UrbanGPT: Spatio-Temporal Large Language Models
摘要
时空预测旨在对不断变化的动态城市场景进行预测和洞察,涵盖了时间和空间两个维度。它的目的是预测城市生活的不同方面的未来模式、趋势和事件,包括交通运输、人口流动和犯罪率等。尽管大量研究都致力于开发神经网络技术来准确预测时空数据,但需要注意的是,许多方法严重依赖于有足够的标记数据来生成精确的时空表示。不幸的是,数据稀缺的问题在实际的城市感知场景中是普遍存在的。在某些情况下,从下游场景中收集任何标记数据变得具有挑战性,这进一步加剧了问题。因此,有必要建立一个时空模型,能够在不同的时空学习场景中表现出强大的泛化能力。
受大语言模型(LLMs)的显著成就的启发,我们的目标是创建一个时空LLM,能够在广泛的下游城市任务中表现出特殊的泛化能力。为了实现这一目标,我们提出了UrbanGPT,它无缝地集成了一个时空依赖编码器与指令微调范式。这种集成使llm能够理解复杂的时间和空间相互依赖,促进在数据稀缺下进行更全面和准确的预测。为了验证我们的方法的有效性,我们在各种公共数据集上进行了广泛的实验,包括不同的时空预测任务。结果一致表明,我们的UrbanGPT,以其精心设计的架构,始终优于最先进的基准模型。这些发现突出了为时空学习建立大型语言模型的潜力,特别是在标记数据稀缺的零样本场景中。
引言
时空预测的动机源于对准确预测和获取城市环境动态本质的渴望。通过对时间和空间上不断变化的动态进行分析和理解,时空预测使我们能够预测未来城市生活各个方面的模式、趋势以及各种事件。这在城市计算领域至关重要,因为预测交通模式可以优化交通流量、减少拥堵,增强整体城市流动性[17,30]。此外,预测人口流动有助于有效的城市规划和资源分配[6,19]。再者,预测犯罪的能力可以极大地提高公共安全[31]。时空预测在塑造更智能、更高效的城市方面扮演着关键角色,最终提升城市生活质量。
在时空预测领域常用的各种神经网络架构是十分重要的。这些架构旨在捕捉和建模数据中空间和时间维度之间复杂的关系。其中一种广泛采用的架构是卷积神经网络(CNN)[14, 38, 44],它通过对输入数据应用卷积滤波器,可以有效地提取空间特征。另一类时空神经网络是循环神经网络(RNN)系列[1, 33, 42]。这些时空RNN非常适合通过维护一个可以随时间保留信息的记忆状态来实现时间依赖关系的捕捉。最近,图神经网络(GNNs)在时空预测中的应用急剧增加[35, 39, 46]。GNNs在建模数据中的复杂空间关系方面表现出色,其中每个节点对应一个空间位置,边捕捉它们之间的连接关系。
问题
挑战1:标注数据稀缺,数据无法迁移到新场景,重新训练开销巨大:虽然时空神经网络技术已被证明非常有效,但它们严重依赖于大量标记数据以生成准确的预测。实际城市场景中普遍存在数据稀缺问题,例如,由于成本高昂,在整个城市空间部署传感器来监控全市交通量或空气质量是不切实际的。此外,现有模型在应对新地区或城市预测任务时不具备良好的泛化能力,需重新训练以生成时空表征。
挑战2:LLMs和现有时空模型缺乏零样本场景下的泛化能力:如图1所示,大语言模型LLaMA可根据输入文本对流量模式进行推断。然而,它在处理具有复杂时空依赖性的数字时间序列数据方面的局限性有时会导致相反的预测结果。另一方面,预训练的基线模型能够很好地编码时空依赖关联。然而,它可能会由于对源数据集的过拟合导致其在零样本场景下表现不佳。
挑战3:如何将LLMs的出色推理能力扩展到时空预测场景:时空数据的独特特征与LLMs中所编码的知识之间存在差距,如何减少这一差距进而建立在广泛的城市任务中具有出色的泛化能力时空大语言模型是一项重大挑战。
贡献
(1) 据我们所知,这是首次尝试开发一种能够在不同数据集上预测各种城市现象的时空大语言模型,尤其是在训练样本受限的情况下。
(2)提出了时空预测模型UrbanGPT:我们提出了UrbanGPT,一种专门针对时空预测而定制的大型语言模型。UrbanGPT的核心是一种新的时空指令调整范式,它寻求将时间和空间的复杂依赖关系与llm的知识空间相结合。
- 在我们的UrbanGPT框架中,我们首先合并了一个时空依赖编码器,它利用了一个多层的时间卷积网络以捕捉时间动态。
- 然后,我们的模型涉及到对齐文本和时空信息,以使语言模型能够有效地注入时空上下文信号。这是通过使用一个轻量级对齐模块来实现的。其结果是,通过整合来自文本和时空领域的有价值的信息,生成更具表达性的语义表示
- 通过将时空依赖编码器无缝集成到指令微调范式中,有效地将时空上下文与大语言模型相结合。
为了展示我们提出的模型的优越的预测性能,我们将其与大型语言模型(LLaMA- 70B)和时空图神经网络(STGCN)进行了比较。
- 大型语言模型LLaMA可以从输入的文本中有效地推断出流量模式。然而,它在处理具有复杂时空依赖性的数字-时间序列数据方面具有局限性,有时会导致相反的交通趋势预测。
- 另一方面,预先训练的基线模型显示了对时空依赖性的强烈理解。然而,它可能会对源数据集进行过拟合,并且在零样本场景下表现不佳,这表明它对现有时空预测模型的泛化能力有限。
- 相比之下,我们提出的模型实现了对特定领域的时空知识和语言建模能力的和谐集成。这使我们能够在数据匮乏的情况下做出更准确和可靠的预测
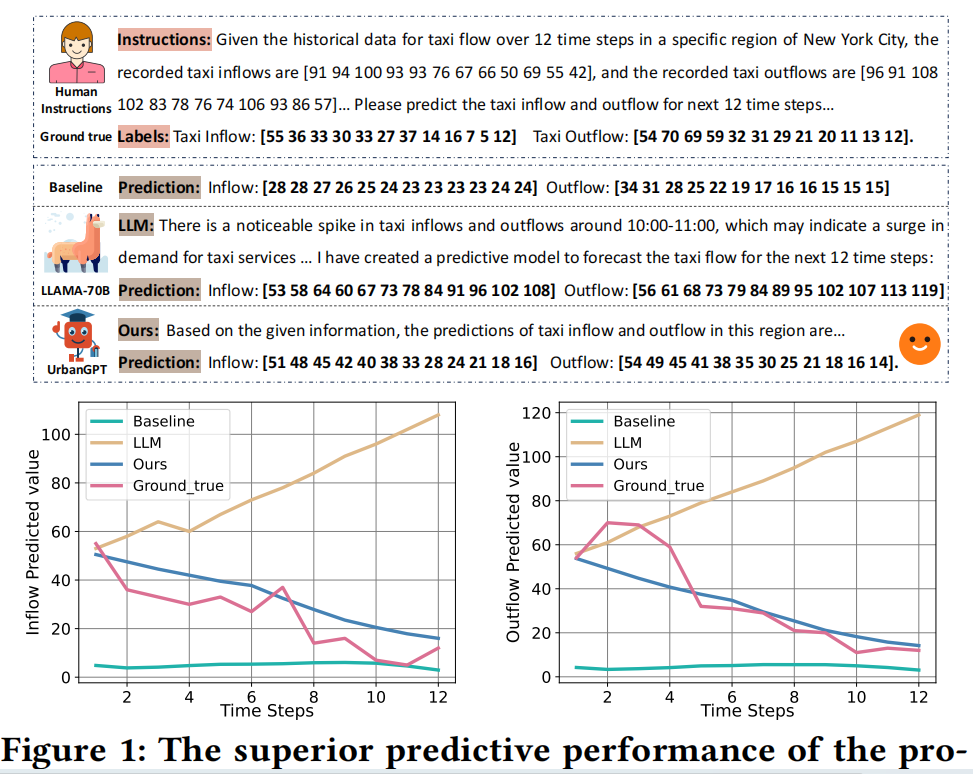
图1:与大型语言模型(LLaMA-70B)和时空图神经网络(STGCN)相比,该模型在零样本交通流预测场景中具有优越的预测性能。
(3) 在现实世界数据上进行的大量实验证明了本文提出的UrbanGPT在零样本时空学习场景中具有出色的泛化能力。这些发现突显了该模型的强大泛化能力,表明它在准确预测和理解时空模式方面的有效性,即使在零样本场景下也是如此。
准备工作
时空数据 Spatio-Temporal Data.
