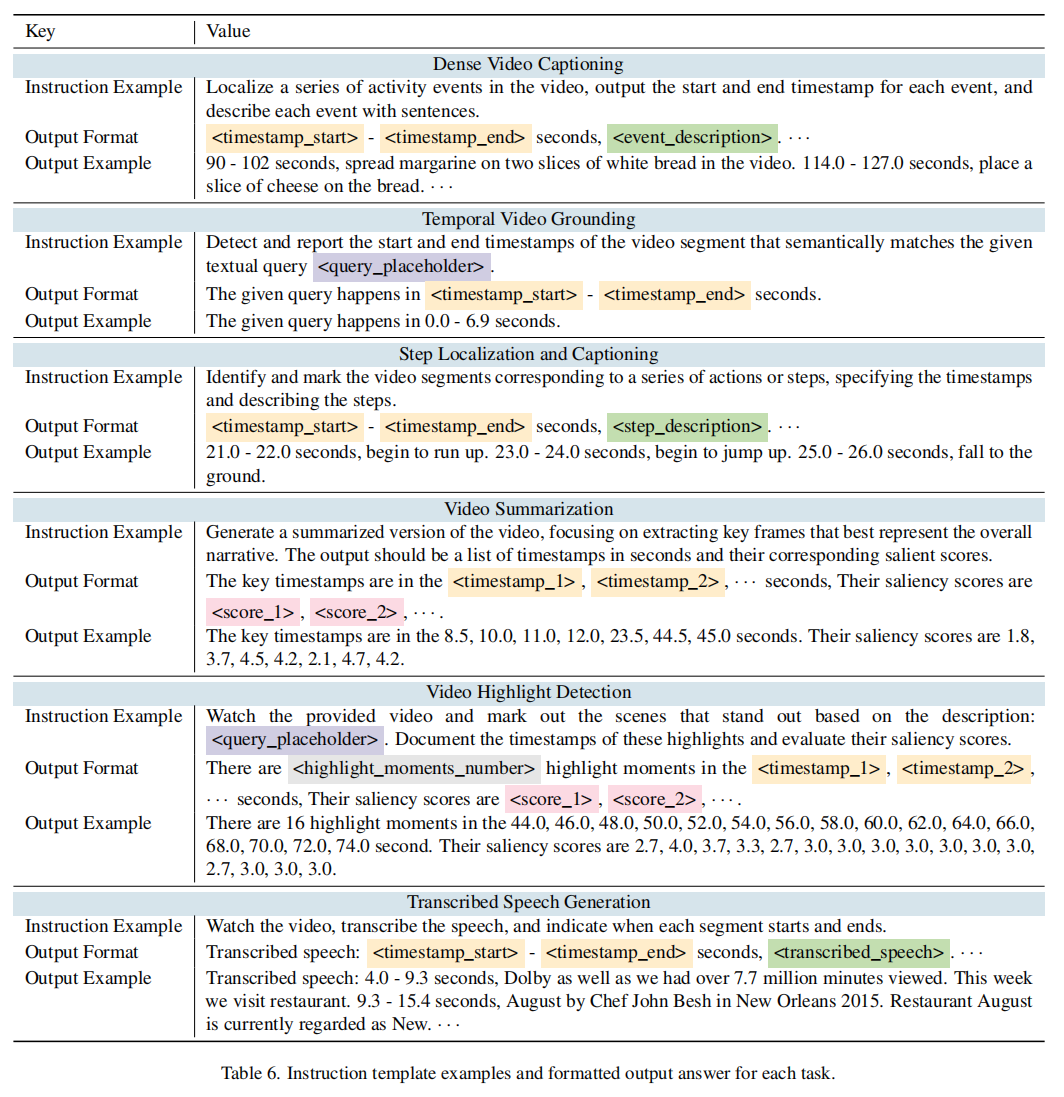
表1将TimeIT数据与现有的视频指令调优数据进行了比较,揭示了本文数据集在数据规模、任务多样性和视频长度方面的显著优势。附录C提供了每个任务对模型性能的贡献分析。总的来说,所有6个任务都是有益的。
实验
以EVA-CLIP中的ViT-G/14作为图像编码器,以LLaMA-2(7B)作为语言基础模型。图像Q-Former的参数从InstructBLIP的检查点初始化,而视频Q-Former从Video-LLaMA的检查点初始化。在TimeIT和Valley上调整了3个epoch,使用32的批处理大小,使用一台8-V100(32G)机器。如图2所示,ViT和LLM的参数被冻结,而图像Q-Former、视频Q-Former和线性层的参数被调整。窗口大小Lw、步幅S和每个窗口的视频token Nv数为32。输入帧数为96。其他超参数请参阅附录D。
模型在三个任务上进行零样本长视频理解评估,即字幕(说明性文字)生成,时间定位,和亮点检测。评估数据集包括YouCook2、 Charades-STA和 QVHighlights。评价指标的细节详见附录E。
用于解析LLM输出的启发式规则:由llm生成的输出可能包括口语化表达式,从而导致较大的响应变化。因此,作者设计了大量的启发式规则,以保证能够准确地从模型的响应中提取预测的答案,以计算最终的度量。
方法比较:将模型与两个基线对比。(1)多模态pipeline: VideoChat-Text,InstructBLIP+ChatGPT。这些pipeline将专用的视觉模型与GPT集成,首先将视觉语义转换为文本描述,然后利用ChatGPT来处理所有输入来解决目标任务。(2)端到端模型:Valley,VideoChat-Embed,Video-LLaMA with 7B LLMs。这些模型直接将视频作为输入,并以端到端的方式生成响应。
零样本性能
表2显示了TimeChat(7B)的零样本性能,它在所有任务中都优于以前的VidLLM(7B/13B)。
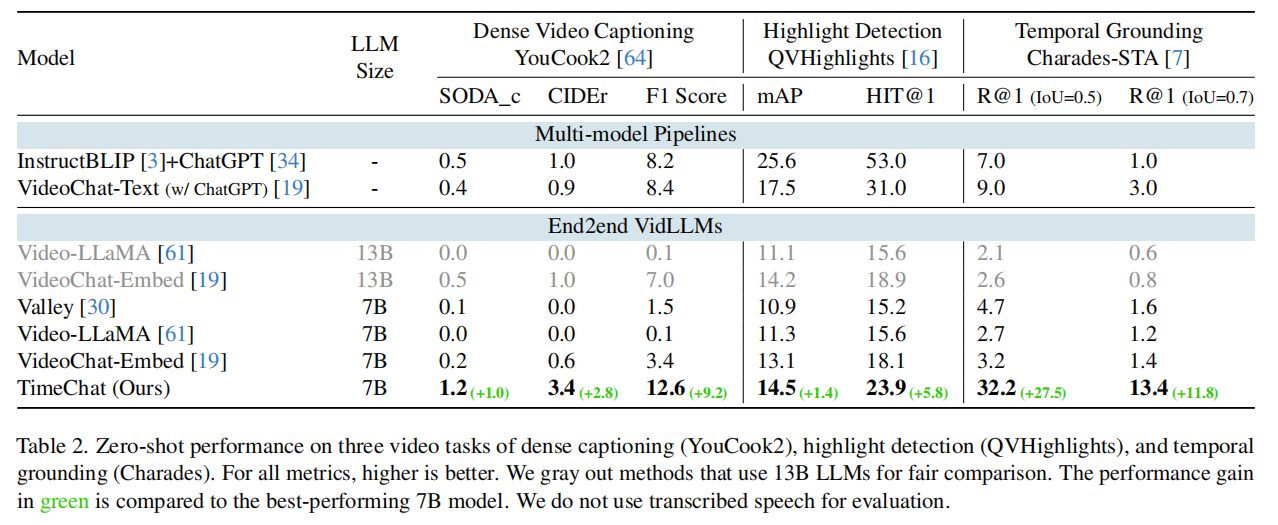
密集字幕/说明文字生成:该任务在YouCook2上训练。模型需要在平均320秒的视频持续时间内,准确地识别出大约8个基本的烹饪步骤,并提供与视觉内容相匹配的忠实描述。烹饪的特殊性也提高了任务的复杂性,挑战了模型的通用性。现有的端到端VidLLM难以实现精确的moment定位,性能最好的VideoChat-Embed模型获得的低F1分数3.4就证明了这一点。这种momen定位的不精确显著影响了说明文字的评估,使得SODA_c和CIDEr指标都接近于零。与之相比,本文模型通过+1.0 SODA_c、+2.8 CIDEr和+9.2 F1评分获得了显著的SOTA。这表明TimeChat能够有效地处理长时间的视频,拥有精确的时间定位能力。此外,本文模型性能也显著超过了由ChatGPT提供的多模态pipeline(F1评分从8.4到12.6)。
视频亮点检测:dense video captioning任务集中于在clip级别定位事件,而亮点检测任务需要在帧级别进行更细粒度的视频理解。对于输入视频,其目标是输出亮点帧的时间和突出分数。整体来看,本文模型在QVHhemict上达到了14.5 mAP和23.9 HIT@1,比之前的vidllm分别获得了+1.4和+5.8分。这突出了时间戳感知帧编码器在识别每个帧的显著语义方面的贡献。此外,该任务是TimeIT的held-out任务,表明了模型对新任务的泛化能力。多模态pipeline方法获得了更好的性能,作者推测,这是由于高亮检测的格式与他们的方法更兼容,鉴于模型接收到一系列的输入帧的联合的时间戳-视觉描述。这使得LLM能够逐帧进行评估,从而促进更准确的判断。
时间定位:此任务旨在识别查询语句所描述的对应时间戳。TimeChat在Charades-STA数据集的“R@1,IoU=0.5”上达到32.2分,大大超过了之前的SOTA端到端VidLLM,即Valley(+27.5)。这表明,本文模型能够准确地定位给定文本查询的视频时刻。值得注意的是,TimeChat在时间定位任务上取得了最大的进步,作者认为该任务主要强调了长视频的时间定位能力,而这正是TimeChat的最佳优势。
定性评估
图4显示了在零样本设置下,TimeChat和其他VidLLM之间的定性比较。Video-LLaMA没有完全理解用户的指令,因为它只描述了步骤,而没有给出相应时间戳。VideoChat生成了符合请求格式的说明,但错位了所有步骤的时间。此外,VideoChat生成的描述包含一些幻觉。与之相比,TimeChat显示了改进的时间定位和总结功能。它成功地匹配了几乎所有提取的剪辑的视频内容。此外,幻觉的发生也明显减少了。然而,在增强模型生成的摘要的丰富性和细节方面仍有改进的空间。