时空数据可以表示为三维张量:X∈R^𝑅×𝑇×𝐹。张量中的每个元素X𝑟、𝑡、𝑓都对应于在第𝑟个区域的第𝑡个时间间隔上的第𝑓个特征的值。
- 考虑预测一个城市地区的出租车交通模式。在这种情况下,数据可以表示从𝑡到𝑡−1的给定时间段(例如,30分钟的间隔)内,特定区域(例如,第𝑟个空间区域)内出租车的流入和流出。‘
时空预测 Spatio-Temporal Forecasting
时空预测:在时空预测任务中,一个常见的场景是利用历史数据来预测未来的趋势。具体来说,其目标是根据从前面的𝐻步骤中获得的信息来预测下一个𝑃时间步长的数据。
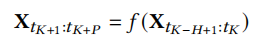
函数𝑓(·)代表了一个利用历史数据进行有效训练的时空预测模型。时空预测任务主要可分为两大类:
- 回归预测,包括预测交通流量或出租车需求等连续值;
- 分类预测,其目标是分类犯罪发生预测等事件。
为了优化函数f,基于时空场景的具体特征使用了不同的损失函数
时空零样本学习 Zero-Shot Learning
尽管目前的时空学习方法是有效的,但它们在有效地推广到各种下游时空学习场景时经常遇到困难。在本研究中,我们的重点是解决时空零样本场景的挑战,我们的目标是学习下游时空预测数据集或任务里没见过的数据。这可以正式定义如下:
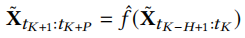
在这个特殊的场景中,预测函数𝑓ˆ(·)负责预测以前没有遇到过的下游任务的时空数据˜X。需要注意的是,模型𝑓ˆ(·)并不是针对目标数据进行专门训练的。
方法
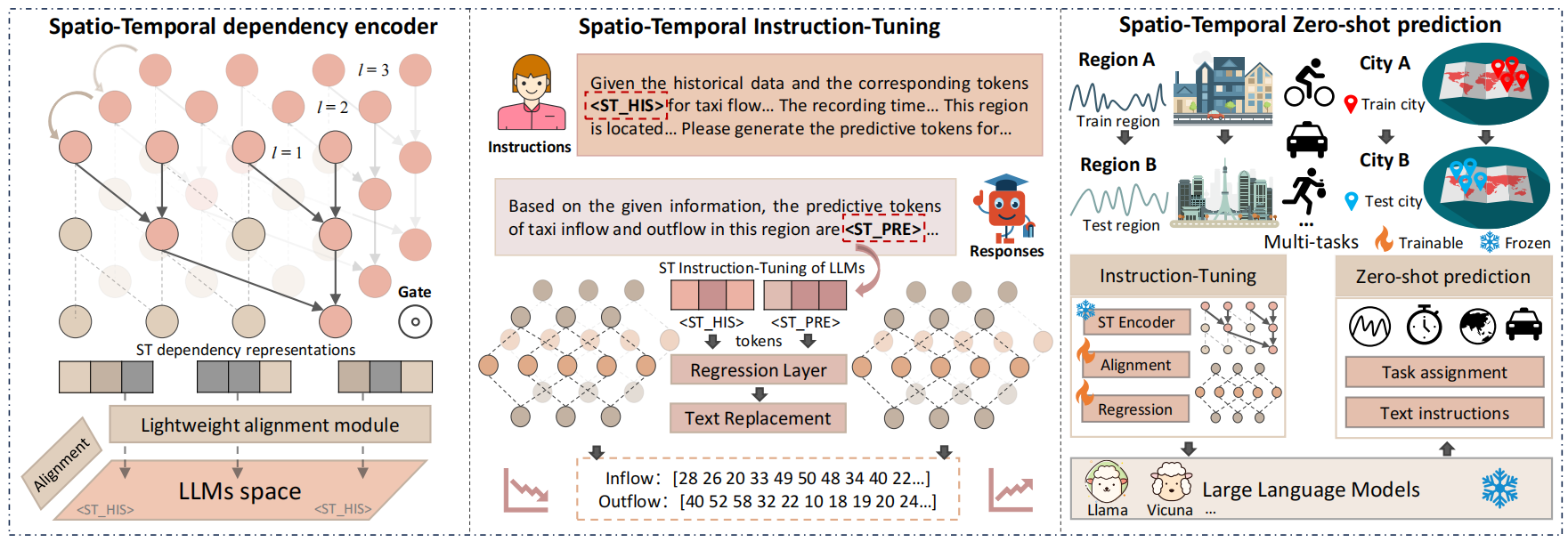
图2:所提出的时空语言模型UrbanGPT的总体架构。
时空依赖编码器
集成一个包含多层次时间卷积网络( a multi-level temporal convolutional network.)的时空编码器来增强大型语言模型在时空上下文中捕获时间依赖性的能力。
具体来说,我们的时空编码器由两个关键组件组成:门控扩散(空洞)卷积层(a gated dilated convolution layer )和多层次关联注入层(a multi-level correlation injection layer)
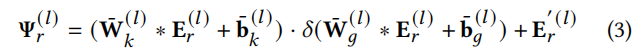
初始化时空嵌入:Er∈R^T×d。这种嵌入是通过一个线性层来增强原始数据X而获得的。
为了解决梯度消失的问题,我们使用了一个E𝑟切片,表示为Er‘,由扩张的卷积核的大小决定。该切片用于执行残差操作。
使用一维扩散卷积核W¯k,
编码时间关联,相应偏置项bk,bg属于R^dout。Sigmoid激活函数δ用于控制多层卷积运算的信息保留程度。在进行门控时间扩张卷积层编码后,我们能够有效地捕获多个时间步长中的时间依赖性,从而生成时间表示。
这些表示包含不同级别的时间依赖关系,反映了各种具有粒度感知的时间演化模式。为了保留这些信息模式,我们引入了一个多层次关联注入层

- 其中Ws∈R^Ts×dout×d′out是形如W¯k的卷积核,经过L层编码后,我们使用一个简单的非线性层融合门控扩散卷积层和多层次关联注入层的结果,最终的时空依赖性表征表示为Ψ~∈R^R×T×d
- 为了处理下游可能出现的各种城市场景集,本文提出的时空编码器在建模空间相关性时独立于图结构。因为在零样本预测环境中,实体之间的空间关系可能是未知的或难以确定的。通过不依赖于显式的图结构,我们的编码器可以有效地处理广泛的城市场景,在这些场景中,空间相关性和依赖性可能会发生变化,或者很难预先定义。这种灵活性使我们的模型能够适应并表现良好,确保其在广泛的城市环境中的适用性。
时空指令微调
时空文本对齐
- 为了使语言模型能够有效地理解时空模式,对齐文本信息和时空信息是至关重要的。这种对齐允许融合不同模态,从而产生信息更丰富的表示。
- 通过整合来自文本和时空领域的上下文特征,我们可以捕获互补信息,提取更具表达力和意义的更高层次的语义表示。为了实现这一目标,我们使用了一个轻量级的对齐模块来投影时空依赖表示˜Ψ。这个投影涉及到使用线性层参数W𝑝∈R^𝑑×𝑑𝐿和b𝑝∈R^𝑑𝐿,其中𝑑𝐿表示语言模型(llm)中常用的隐藏维度。
- 所得到的投影,表示为H∈R^𝑅×𝐹×𝑑𝐿,在指令中使用特殊的标记表示为:
, ,…, , 。在这里, 和 作为标识时空的开始和结束的标识符。这些标识符可以通过扩展其词汇量来包含在大语言模型中。占位符 表示时空标记,并对应于隐藏层中的投影H。通过使用该技术,该模型获得了识别时空依赖性的能力,从而提高了其在城市场景中成功执行时空预测任务的熟练程度。
时空提示词(prompt)指令
在时空预测的场景中,时间和空间信息都包含了有价值的语义细节,有助于模型理解特定上下文的时空模式。例如,清晨和高峰时间段的交通流量有很大的不同,并且商业区和住宅区之间的交通模式也存在差异。因此,将时间和空间信息表示为提示文本对时空预测任务是有益的。
我们利用大语言模型的文本理解能力来编码这些信息。在UrbanGPT框架中,我们集成了多粒度的时间信息和空间细节,作为大语言模型的指令输入。
- 时间信息包括一周的日期和时间,一天的时间等因素。
- 而区域信息包括城市、行政区域和附近的兴趣点(POI)数据等,如图3所示。
- 通过合并这些不同的元素,UrbanGPT能够识别和理解复杂的时空环境下不同区域和时段的时空模式,从而增强其零样本推理能力。
时空信息指令文本的设计如图3所示。图3:编码时间和位置感知信息的时空提示指令的说明。

LLM的时空指令微调
使用指令微调LLMs以生成文本格式的时空预测存在两个挑战。
- 首先,时空预测通常依赖于数值数据,其结构和模式与语言模型擅长处理的自然语言不同,后者侧重于语义和句法关系。
- 其次,LLMs通常使用多分类损失进行预训练以预测词汇,从而得到潜在结果的概率分布。而回归任务则需要连续值分布。
- 也就是说llm是一个词一个词的预测,而回归任务需要直接得到一组连续的数值分布
为了解决这些挑战,UrbanGPT采用了一种不同的策略,===不直接预测未来的时空值,而是生成辅助预测过程的预测标记(token)===。
这些标记随后通过回归层,将隐藏表示映射为生成更准确的预测值:
(STLlama 409-433)
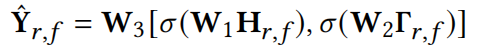
预测结果,记为ˆY𝑟,𝑓∈R^𝑃,使用线性整流激活函数(ReLU),用𝜎表示。预测标记的隐藏表示,表示为Γ𝑟,𝑓∈R^𝑑𝐿,作为大型语言模型(LLMs)词汇表中的一个新术语被引入。回归层使用权重矩阵W1∈R𝑑‘×𝑑𝐿、W2∈R𝑑’×𝑑𝐿和W3∈R𝑃×2𝑑‘表示,其中[·,·]表示连接操作。**虽然预测token的概率分布保持相对稳定,但其隐藏的表征包含了丰富的时空上下文属性,从而捕获了动态的时空相互依赖性。这使得我们的模型能够通过利用这些上下文信息来提供精确的预测。
模型优化
- 在基线模型[1,7]的基础上,我们采用绝对误差损失作为回归损失函数。这种选择使我们能够有效地处理各种城市场景中的预测。
- 此外,我们引入了一个分类损失作为一个联合损失,以满足不同的任务需求。
- 为了确保最佳的性能,我们的模型会根据特定的任务输入来优化不同的损失。例如,我们对交通流量预测等任务使用回归损失,而对犯罪预测等任务使用分类损失。这种方法使我们的模型能够有效地解决每个任务所带来的独特挑战
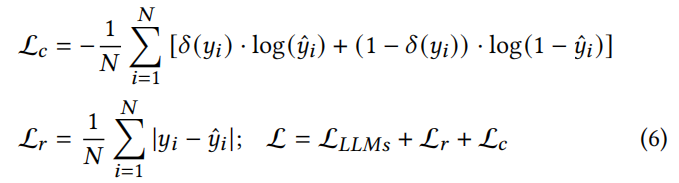
这里,𝑦𝑖表示来自ˆY的一个样本,𝑁表示样本总数,计算为𝑅、𝑇和𝐹的乘积。我们在我们的模型中使用了各种损失函数,包括Lc–二元交叉熵损失;L𝑟表示回归损失,以及在我们的时空语言模型中采用的交叉熵损失。为了从预测中获取概率分布,我们使用了用𝛿表示的sigmoid激活函数。这些损失函数在我们的模型中都扮演着特定的角色,使我们能够根据需要有效地处理分类、回归和语言建模任务。
超参数
超参数设置。时间编码器中膨胀卷积核的参数设置如下:𝑑𝑖𝑛、𝑑𝑜𝑢𝑡、𝑑‘𝑜𝑢𝑡均设置为32,膨胀因子为1。对于我们的预测任务,我们的目标是基于之前的12个步骤来预测数据的下一个12个步骤。历史记录长度(𝐻)和预测记录长度(𝑃)均设置为12。投影层参数配置为𝑑设置为64,𝑑𝐿设置为4096。最后,将回归层的隐层参数𝑑‘设置为128。
评估
关键问题:
- RQ1:UrbanGPT在不同的零样本时空预测任务中的性能和泛化能力是什么?
- RQ2:与现有的时空模型相比,UrbanGPT在经典监督场景中的表现如何?
- RQ3:提出的关键组件为提高我们的UrbanGPT模型的能力带来了哪些具体的贡献?
- RQ4:所提出的模型能否稳健地处理不同时空模式的预测情景?
实验设置
数据集
为了评估所提出的模型在预测不同城市计算场景的时空模式方面的有效性,我们使用四个不同的数据集进行了实验:纽约出租车、纽约自行车、纽约犯罪和芝加哥出租车。
为了便于分析,我们根据经纬度信息将城市划分为类似网格的区域。在特定的时间间隔内,我们汇总了每个区域的统计测量值。
例如,这涉及到计算区域A30分钟周期内的出租车流入和流出的数量,或确定区域B一天内的盗窃事件的数量。此外,利用不同区域的纬度和经度,兴趣点(POIs)数据可以通过地图服务提供的api获得。
纽约市的出租车数据集包含263个区域,每个区域的面积约为3公里x3公里。该数据集的时间采样间隔为30分钟。纽约自行车和纽约犯罪数据集包括2162个地区,每个地区都由一个1公里x1公里的网格代表。纽约自行车的采样间隔也是30分钟,而纽约犯罪的采样间隔是1天。所有数据集涵盖了纽约市从2016年1月1日至2021年12月31日的时间段。芝加哥出租车数据集包括77个区域,每个区域的长度约为4公里x4公里。该数据集包括从2021年1月1日至2021年12月31日期间的所有出租车数据,时间采样间隔为30分钟。
评估协议
为了研究大型语言模型在分析不同地区的不同时空数据方面的能力,我们选择了来自纽约市不同地区的出租车、自行车和犯罪数据的一个子集作为我们的训练集。
零样本学习场景:我们通过预测来自纽约市甚至芝加哥那些在训练阶段未见过的地区的未来时空数据来评估模型的性能。
监督学习场景:我们使用来自训练集相同区域的未来数据来评估该模型。
回归任务:我们在所有基线模型上保持了一致的训练和测试方法。
在涉及犯罪数据的分类任务时,我们使用二元交叉熵作为损失函数对模型进行训练和测试。
我们的实验是使用稳健的vicuna-7b [49]作为UrbanGPT的基础大型语言模型进行的。关于我们的方法和实验设置的更全面的理解,请参阅附录中的详细信息。
评估指标
对于回归任务,我们使用MAE(平均绝对误差)和RMSE(均方根误差)作为评价度量。这些指标量化了预测结果和实际标签之间的差异,较低的值表明优越的性能[11,48]。
在分类任务的情况下,我们使用召回率和Macro-F1作为评估指标来评估绩效。召回度量了模型正确识别积极实例的能力,而Macro-F1是一个综合的性能度量,它结合了精度和召回率,提供了分类精度[10,29]的总体度量。
基线模型
我们与10个高级模型进行了彻底的比较:
(1)在基于rnn的时空预测方法类别中,我们将我们提出的方法与AGCRN [1]、DMVSTNET [38]和ST-LSTM [32]进行了比较。这些方法利用rnn进行建模和预测。
- ST-LSTM[32]:它结合了长短期记忆来捕获时空数据中的时间依赖性。
- AGCRN[1]:rnn被用来捕获时间相关性,允许表示随着时间的推移的进化模式。
- DMVSTNET[38]:在这种方法中,rnn被用来有效地建模时间依赖关系,捕获随时间演变的模式。此外,利用卷积网络和全连接层来捕获局部空间相关性,并建立有意义的空间关系。
(2)基于gnn的时空模型主要利用图神经网络来捕获空间相关性,并整合时间编码器来捕获时空关系。我们与这类模型进行了比较,包括GWN [36],MTGNN [35],STSGCN [25],TGCN [46],和STGCN [41].
- GWN[36]:它结合了一个可学习的图结构和一维卷积来有效地学习时空依赖关系。
- MTGNN[35]:它利用一个可学习的图结构来建模多元的时间相关性。MTGNN使用一维膨胀卷积来生成时间表示。
- TGCN[46]:该模型结合了图神经网络(GNNs)进行空间相关建模和递归神经网络(RNNs)进行时间相关建模。
- STGCN[41]:它分别使用门控时间卷积和gnn来建模时间和空间依赖性。
- STSGCN[25]:它引入了一个时空图的构造来学习相邻时间步长之间的空间相关性。
(3)在基于注意的时空模型类别中,该方法采用注意机制来建模时空相关性。我们在这一类中比较的模型是ASTGCN [7]和STWA [5]。
- ASTGCN[7]:该方法采用注意机制来捕获多粒度的时间相关特征。
- STWA[5]:该模型将个性化的时间和空间参数纳入注意模块,允许对动态时空相关性的建模
零样本预测性能(RQ1)
相同城市内未见区域的预测
跨区域场景需要使用来自城市内某些区域的数据来预测模型没有遇到的其他区域的未来情况。通过对模型在跨区域预测中的表现的全面分析,我们可以注意到三个重要的观察结果:
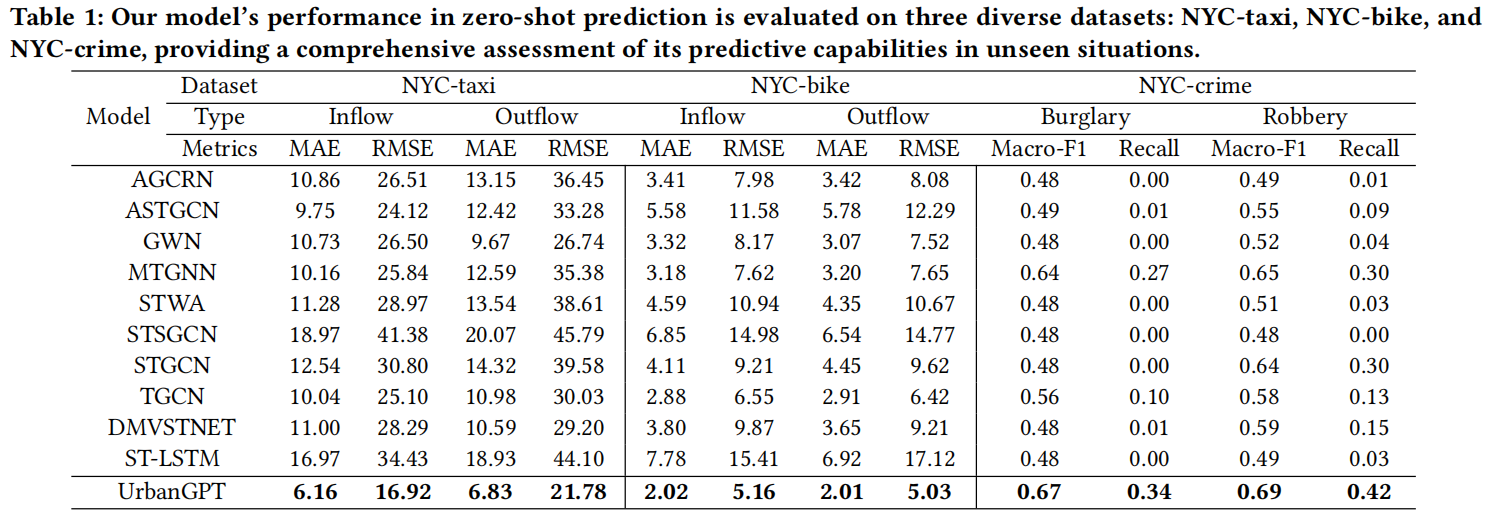
(1)优越的零样本预测性能。表1中的结果突出了所提出的模型在不同数据集上的回归和分类任务中的卓越性能,超过了零样本预测中的基线模型。UrbanGPT的成功可以归因于两个关键因素。
- 时空-文本对齐。时空上下文信号与语言模型的文本理解能力的对齐对模型成功起着关键作用。这种融合使模型能够有效地利用从时空信号中编码的城市动态和由大语言模型提供的对文本上下文的全面理解,从而扩展了模型在零样本场景的预测能力。