领域推广:在附录G中,展示了新领域的定性结果,如movie和egocentric videos,展示了TimeChat对新场景的泛化。这种泛化是一个实用的视频助手的一个关键特征,它代表了基于LLM的TimeChat和当前为特定的下游数据集量身定制的专用模型之间的根本区别。
消融实验
当删除滑动视频Q-Former时,最终视觉token的数量从96减少到32,导致信息压缩率为3倍。语义信息的减少导致了生成的描述和视频内容之间的对齐性的降低。具体来说,SODA_c度量减少了1.0,而CIDEr度量减少了2.8。此外,时间戳的准确性(以F1分数衡量)降低了3.0。在去除时间戳感知帧编码器的情况下,模型对时间基础描述的能力显著下降,F1分数下降了2.3。这些结果突出了模型中两个新模块的有效性。

其他分析
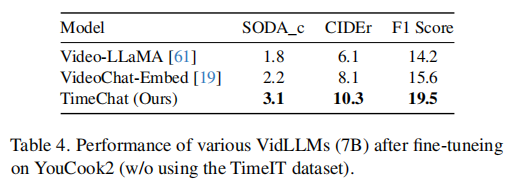
为了证明模型的性能提高不仅归因于新的TimeIT数据集,而且还归因于模型架构的改进,只使用YouCook2数据集进行微调和评估。在这个设置中,使用现有的开源检查点初始化模型(参见4.1)。对于所有的模型,应用LoRA 并微调Q-Former。Tab.4给出了结果,显示模型在所有指标上都始终优于以前的模型。
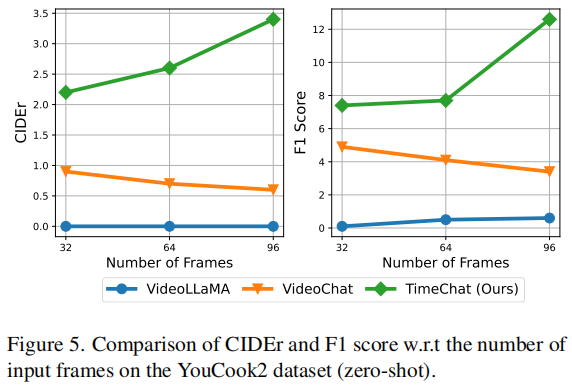
在图5中,作者检查了模型关于输入帧数的性能测量。如3.1.3中提到的,以前的模型如Video-LLaMA和VideoChat压缩了长视频的过多信息,当输入帧数从32增加到96时,性能表现最差。相比之下,本文模型使用滑动视频Q-Former解耦帧数T和压缩率R‘。随着帧数的增加,曲线表现出线性提高,显示出优越的可伸缩性。
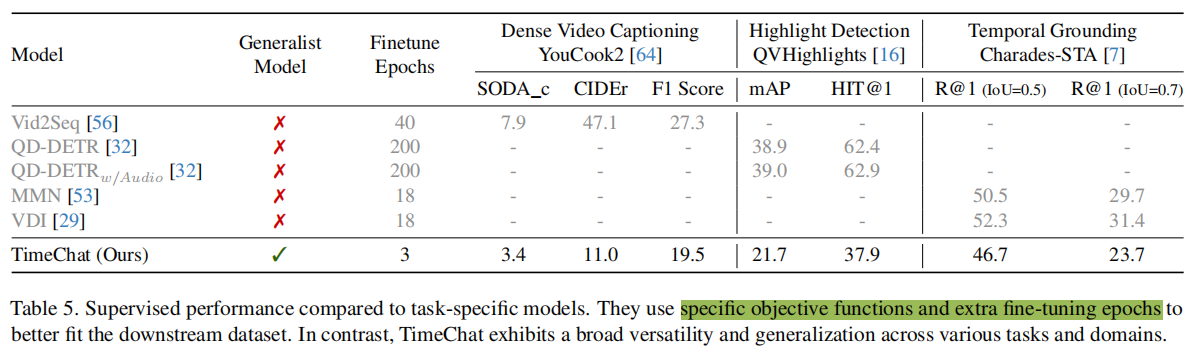
与专用模型的比较
比较TimeChat与在三个任务上分别拥有最先进性能的专用模型。鉴于所有专用模型都在特定数据集上做了微调,作者对自己的模型也做了微调以进行公平比较。如表5所示,微调后TimeChat进一步提升了性能(+6.9 F1 score on YouCook2, +16.9 HIT@1 on
QVHighlights, and +16.4 R@1 (IoU=0.5) on Charades-STA)。专用模型的优越性来自特定任务的设计,例如Vid2Seq在YT-Temporal-1B上做预训练,这个数据集具有更多高质量的长视频;QD-DETR采用一种特殊的显著性token进行显著性预测,并引入了4个损失函数用于训练,而本文模型纯粹通过语言建模进行训练。此外,这些模型还使用了更多的微调步骤,以更好地适应下游数据集。
而作为一个通用模型,TimeChat在零样本场景、多任务和多领域设置中表现出很强的泛化能力,而这在这些专家模型中是不存在的。在每项任务上实现最先进的性能并不是本文的主要目标。
总结
本文提出了TimeChat,一个用于长视频理解的时间敏感的VidLLM。得益于新的时间感知帧编码器、滑动视频Q-Former和TimeIT上的指令调优,本文模型显示了强大的时间定位能力,这是在以前的VidLLM中所没有的。通过在冗长的视频中识别重大事件,确定事件的开始和结束时间,并生成简明的总结,TimeChat向智能视频助手迈出了关键的一步。在未来,将进一步取得架构上的进步,以提高视频语义密度,同时减少时空冗余。作者还将收集更多样化和高质量的指令调优数据,以扩大与时间相关的应用。
==项目配置==
数据相关
video&annotations
- YouCook2: http://youcook2.eecs.umich.edu/download
- Charades-STA: https://github.com/jiyanggao/TALL#charades-sta-anno-download
- QVHighlight: https://github.com/jayleicn/moment_detr/blob/main/data/README.md
- ActivityNet Captions: http://activity-net.org/download.html
- ViTT: https://github.com/google-research-datasets/Video-Timeline-Tags-ViTT
- DiDeMo: https://github.com/LisaAnne/LocalizingMoments?tab=readme-ov-file#dataset
- QuerYD: https://www.robots.ox.ac.uk/~vgg/data/queryd/
- HiREST: https://github.com/j-min/HiREST
- TVSum: https://github.com/yalesong/tvsum
- SumMe: http://classif.ai/dataset/ethz-cvl-video-summe/
- COIN: https://github.com/coin-dataset/annotations
- YT-Temporal: https://rowanzellers.com/merlot/#data
对视频进行预处理,降低 FPS 和维度,以减少存储空间并改进数据加载。
ls -U /path/to/raw/video >> /path/to/video_names.txt
# for YouCook2
python utils/compress_video_data.py \
--input_root=/path/to/raw/videos/ \
--output_root=data/YouCook2-BB/YouCook2_asr_denseCap/youcook2_6fps_224/ \
--input_file_list_path=/path/to/video_names.txt \
--fps=6 --size=224 --file_type=video --num_workers 24
# for ActivityNet Captions
python utils/compress_video_data.py \
--input_root=/path/to/raw/videos/ \
--output_root=data/Activitynet_Captions/anet_6fps_224 \
--input_file_list_path=/path/to/video_names.txt \
--fps=6 --size=224 --file_type=video --num_workers 24HiREST_STEP&VALLEY:run python utils/process_valley.py及python utils/process_hirest.py
Automatic speech transcription
从视频中提取音频:
python utils/extract_audio.py --dir /home/v-shuhuairen/mycontainer/data/DiDeMo/ --video_folder videos
for i in {0..179}; do python utils/extract_audio.py --dir /home/v-shuhuairen/mycontainer/data/COIN/ --video_folder videos_ali/${i} --audio_folder audio_files/${i}; done使用whisper:
python utils/asr/asr.py --audio_dir audio_files --dir /home/v-shuhuairen/mycontainer/data/DiDeMo/
for i in {0..179}; do python utils/asr/asr.py --dir /home/v-shuhuairen/mycontainer/data/COIN/ --audio_dir audio_files/${i}; done清除ASR结果:
python utils/clean_asr.py --dir /home/v-shuhuairen/mycontainer/data/DiDeMo/whisper_outputs_with_time/将ASR结果纳入instruction中:
Incorporate the ASR results into the instructions指令数据集
- TimeIT: https://huggingface.co/datasets/ShuhuaiRen/TimeIT
- Valley: https://huggingface.co/datasets/luoruipu1/Valley-Instruct-65k
数据格式:
{
"video": "ActivityNet_asr_denseCap/anet_6fps_224/v_MinmayCk2Nk.mp4",
"QA": [
{
"q": "Capture and describe the activity events in the given video, specifying their respective time intervals, and outputting the time intervals in the 'start - end seconds format'.",
"a": "0.0 - 9.1 seconds, We see a male gymnast prepare to use the pommel horse. 9.1 - 10.8 seconds, The man mounts the pommel horse and spins his legs around it. 29.9 - 35.2 seconds, The man does a handstand and dismounts. 35.7 - 38.6 seconds, The man takes a bow and starts walking away."