- 时空指令微调。自适应调整过程使LLMs能够有效地整合指令中的关键信息,增强其对空间和时间因素之间复杂关系和依赖性的理解。 通过将时空指令微调与时空依赖编码器无缝合并, UrbanGPT成功地保留了通用且可转移的时空知识,进而实现零样本场景中的精确预测。
(2)增强了对城市语义的理解。城市语义提供了对多样的空间和时间特性的重要见解。所提出的方法在各种数据集上对模型进行训练,丰富其对不同时段和地理位置的时空动态的理解。相比之下,基准模型往往优先考虑编码时空依赖关系,忽视了区域、时段和数据类别之间的语义差异。通过将全面的语义信息注入UrbanGPT中,我们显著增强了其在先前未见的区域中进行准确零样本预测的能力。
(3)稀疏数据场景中的性能提升。稀疏数据环境中预测时空模式是具有挑战性的,因为当数据点稀缺时,模型容易出现过拟合。在预测犯罪等情况下,数据通常是稀疏的,在这一条件下,基线在跨区域预测任务中表现困难,导致召回率低,表明可能存在过拟合的问题。为了克服这个限制,我们的模型通过使用有效的时空指令微调范式,将时空学习与大语言模型相结合。通过融入丰富的语义见解,所提出的方法增强了模型的时空表示能力,使其能够有效处理稀疏数据,并实现改进的预测准确性。
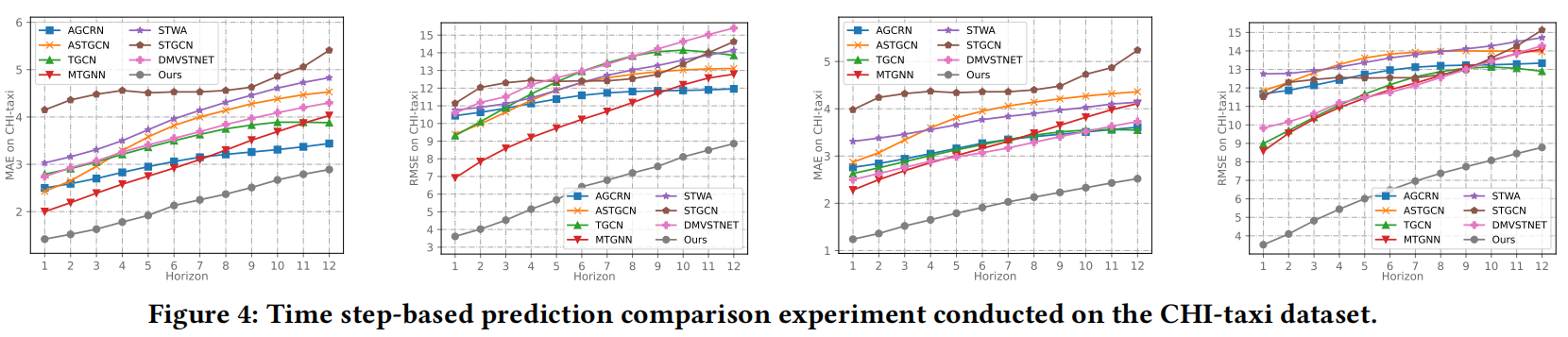
跨城市预测任务
为评估模型在跨城市预测任务中的性能,我们对芝加哥出租车数据集进行了测试(该数据集没有出现在训练阶段)。如图4所示,结果显示模型在每个时间步长都始终优于比较方法,这说明UrbanGPT能够对跨城市知识进行有效的转移。通过整合时空编码器与时空指令微调范式,模型有效地捕获了普遍及特殊的时空模式。此外,通过考虑不同的地理信息和时间因素以及学到的转移知识,模型具备将相似功能区域和历史时期所表现出的时空模式进行关联的能力,使其能够做出更准确的预测。
- 多步预测的一致性:我们的模型在每个时间步长上始终优于比较方法。值得注意的是,它在短期和长期的时空预测中都保持了显著的优势,证明了我们提出的模型在跨城市预测场景中的鲁棒性。
- 跨城市有效知识迁移:芝加哥出租车数据集预测结果验证了我们的模型在跨城市场景中的优越能力。这种增强可以归因于时空编码器与时空指令调整范式的集成。通过合并这些组件,我们的模型有效地捕获了通用的和可转移的时空模式,使它能够做出准确的预测。此外,通过考虑不同的地理信息和时间因素以及学习到的知识转移,我们的模型成功地关联了相似功能区和历史时期的时空模式。
典型有监督预测任务(RQ2)
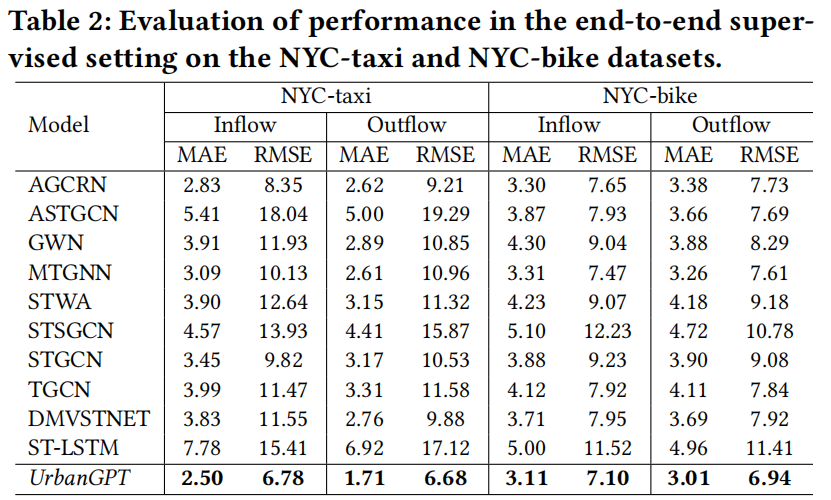
本节研究了我们的UrbanGPT在端到端监督预测场景中的预测能力,如表2所示。
- 增强的长期预测能力:我们利用时间间隔跨度更广的测试数据集来测试模型在长期时空预测中的有效性。例如,使用2017年的数据训练模型,并使用2021年的数据进行评估。结果表明,我们的UrbanGPT在基线相比具有显著的优势,突显了其长期时间跨度场景的卓越泛化能力。此特性减少了频繁重新训练或增量更新的需要,使模型更符合实际应用。此外,实验还证实,加入额外的文本知识不会阻碍模型性能或引入噪声,从而进一步验证了利用大型语言模型增强时空预测任务的可行性。
- 空间语义理解:准确捕捉空间相关性在时空预测领域至关重要。传统的方法通常使用图网络或注意机制来分析这些相关性。缺乏专门的空间相关模块的模型,如LSTM,在忽视空间环境时往往表现不佳。相比之下,我们的模型通过在文本输入中集成广泛的地理和感兴趣点(POIs)数据来弥补了显式空间编码器的缺失。这种方法使模型能够在更高的语义层次上理解具有相似功能的区域的共享特征。因此,它推导出不同功能区之间的关联模式,并有效地代表了不同区域之间的相互联系。
消融研究(RQ3)
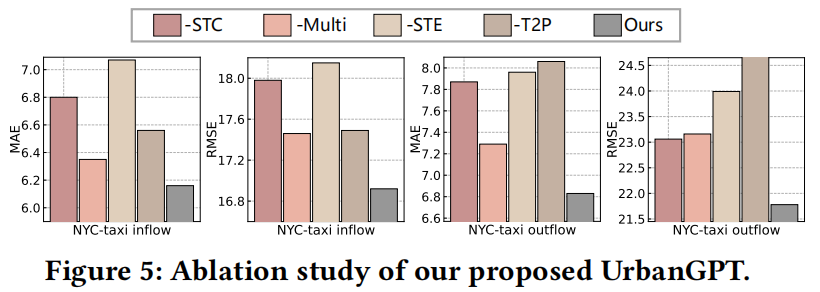
本节研究了不同关键组件对模型性能的影响,如图5所示。我们严格的测试主要围绕着使用纽约市出租车数据集的零样本场景展开。通过我们的分析,我们将不同模块所提供的好处提炼为四个关键点。
(1) 时空上下文的影响:-STC。从指示文本中移除时空信息后出现了性能衰减,这可能由于缺乏时间信息,使得模型仅依赖于时空编码器来编码与时间相关的特征和执行预测任务。此外,空间信息的缺失阻碍了模型捕捉空间相关性的能力,使得分析不同区域的不同时空模式具有挑战性。
(2) 使用多个数据集进行指令微调的影响:-Multi。我们仅在NYC-taxi数据集进行训练。由于缺乏不同的城市指标的信息,限制了模型充分揭示城市时空动态的能力。通过整合来自多个来源的不同时空数据,模型可以有效地捕获不同地理位置的独特特征及演化的时空模式。
(3) 时空编码器的影响:-STE。我们从模型中移除了时空编码器。结果表明,时空编码器的缺失显著地阻碍了大语言模型在时空预测场景中的预测性能。这强调了所提出的时空编码器在提高模型的预测能力方面所发挥的关键作用。