}
],
"source": "Activitynet_Captions"
}字幕(说明文本)生成:
{"video": "vitt/raw_videos/--L2yxB3CUg.mp4", "QA": [{"q": "Detect and report the start timestamp of activity events in the video, along with descriptions.", "a": "2.7 seconds, Introduction. 8.5 seconds, Ingredients needed. 38.4 seconds, Measuring cornstarch. 54.1 seconds, Adding water. 62.0 seconds, Mixing mixture. 106.3 seconds, Explaining quicksand. 189.0 seconds, Closure."}]}
{"video": "YouCook2_asr_denseCap/youcook2_6fps_224/GLd3aX16zBg.mp4", "QA": [{"q": "Localize a series of activity events in the video, output the start and end timestamp for each event, and describe each event with sentences. The output format of each predicted event should be like: start - end seconds, event description. An specific example is : 90.0 - 102.0 seconds, spread margarine on two slices of white bread in the video.", "a": "90.0 - 102.0 seconds, spread margarine on two slices of white bread. 114.0 - 127.0 seconds, place a slice of cheese on the bread. 132.0 - 138.0 seconds, place the bread slices on top of each other and place in a hot pan. 139.0 - 145.0 seconds, flip the sandwich over and press down. 173.0 - 174.0 seconds, cut the sandwich in half diagonally. "}]}步骤定位:
{"video": "COIN/videos_ali/116/NLy71UrHElw.mp4", "QA": [{"q": "Identify and mark the video segments corresponding to a series of actions or steps, specifying the timestamps and describing the steps.", "a": "21.0 - 22.0 seconds, begin to run up. 23.0 - 24.0 seconds, begin to jump up. 25.0 - 26.0 seconds, fall to the ground."}]}
{"video": "HiREST/clips/_7urSjT6sQY_35_79.mp4", "QA": [{"q": "Find, identify, and determine the temporal boundaries of a series of distinct actions or steps occurring throughout the video. For each action, output the corresponding start and end timestamps, accompanied by a concise description.", "a": "0.0 - 13.0 seconds, clean out the face. 13.0 - 25.0 seconds, apply tissue using water on face. 25.0 - 37.0 seconds, apply it for full face. 37.0 - 42.0 seconds, put it under the neck . 42.0 - 44.0 seconds, dry it out."}]}基于查询文本的视频切片定位:
{
"0": "Localize the visual content described by the given textual query <query_placeholder> in the video, and output the start and end timestamps in seconds.",
"1": "Detect and report the start and end timestamps of the video segment that semantically matches the given textual query <query_placeholder>.",
"2": "Give you a textual query: <query_placeholder> When does the described content occur in the video? Please return the timestamp in seconds.",
"3": "Locate and describe the visual content mentioned in the text query <query_placeholder> within the video, including timestamps.",
"4": "The given natural language query <query_placeholder> is semantically aligned with a video moment, please give the start time and end time of the video moment.",
"5": "Find the video segment that corresponds to the given textual query <query_placeholder> and determine its start and end seconds."
}
{"video": "Charades/videos/AO8RW.mp4", "QA": [{"q": "The given natural language query 'a person is putting a book on a shelf' is semantically aligned with a video moment, please give the start time and end time of the video moment.", "a": "The given query happens in 0.0 - 6.9 seconds."}]}语音转录:
{
"0": "After watching the video from the YTTemporal dataset, transcribe the spoken content into text and document the start and end time for each segment. The format should be: 'start time - end time, transcribed speech'.",
"1": "Observe the video thoroughly and transcribe the speech in a maximum of 20 segments. Make sure to include the starting and ending times for each segment in the following format: 'start time - end time, transcribed speech'.",
"2": "Watch the provided video and transcribe the audio content. For each transcribed speech segment, note down its duration in the format: 'start time - end time, transcribed speech'.",
"3": "Review the video from the YTTemporal dataset. Identify segments where speech occurs and transcribe those into text. Record the start and end time for each segment in this format: 'start time - end time, transcribed speech'.",
"4": "Transcribe the spoken words in the video and note down the timestamps for each segment. Your output should look like this: 'start time - end time, transcribed speech'.",
"5": "Watch the video, transcribe the speech, and indicate when each segment starts and ends. Follow this format: 'start time - end time, transcribed speech'."
}视频亮点检测:
{
"0": "You are given a video from the QVHighlights dataset. Please find the highlight contents in the video described by a sentence query, determining the highlight timestamps and its saliency score on a scale from 1 to 5. The output format should be like: 'The highlight timestamps are in the 82, 84, 86, 88, 90, 92, 94, 96, 98, 100 seconds. Their saliency scores are 1.3, 1.7, 1.7, 1.7, 1.7, 1.3, 1.7, 2.3, 2.3, 2.3'. Now I will give you the sentence query: <query_placeholder>. Please return the query-based highlight timestamps and salient scores.",
"1": "Watch the provided video and mark out the scenes that stand out based on the description: <query_placeholder>. Document the timestamps of these highlights and evaluate their saliency scores.",
"2": "Perform a thorough review of the video content, extracting key highlight moments that align with <query_placeholder>. It is essential to record the times of these moments and assign a distinct saliency value to each.",
"3": "Examine the video and, in accordance with query <query_placeholder>, highlight the standout moments. You're required to provide the exact timing alongside a saliency rating for each segment.",
"4": "In the video presented, seek moments that are a perfect match with <query_placeholder>. It's vital to notate their timestamps and to score each based on their level of saliency.",
"5": "Go through the video content, and upon identifying highlight moments that resonate with <query_placeholder>, list their timestamps. Subsequently, provide a saliency score for each identified highlight."
}
{"video": "QVhighlights/videos/train/v_j7rJstUseKg_360.0_510.0.mp4", "QA": [{"q": "Watch the provided video and mark out the scenes that stand out based on the description: 'some military patriots takes us through their safety procedures and measures.'. Document the timestamps of these highlights and evaluate their saliency scores.", "a": "There are 29 highlight moments in the 72.0, 74.0, 76.0, 78.0, 80.0, 84.0, 86.0, 88.0, 90.0, 92.0, 96.0, 98.0, 100.0, 102.0, 104.0, 108.0, 110.0, 112.0, 114.0, 116.0, 120.0, 122.0, 124.0, 126.0, 128.0, 136.0, 138.0, 140.0, 144.0 second. Their saliency scores are 3.0, 2.7, 3.7, 2.3, 2.7, 2.7, 2.7, 2.7, 2.3, 2.7, 3.7, 3.3, 3.3, 3.7, 3.0, 2.3, 3.0, 2.3, 2.3, 2.3, 2.3, 3.0, 3.7, 2.7, 2.3, 2.3, 2.3, 2.3, 2.3."}]}视频摘要:
{
"0": "From the <dataset_placeholder> dataset, generate a summarized version of the video, focusing on extracting key frames that best represent the overall narrative. The output should be a list of timestamps in seconds and their corresponding salient scores",
"1": "You are given a video from the <dataset_placeholder> dataset. Please find the highlight contents in the video, determining the highlight timestamps and its saliency score on a scale from 1 to 5. The output format should be like: 'The highlight timestamps are in the 82, 84, 86, 88, 90, 92, 94, 96, 98, 100 second. Their saliency scores are 1.3, 1.7, 1.7, 1.7, 1.7, 1.3, 1.7, 2.3, 2.3, 2.3'. ",
"2": "Identify and extract the most emotionally impactful moments from the video provided by <dataset_placeholder> dataset, rating their intensity on a scale from 1 to 5.",
"3": "Watch the provided video from the <dataset_placeholder> dataset and mark out the timestamps with stand-out visual content. Document the timestamps of these highlights and evaluate their saliency scores.",
"4": "In the video presented from <dataset_placeholder> dataset, seek moments that could serve as an executive summary for a busy stakeholder. It's vital to notate their timestamps and to score each based on their level of saliency.",
"5": "Go through the video content from <dataset_placeholder> dataset, and upon identifying highlight moments, list their timestamps. Subsequently, provide a saliency score for each identified highlight."
}
{"video": "SumMe/videos/Air_Force_One.mp4", "QA": [{"q": "From the summe dataset, generate a summarized version of the video, focusing on extracting key frames that best represent the overall narrative. The output should be a list of timestamps in seconds and their corresponding salient scores", "a": "The highlight timestamps are in the 57.0, 62.4, 68.4, 73.2, 78.0, 79.2, 80.4, 84.6, 155.4, 156.6, 157.8, 159.6, 160.8, 161.4, 162.6, 164.4, 165.6, 167.4, 169.2, 171.0, 172.2 seconds. Their saliency scores are 2.1, 1.8, 2.1, 2.9, 4.2, 3.9, 3.7, 3.1, 1.8, 2.3, 2.9, 3.1, 3.4, 3.4, 3.7, 3.1, 3.1, 2.6, 2.1, 2.1, 1.8."}]}评估数据集
数据格式–对于字幕(说明文本)生成:
{
"annotations":
[
{
"image_id": "3MSZA.mp4",
"duration": 206.86,
"segments": [[47, 60], [67, 89], [91, 98], [99, 137], [153, 162], [163, 185]],
"caption": "pick the ends off the verdalago. ..."
},
...
eg:{"image_id": "v_QOlSCBRmfWY.mp4", "caption": "A young woman is seen standing in a room and leads into her dancing. The girl dances around the room while the camera captures her movements. She continues dancing around the room and ends by laying on the floor.", "segments": [[0.83, 19.86], [17.37, 60.81], [56.26, 79.42]], "duration": 82.73, "id": 0}
]
} 数据格式–对于视频切片定位:
{
"annotations":
[
{
"image_id": "3MSZA.mp4",
"caption": "person turn a light on.",
"timestamp": [24.3, 30.4]
},
...
eg:{"image_id": "AO8RW.mp4", "caption": "a person is putting a book on a shelf.", "timestamp": [0.0, 6.9], "id": 0}, {"image_id": "Y6R7T.mp4", "caption": "person begins to play on a phone.", "timestamp": [20.8, 30.0], "id": 1}
]
}模型相关
以下checkpoint存储可学习的参数(位置嵌入层、时间感知帧编码器、滑动视频Q-Former、线性投影层和lora)
| Checkpoint | LLM backbone | Link | Note |
|---|---|---|---|
| TimeChat-2-7B-Finetuned | LLaMA-2 7B | link | Fine-tuned on the instruction-tuning data from TimeIT-104K (asr version) and Valley-73K (previous version of current Valley-65K) |
ViT-g from EVA-CLIP
预训练的图编码器wget https://storage.googleapis.com/sfr-vision-language-research/LAVIS/models/BLIP2/eva_vit_g.pth
《EVA-CLIP: Improved Training Techniques for CLIP at Scale》
EVA-CLIP是一系列改进的CLIP模型,通过结合新表示学习、优化和增强技术,降低训练成本,提高训练效率和零次学习性能。最大模型EVA-02-CLIP-E/14+在ImageNet-1K上实现82.0%的零次学习准确率,而较小的EVA-02-CLIP-L/14+模型也有80.4%的准确率,但参数和样本量更少。
CLIP
CLIP(Contrastive Language-Image Pre-Training)模型是一种多模态预训练神经网络,由OpenAI在2021年发布,是从自然语言监督中学习的一种有效且可扩展的方法。CLIP在预训练期间学习执行广泛的任务,包括OCR,地理定位,动作识别。
该模型的核心思想是使用大量图像和文本的配对数据进行预训练,以学习图像和文本之间的对齐关系。CLIP模型有两个模态,一个是文本模态,一个是视觉模态,包括两个主要部分:
i. Text Encoder:用于将文本转换为低维向量表示-Embeding。
ii. Image Encoder:用于将图像转换为类似的向量表示-Embedding。
在预测阶段,CLIP模型通过计算文本和图像向量之间的余弦相似度来生成预测。这种模型特别适用于零样本学习任务,即模型不需要看到新的图像或文本的训练示例就能进行预测。CLIP模型在多个领域表现出色,如图像文本检索、图文生成等。
CLIP的的核心思想是通过海量的弱监督文本对通过对比学习,将图片和文本通过各自的预训练模型获得的编码向量在向量空间上对齐。不足:clip可以实现图文匹配,但不具有文本生成能力。
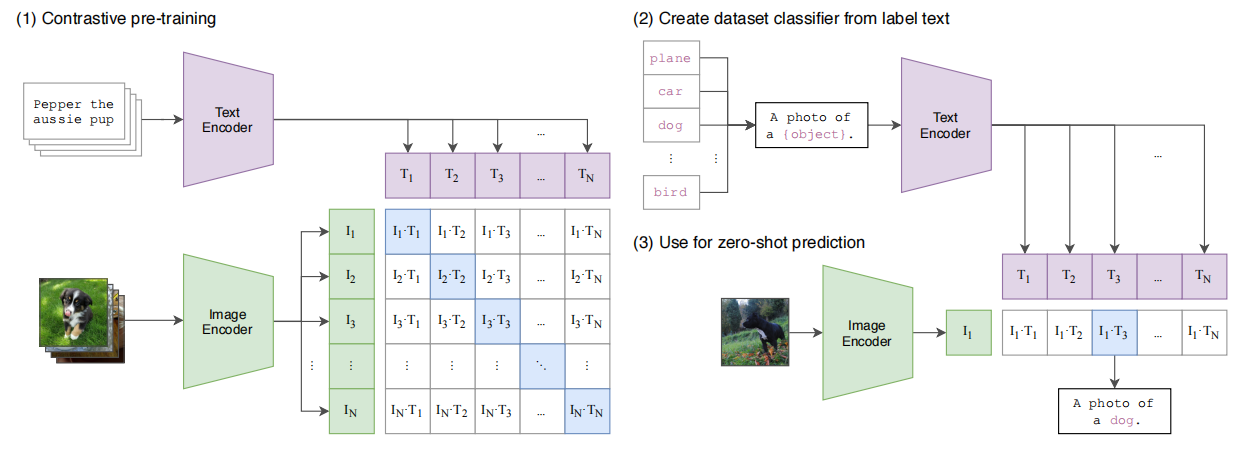
流程解读:
主要分为两个分支,一个图像encoder、一个文本encoder。图像分支是ResNet50或是VIT,文本分支和bert的结构类似,采用12层transformer,8个head,词表大小是49,152。最大sequence长度76。并且添加[SOS]和[EOS]标识token,并且[EOS]对应位置的特征就是最后的文本特征。