(4) 指令微调中的回归层:T2P。我们直接指示UrbanGPT以文本格式生成其预测。次优的性能表现主要是由于训练过程中依赖于多类损失来进行优化,导致模型的概率输出和时空预测所需的连续值分布之间的不匹配。为了弥补这一差距,我们在模型中加入了一个回归预测器,显著提高了它在回归任务生成更精确的数值预测的能力。
模型鲁棒性研究(RQ4)
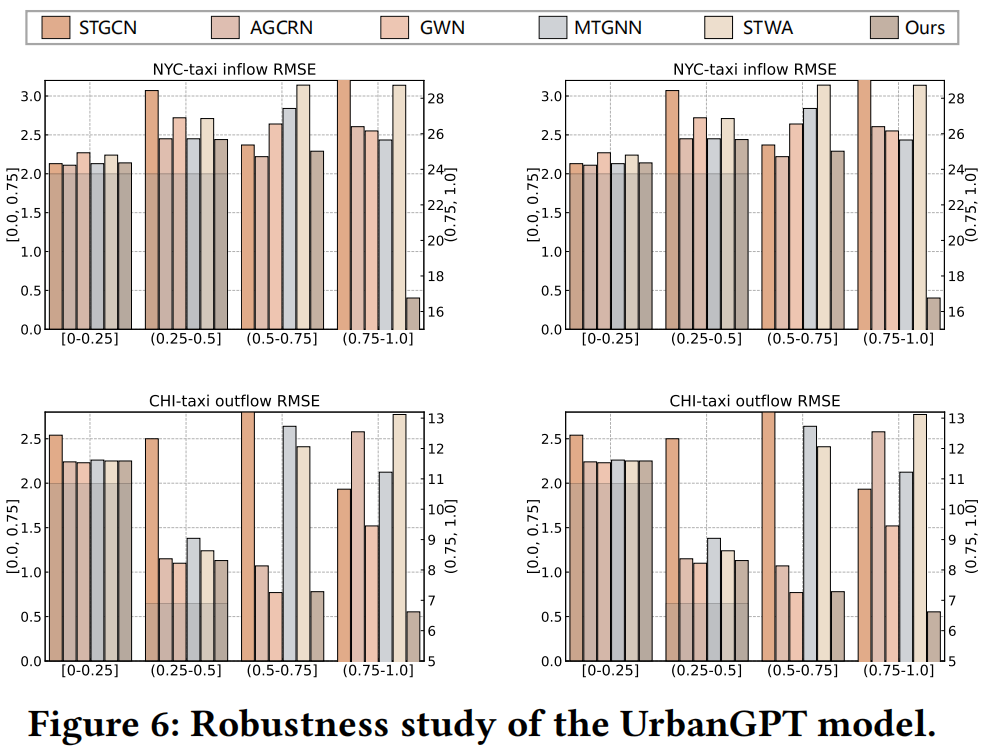
在本节中,我们将重点评估我们的UrbanGPT在不同时空模式场景下的稳健性。我们根据数值变化的大小对区域进行分类,如在特定时间段内的出租车流量。较低的方差表明稳定的时间模式,而较高的方差表明时空模式多样化的地段,如活跃商业区或人口稠密地区。如图6所示,大多模型在方差较低的区域表现良好,因为这些区域的时空模式相对稳定。然而,基线在方差较高的区域中表现不佳,特别是在方差处于 (0.75, 1.0] 范围的区域,这一限制可能源自基线模型在零样本场景下难以推断未见区域的复杂时空模式。在实际应用中,人口密集或繁华区域的准确预测对于城市治理至关重要,例如交通灯控制和安全调度。UrbanGPT在(0.75, 1.0]区间表现出显着的性能提升,突显了所提出方法的强大的零样本预测能力。
案例研究
在我们的案例研究中,我们彻底评估了几个大型语言模型(llm)的零样本时空预测。我们强调了这些模型在直接从数字地理序列数据中理解时空模式方面所面临的挑战。相比之下,我们展示了我们提出的UrbanGPT框架在捕获通用时空模式方面的特殊性能,以及它在各种零样本时空预测场景中有效推广的能力。
结果表明,各种llm能够基于这些指令生成预测,从而突出了提示设计的有效性。例如,ChatGPT依赖于历史平均值,而不是在其预测中明确地组合时间或空间数据。Llama-2-70b分析了特定的时间段和区域,但它在编码数值时间序列依赖性方面遇到了挑战,导致了次优的预测性能。另一方面,Claude-2.1有效地总结和分析了历史数据,利用高峰时段模式和兴趣点来实现更准确的交通趋势预测。
我们提出的UrbanGPT通过一个时空指令调优范式,无缝地将时空上下文信号与大型语言模型(llm)的推理能力集成起来。这种整合导致了预测数值和时空趋势的显著改进。
表3:我们用所提供的instruction测试了不同llm对纽约市自行车流量的零样本预测

相关工作
深度时空预测模型。深度时空预测方法由于其出色的性能而在深度学习中获得了突出的地位。这些模型通常由两个组成部分组成:时间依赖建模和空间相关编码。早期的模型,如D-LSTM [42]和ST-resnet [44],使用rnn和卷积网络来建模时间和空间依赖性。图神经网络(GNNs)被证明是空间相关建模的一种自然拟合,就像在STGCN [41]和DCRNN [13]等模型中所看到的那样,它们利用了基于节点距离的图结构。可学习的区域级图结构[35,36]和动态时空图网络[8,47]等技术进一步增强了空间相关建模。
此外,研究人员还探索了诸如多尺度时间学习[33]和多粒度时间学习[7]来编码时间依赖性的方法。这些策略能够捕获诸如长期和短期相关性以及周期性等特征。这些进步有助于时空预测的进展。然而,值得注意的是,这些研究大多数是为监督环境量身定制的,有限的研究和发展集中在零样本时空预测。这是一个需要进一步探索的重要领域。
时空预训练。时空预训练技术最近受到了广泛的研究关注。这些技术主要关注于生成式[15,23]和对比式[45]预训练模型,以提高下游任务的预测性能。对少样本学习场景[12,18]的训练前微调框架也进行了广泛的探索,旨在通过对齐源数据和目标数据来提高知识的可转移性。然而,这些方法需要对目标数据进行训练或微调,并且缺乏零样本预测能力。在这项工作中,我们通过提出UrbanGPT来解决下游城市场景中数据稀缺的挑战。我们的模型展示了在各种场景中很好地泛化的能力,减轻了对目标数据进行广泛训练或微调的需要。
大型语言模型。大型语言模型[3,20]的出现由于其在文本理解和推理等任务中前所未有的机器性能而引起了广泛的关注。这些模型已经成为一个热点话题,展示了从智能算法发展到人工智能的发展潜力。开源的大型语言模型,如Llama [27,28]、Vicuna [49]和ChatGLM [43]已经发布,导致研究人员探索它们在各个领域的应用,通过这些模型中的领域知识来增强迁移学习能力。在计算机视觉领域,研究人员将多模态大型语言模型与即时学习方法相结合,以实现下游任务[24,50,51]的零样本预测。此外,大型语言模型在图推理[2,4,26]和推荐[9,22,34]中的能力已被广泛研究。然而,在时空预测领域,利用大型语言模型进行零样本时空预测任务仍未得到很大程度的探索
总结
我们提出了UrbanGPT,一种时空大型语言模型,以很好地推广到不同的城市场景。为实现时空上下文信号与LLMs无缝对齐,本文引入了一种时空指令微调范式。这赋予UrbanGPT在各种类型的城市数据中学习通用和可迁移的时空模式的卓越能力。大量实验分析展示了UrbanGPT架构及其关键组件的卓越有效性。