通过encoder特征提取以后,图像分支获得的特征是[batch, embed_dim],文本分支获得的特征是[batch, embed_dim]。其中对应位置上的embedding是匹配的,来自同一组图像-文本对。对于优化任务,一种自然的想法,就是拉近同一对embedding之间的距离,推远不同对的embedding之间的距离。作者采用了InfoNCE loss。特征间进行两两计算,[batch, embed_dim] * [embed_dim, batch] = [batch, batch],获取到batch*batch对样本之间的距离。
- 这里对提取的文本特征和图像特征进行对比学习。对于一个包含N个文本-图像对的训练batch,将N个文本特征和N个图像特征两两组合,CLIP模型会预测出N^2个可能的文本-图像对的相似度,这里的相似度直接计算文本特征和图像特征的余弦相似性(cosine similarity),即上图所示的矩阵。这里共有N个正样本,即真正属于一对的文本和图像(矩阵中的对角线元素),而剩余的N^2−N个文本-图像对为负样本,那么CLIP的训练目标就是最大化N个正样本的相似度,同时最小化N^2−N个负样本的相似度
作者采用的对称loss。针对每一个image特征,将text batch中对应的那个text特征拉近,而推远其余未配对的text特征。同样,针对每一个text特征,将image batch中对应的那个image特征拉进,而推远其余未配对的image特征。站在loss对称的角度,模型优化中图像、文本的地位是相同的。因此,论文标题想表达利用文本监督去学习视觉特征,但是这未尝不是利用图像监督去学习文本特征。对比纯图像领域的自监督学习方法,其实和上面的方法是类似的,只是将文本分支替换为图像分支,两个分支同时输入同一张图的图像增强版本。
CLIP之所以经典,在于其出色的zero-shot能力。
上面我们介绍了CLIP的原理,可以看到训练后的CLIP其实是两个模型,除了视觉模型外还有一个文本模型,那么如何对预训练好的视觉模型进行迁移呢?与CV中常用的先预训练然后微调不同,CLIP可以直接实现zero-shot的图像分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类,这也是CLIP亮点和强大之处。用CLIP实现zero-shot分类很简单,只需要简单的两步:
- 根据任务的分类标签构建每个类别的描述文本:
A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为N,那么将得到N个文本特征; - 将要预测的图像送入Image Encoder得到图像特征,然后与N个文本特征计算缩放的余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果,进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率。
流程解读:
输入单张图像,通过Image Encoder提取对应的embedding。然后设定想要查找的标签集合,如”plane”, “car”, “dog”等。然后利用prompt语句 “a photo of a {}”,分别构成”a photo of a plane”, “a photo of a dog”等文本。然后利用Text Encoder分别提取对应的文本embedding。最后利用文本embedding和图像embedding计算对应的相似度,然后对相似度进行softmax,获得最大的概率值,即为对应的label。实验结果显示CLIP在zero-shot上面具有较高的精度,表明CLIP的泛化性很好。
这里需要注意两点:一是标签集合是自行定义的,如果我们定义为imagenet的类别标签,那么这时zero-shot就相当于完成imagenet分类任务;二是prompt语句的改变,可能会影响最后的分类效果,论文指出不同的数据集,有自己最优的prompt语句,并且多个prompt语句的结果取平均,可能最终的效果更好。
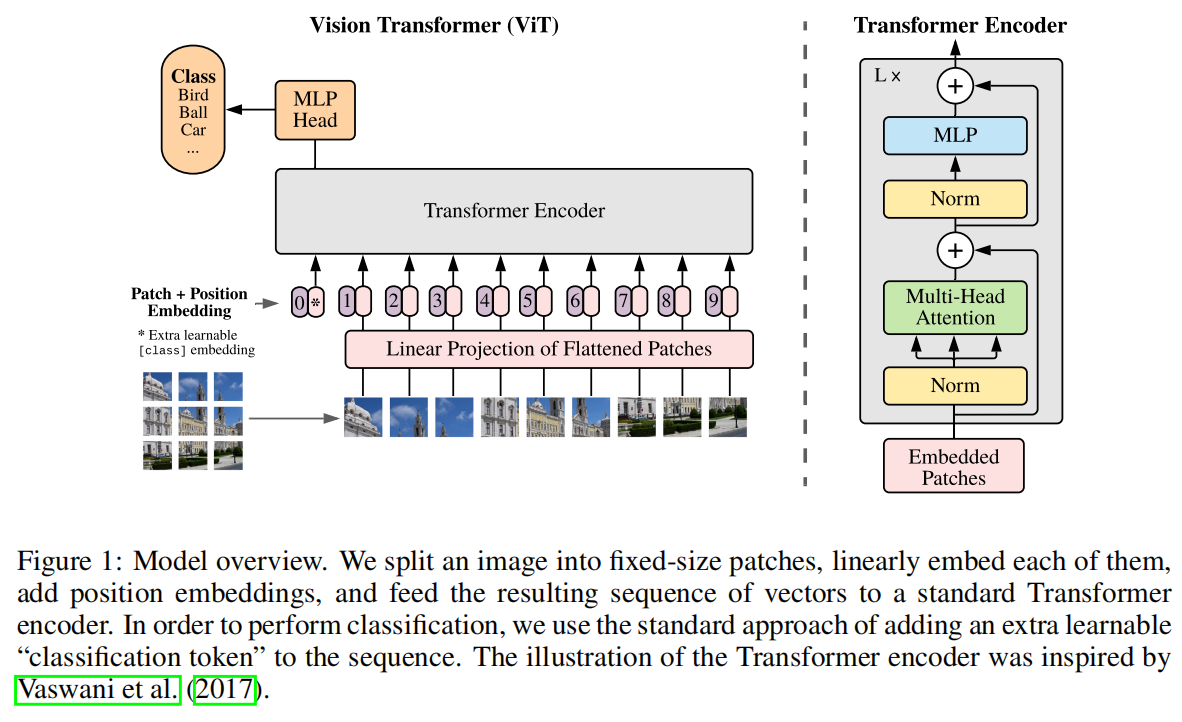
VIT
ViT(vision transformer)是Google在2020年提出的直接将transformer应用在图像分类的模型,后面很多的工作都是基于ViT进行改进的。ViT的思路很简单:
直接把图像分成固定大小的patchs,然后通过线性变换得到patch embedding,这就类比NLP的words和word embedding
由于transformer的输入就是a sequence of token embeddings,所以将图像的patch embeddings送入transformer后就能够进行特征提取从而分类了。
ViT模型原理如下图所示,其实ViT模型只是用了transformer的Encoder来提取特征(原始的transformer还有decoder部分,用于实现sequence to sequence,比如机器翻译)。
InstructBLIP Q-Former
图片Q-Former wget https://storage.googleapis.com/sfr-vision-language-research/LAVIS/models/InstructBLIP/instruct_blip_vicuna7b_trimmed.pth
BLIP-2:使用冻结图像编码器和大型语言模型进行语言图像预训练
InstructBLIP 是 BLIP 作者团队在多模态领域的又一续作。现代的大语言模型在无监督预训练之后会经过进一步的指令微调 (Instruction-Tuning) 过程,但是这种范式在视觉语言模型上面探索得还比较少。InstructBLIP 这个工作介绍了如何把指令微调的范式做在 BLIP-2 模型上面。用指令微调方法的时候会额外有一条 instruction,如何借助这个 instruction 提取更有用的视觉特征是本文的亮点之一。InstructBLIP 的架构和 BLIP-2 相似,从预训练好的 BLIP-2 模型初始化,由图像编码器、LLM 和 Q-Former 组成。在指令微调期间只训练 Q-Former,冻结图像编码器和 LLM 的参数。作者将26个数据集转化成指令微调的格式,把它们分成13个 held-in 数据集用于指令微调,和13个 held-out 数据集用于 Zero-Shot 能力的评估。
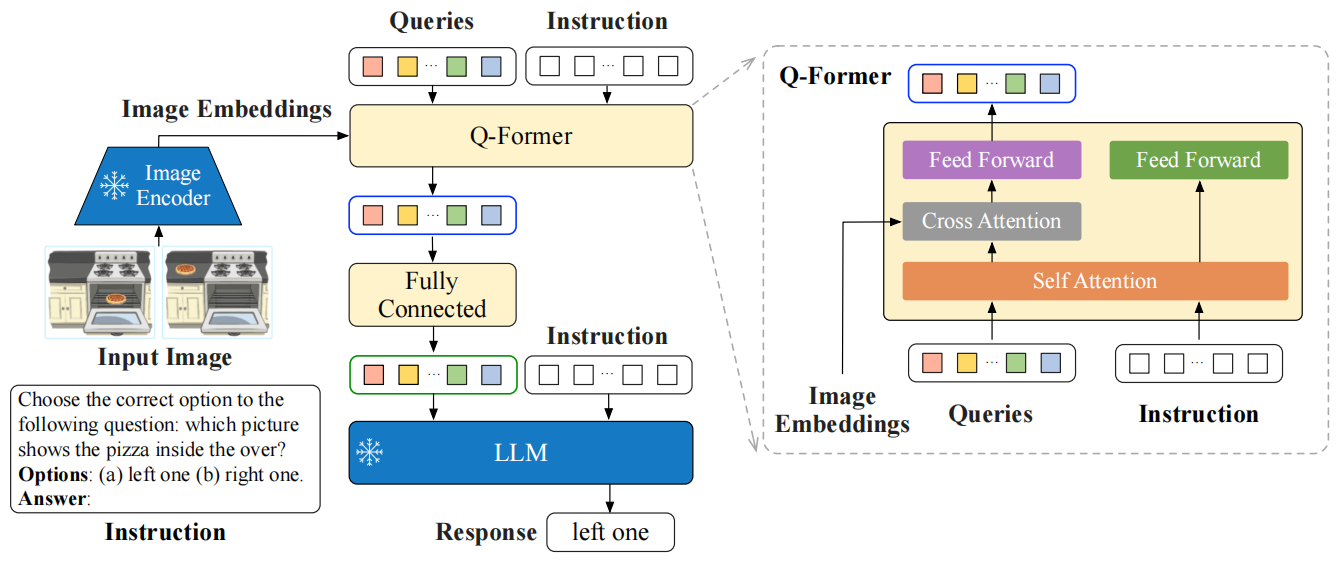
Q-Former是一种轻量级transformer结构,采用一组可学习的查询向量来提取和压缩视觉特征。
Q-Former 的输入还包括可学习的 Queries (BLIP-2 的做法) 和 Instruction。Q-Former 的内部结构如图3黄色部分所示,其中可学习的 Queries 通过 Self-Attention 和 Instruction 交互,可学习的 Queries 通过 Cross-Attention 和输入图片的特征交互,鼓励提取与任务相关的图像特征。
Q-Former 的输出通过一个 FC 层送入 LLM,Q-Former 的预训练过程遵循 BLIP-2 的两步:1) 不用 LLM,固定视觉编码器的参数预训练 Q-Former 的参数,训练目标是视觉语言建模。2) 固定 LLM 的参数,训练 Q-Former 的参数,训练目标是文本生成。
LLaMA-2-7B & Video Q-Former of Video-LLaMA
预训练的LLM及对应的视频编码器
Video-LLaMA:指令微调的用于视频理解的视听语言模型
git lfs install git clone https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-7B-Finetuned
代码相关
Q-Former
- Q-Former的实现基于BERT(BertModel),并包含自注意力和交叉注意力层。
- 交叉注意力机制在模型的不同层插入,用于处理视觉和语言特征之间的结合,这使得模型可以在多模态任务中有效地执行跨模态对齐。
- 模型包括输入embedding、编码器层和输出层,整体架构与BERT类似,但针对多模态任务进行了适配。
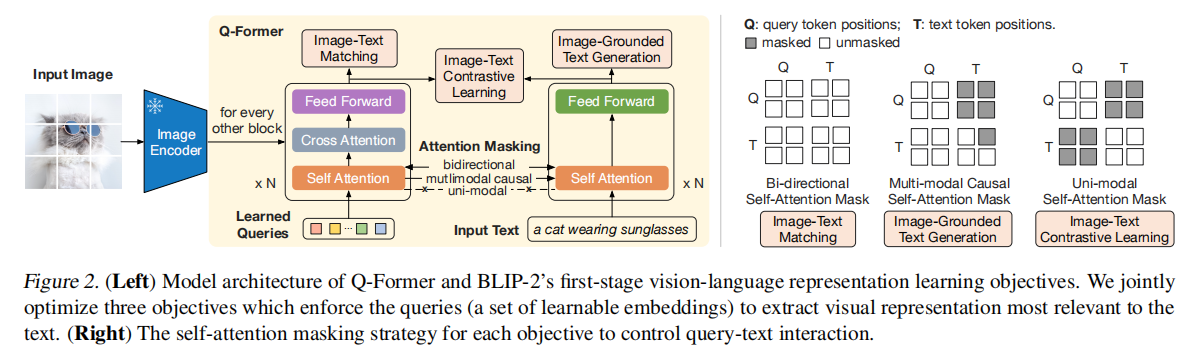
Q-Former由两个transfomer子模块组成,左边为(learnable) query encoder,右边为text encoder & decoder。记视觉模型的image encoder的输出为I。左边网络的(learnable) query为Q,右边网络的输入text为T。注意Q是一个向量集,非单个向量。它可以视为Q-Former的参数。
- 左边的transformer和视觉模型image encoder交互,提取视觉表征,右边的transformer同时作为text encoder和decoder。
- 左边的query encoder和右边的text encoder共享self-attention layer。
- 通过self attention layer,实现Q向量之间的交互。
- 通过cross attention layer,实现Q向量和I的交互。
- Q和T之间的交互,也是通过共享的self attention layer实现的,不过根据训练目标的不同,通过不同的attention mask来实现不同的交互。
class BertSelfAttention(nn.Module):
def __init__(self, config, is_cross_attention):
super().__init__()
self.config = config
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(
config, "embedding_size"
):
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (config.hidden_size, config.num_attention_heads)
)
# 初始化--设置注意力头的数量和每个头的维度
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
# 初始化查询query、键和值的线性变换
self.query = nn.Linear(config.hidden_size, self.all_head_size)
# ===如果是交叉注意力(cross-attention),键和值从编码器获取,否则从隐层获取===
if is_cross_attention:
self.key = nn.Linear(config.encoder_width, self.all_head_size)
self.value = nn.Linear(config.encoder_width, self.all_head_size)
else:
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
# 注意力得分的dropout
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
# 获取位置嵌入类型,如果是相对位置嵌入,则初始化相关嵌入层
self.position_embedding_type = getattr(
config, "position_embedding_type", "absolute"
)
if (
self.position_embedding_type == "relative_key"
or self.position_embedding_type == "relative_key_query"
):
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = nn.Embedding(
2 * config.max_position_embeddings - 1, self.attention_head_size
)
# 是否保存注意力图(用于可视化或调试)
self.save_attention = False
def save_attn_gradients(self, attn_gradients):
self.attn_gradients = attn_gradients # 注意力梯度
def get_attn_gradients(self):
return self.attn_gradients
def save_attention_map(self, attention_map):
self.attention_map = attention_map # 注意力图
def get_attention_map(self):
return self.attention_map
def transpose_for_scores(self, x):
# 将输入的张量x转置为(num_attention_heads, attention_head_size)格式
new_x_shape = x.size()[:-1] + (
self.num_attention_heads,
self.attention_head_size,
)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states,
attention_mask=None, # 注意力掩码
head_mask=None, # 注意力头掩码
encoder_hidden_states=None,
encoder_attention_mask=None, # 编码器注意力掩码
past_key_value=None, # 前一个时间步的键值对
output_attentions=False,
):
# 如果是交叉注意力,键和值来自编码器,否则从当前隐藏状态获取
is_cross_attention = encoder_hidden_states is not None
if is_cross_attention:
# 计算交叉注意力的键和值
key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
attention_mask = encoder_attention_mask # 使用编码器的注意力掩码
elif past_key_value is not None:
# 如果存在之前的键/值缓存,则将当前计算结果与缓存进行拼接
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
else:
# 计算自注意力的键和值
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
# 计算查询向量
mixed_query_layer = self.query(hidden_states)
query_layer = self.transpose_for_scores(mixed_query_layer)
# 保存当前的键/值对,用于后续步骤
past_key_value = (key_layer, value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
# 计算查询和键的点积,得到注意力得分
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
# 处理相对位置嵌入的情况
if (
self.position_embedding_type == "relative_key"
or self.position_embedding_type == "relative_key_query"
):
seq_length = hidden_states.size()[1]
position_ids_l = torch.arange(
seq_length, dtype=torch.long, device=hidden_states.device
).view(-1, 1)
position_ids_r = torch.arange(
seq_length, dtype=torch.long, device=hidden_states.device
).view(1, -1)
# 计算位置差
distance = position_ids_l - position_ids_r
positional_embedding = self.distance_embedding(
distance + self.max_position_embeddings - 1
)
positional_embedding = positional_embedding.to(
dtype=query_layer.dtype
) # fp16 compatibility
if self.position_embedding_type == "relative_key":
# 计算相对位置得分并加到注意力得分中
relative_position_scores = torch.einsum(
"bhld,lrd->bhlr", query_layer, positional_embedding
)
attention_scores = attention_scores + relative_position_scores
elif self.position_embedding_type == "relative_key_query":
# 计算查询和键的相对位置得分,并加到注意力得分中
relative_position_scores_query = torch.einsum(
"bhld,lrd->bhlr", query_layer, positional_embedding
)
relative_position_scores_key = torch.einsum(
"bhrd,lrd->bhlr", key_layer, positional_embedding
)
attention_scores = (
attention_scores
+ relative_position_scores_query
+ relative_position_scores_key
)
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# 添加注意力掩码(在BertModel前向传播中预计算)
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
# 归一化注意力得分为概率分布
attention_probs = nn.Softmax(dim=-1)(attention_scores)
if is_cross_attention and self.save_attention:
self.save_attention_map(attention_probs)
attention_probs.register_hook(self.save_attn_gradients)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs_dropped = self.dropout(attention_probs)
# Mask heads if we want to
# 如果需要掩盖特定的注意力头
if head_mask is not None:
attention_probs_dropped = attention_probs_dropped * head_mask
# 计算上下文向量(注意力概率与值的乘积)
context_layer = torch.matmul(attention_probs_dropped, value_layer)
# 调整上下文向量形状
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
outputs = (
(context_layer, attention_probs) if output_attentions else (context_layer,)
)
outputs = outputs + (past_key_value,)
return outputs参考
TimeChat:基于Q-Former的时序感知VideoLLM - 知乎 (zhihu.com)
从秒级到小时级:TikTok等发布首篇面向长视频理解的多模态大语言模型全面综述_tiktok 语音大模型-CSDN博客
https://zhuanlan.zhihu.com/p/650519771