然而,需要注意的是,虽然结果是令人鼓舞的,但在未来的研究中仍然存在待解决的限制。作为第一步,我们积极收集更多种类的城市数据,以增强和完善UrbanGPT在更广泛的城市计算领域的能力。此外,理解UrbanGPT的决策过程也是重要的。虽然该模型表现出卓越的性能,但提供可解释性同样重要。未来的研究也将集中于赋予UrbanGPT模型解释其预测的能力。
代码解析
训练UrbanGPT
准备预训练checkpoint
checkpoint文件包含的内容很多,比如:模型参数、优化器状态、训练进度等信息。checkpoint文件的主要作用是在训练过程中保存模型状态,以便在训练过程中发生中断或结束后能够恢复模型的状态,或者在推断时使用已经训练好的模型参数。
UrabnGPT基于以下优秀的现有模型进行训练。请按照指示准备checkpoint:
Vicuna:
准备我们的基本模型Vicuna,它是一个指令微调过的的chatbot,也是我们实现中的base model。请下载权重here. 我们通常使用具有7B参数的v1.5和v1.5-16k模型。您应该更新vicuna中的config.json,例如,v1.5-16k中的Json ‘可以在config.json中找到。
Spatio-temporal Encoder:
我们使用一个简单的基于TCN的时空编码器对时空依赖进行编码。通过典型的多步时空预测任务对st_encoder的权值进行预训练。Spatio-temporal Train Data:
我们利用由纽约市出租车、自行车和犯罪数据组成的预训练数据,包括时空统计、记录的时间戳和有关区域兴趣点(poi)的信息。这些数据被组织在train_data中。请下载并放在。/UrbanGPT/ST_data_urbangpt/train_data 下。
指令微调
- Start tuning: 在上述步骤之后,您可以通过在urbangpt_train.sh中填充空白来开始指令调优。示例:
# to fill in the following path to run our UrbanGPT!
model_path=./checkpoints/vicuna-7b-v1.5-16k
instruct_ds=./ST_data_urbangpt/train_data/multi_NYC.json
st_data_path=./ST_data_urbangpt/train_data/multi_NYC_pkl.pkl
pretra_ste=ST_Encoder
output_model=./checkpoints/UrbanGPT
wandb offline
python -m torch.distributed.run --nnodes=1 --nproc_per_node=8 --master_port=20001 \
urbangpt/train/train_mem.py \
--model_name_or_path ${model_path} \
--version v1 \
--data_path ${instruct_ds} \
--st_content ./TAXI.json \
--st_data_path ${st_data_path} \
--st_tower ${pretra_ste} \
--tune_st_mlp_adapter True \
--st_select_layer -2 \
--use_st_start_end \
--bf16 True \
--output_dir ${output_model} \
--num_train_epochs 3 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 2400 \
--save_total_limit 1 \
--learning_rate 2e-3 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--tf32 True \
--model_max_length 2048 \
--gradient_checkpointing True \
--lazy_preprocess True \
--report_to wandb评估UrbanGPT
准备 Checkpoints and Data
- **Checkpoints: **您可以尝试通过使用自己的模型或我们发布的检查点来评估UrbanGPT。
- Data: 我们为纽约出租车数据拆分测试集,并为评估创建指令数据。请参阅[评估]https://huggingface.co/datasets/bjdwh/ST_data_urbangpt)
运行Evaluation
您可以通过在[urbangpt_eval.sh](urbangpt_eval.sh)填充空白开始第二阶段tuning。下面是一个示例:
# to fill in the following path to evaluation!
output_model=./checkpoints/tw2t_multi_reg-cla-gird
datapath=./ST_data_urbangpt/NYC_taxi_cross-region/NYC_taxi.json
st_data_path=./ST_data_urbangpt/NYC_taxi_cross-region/NYC_taxi_pkl.pkl
res_path=./result_test/cross-region/NYC_taxi
start_id=0
end_id=51920
num_gpus=8
python ./urbangpt/eval/run_urbangpt.py --model-name ${output_model} --prompting_file ${datapath} --st_data_path ${st_data_path} --output_res_path ${res_path} --start_id ${start_id} --end_id ${end_id} --num_gpus ${num_gpus}代码
扩张卷积
class DilatedInception(nn.Module):
def __init__(self, cin, cout, dilation_factor=2):
super(DilatedInception, self).__init__()
self.tconv = nn.ModuleList() # 创建一个列表以容纳多个卷积层
self.kernel_set = [2, 3, 6, 7] # 不同的卷积核大小
cout = int(cout/len(self.kernel_set)) # 计算每个卷积的输出通道数
for kern in self.kernel_set:
# 添加具有不同卷积核大小和扩张率的卷积层,一维扩散卷积核
self.tconv.append(nn.Conv2d(cin, cout, (1, kern), dilation=(1, dilation_factor)))
def forward(self, input):
x = []
# 使用定义的层执行卷积操作
for i in range(len(self.kernel_set)):
x.append(self.tconv[i](input))
for i in range(len(self.kernel_set)):
x[i] = x[i][..., -x[-1].size(3):] # 沿最后一个维度切片张量
x = torch.cat(x, dim=1) # 沿着通道维度拼接张量
return xST_Encoder 前向传播
def forward(self, source):
inputs = source
# 转置维度以进行正确的卷积操作
inputs = inputs.transpose(1, 3) # (batch_size, feature_dim, num_nodes, input_window)
assert inputs.size(3) == self.input_window, 'input sequence length not equal to preset sequence length'
# 输入扩展到最大感受野,扩展部分填充0
if self.input_window < self.receptive_field:
inputs = nn.functional.pad(inputs, (self.receptive_field-self.input_window, 0, 0, 0))
x = self.start_conv(inputs) # 将输入张量进行卷积操作,输出特征图的通道数为 residual_channels=32,
skip = self.skip0(F.dropout(inputs, self.dropout, training=self.training))
# 三层卷积
for i in range(self.layers):
residual = x # 记录当前块输入作为残差
filters = self.filter_convs[i](x) # 普通卷积操作
filters = torch.tanh(filters) # 应用tanh激活函数
gate = self.gate_convs[i](x) # 执行门控卷积操作
gate = torch.sigmoid(gate) # 应用sigmoid激活函数,映射到0,1范围,进行门控
x = filters * gate # 使用门控机制进行特征调整---张量积,逐元素相乘,抑制噪声
x = F.dropout(x, self.dropout, training=self.training) # 执行dropout操作
s = x
s = self.skip_convs[i](s) # 跳跃连接中的卷积操作
skip = s + skip # 计算跳跃连接的输出
x = self.residual_convs[i](x) # 执行残差卷积操作
x = x + residual[:, :, :, -x.size(3):] # 添加残差并更新当前块输入
# 跳跃连接 负责多层次关联注入
skip = self.skipE(x) + skip
x = F.relu(skip)
x_emb = x.clone()
x = F.relu(self.end_conv_1(x))
x = self.end_conv_2(x)
return x, x_embSTLlama 前向传播
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
st_data_x: Optional[list] = None,
st_data_y: Optional[list] = None,
region_start: Optional[int] = -1,
region_end: Optional[int] = -1,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPast]:
# HACK: replace back original embeddings for LLaVA pretraining
orig_embeds_params = getattr(self, 'orig_embeds_params', None)
# if orig_embeds_params is not None:
# orig_embeds_params = orig_embeds_params[0]
# with torch.no_grad():
# self.get_input_embeddings().weight.data[:-2] = orig_embeds_params[:-2].data
# 检查是否有传入的嵌入 inputs_embeds,如果没有则通过 embed_tokens 方法将输入的 input_ids 转换成嵌入表示。
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids)
# 检查是否需要将多个 st_data_x 和 st_data_y 进行拼接
if len(st_data_x) > 1:
st_data_x = torch.cat(st_data_x, dim=0)
st_data_y = torch.cat(st_data_y, dim=0)
st_tower = self.get_st_tower()
# 如果 st_tower 不为空,且输入数据的长度不为1或者处于训练模式,同时 st_data_x 也不为空,则进行时空信息的处理。
if st_tower is not None and (input_ids.shape[1] != 1 or self.training) and st_data_x is not None:
if type(st_data_x) is list:
# variable length images
# 将 st_data_x 输入到 st_tower 中,得到时空编码的结果 STE_out,同时将 st_data_y 输入到 st_tower 中得到时空编码标签的结果 STE_lbls_out
pre_STE, STE_out = st_tower(st_data_x[0][..., :2])
_, STE_lbls_out = st_tower(st_data_y[0][..., :2])
if STE_out.shape[2] >= 1:
# 根据指定的 region_start 和 region_end 对 STE_out(时空编码信息) 进行切片得到区域选择输出 region_select_out。
region_select_out = STE_out[:, :, region_start[0]:region_end[0], :].to(torch.bfloat16)
else:
pre_STE, STE_out = st_tower(st_data_x[..., :2])
_, STE_lbls_out = st_tower(st_data_y[..., :2])
region_select_out = STE_out[:, :, region_start[0]:region_end[0], :].to(torch.bfloat16)
self.pre_STE = pre_STE
# ===========将 region_select_out 经过线性层 st_projector 处理得到投影的结果 st_projector_out。==========
st_projector_out = self.st_projector(region_select_out.transpose(1, -1))
new_input_embeds = []
# new_stpre_embeds = []
cur_st_idx = 0
# 遍历输入的 input_ids 和对应的 inputs_embeds。
for cur_input_ids, cur_input_embeds in zip(input_ids, inputs_embeds):
# if st_tower.config.use_st_start_end:
# 根据 st_tower 的配置信息,找到对应的起始标记和结束标记位置,然后根据这些位置和时空特征的投影结果,更新输入嵌入表示。
cur_st_features = st_projector_out[cur_st_idx]
cur_st_features = cur_st_features.reshape(cur_st_features.shape[0], -1)
# 根据时空特征来划分patch
num_patches = cur_st_features.shape[0]
# 判断开始标记和结束标记数量要一致
if (cur_input_ids == st_tower.config.st_start_token).sum() != (
cur_input_ids == st_tower.config.st_end_token).sum():
raise ValueError("The number of st start tokens and st end tokens should be the same.")
st_start_tokens = torch.where(cur_input_ids == st_tower.config.st_start_token)[0]
# st_end_tokens = torch.where(cur_input_ids == st_tower.config.st_end_token)[0]
if st_start_tokens.shape[0] >= 3: # 标记>=3
st_start_token_pos1 = st_start_tokens[0]
st_start_token_pos2 = st_start_tokens[1]
st_start_token_pos3 = st_start_tokens[2]
self.st_start_id0 = st_start_token_pos1
self.st_start_id1 = st_start_token_pos3
if cur_input_ids[
st_start_token_pos1 + num_patches + 1] != st_tower.config.st_end_token:
raise ValueError("The st end token should follow the st start token.")
if orig_embeds_params is not None:
# 根据这些位置和时空特征的投影结果,更新输入嵌入表示(拼接文本embedding张量+时空特征投影结果,只有start到end位置参与梯度更新)
cur_new_input_embeds = torch.cat((cur_input_embeds[:st_start_token_pos1].detach(),
# 时空特征前后拼接原始input embed的start与end位置,start之前和end之后的用detach
# 创建离断版本 将这些元素从计算图中分离出来,使得它们不参与梯度计算,从而防止对它们的修改影响到之后的反向传播过程
cur_input_embeds[st_start_token_pos1:st_start_token_pos1 + 1],
cur_st_features,
cur_input_embeds[
st_start_token_pos1 + num_patches + 1:st_start_token_pos1 + num_patches + 2],
cur_input_embeds[
st_start_token_pos1 + num_patches + 2:st_start_token_pos2].detach(),
cur_input_embeds[
st_start_token_pos2:st_start_token_pos2 + num_patches + 2],
cur_input_embeds[
st_start_token_pos2 + num_patches + 2:st_start_token_pos3].detach(),
cur_input_embeds[
st_start_token_pos3:st_start_token_pos3 + num_patches + 2],
cur_input_embeds[
st_start_token_pos3 + num_patches + 2:].detach()), dim=0)
else:
cur_new_input_embeds = torch.cat((cur_input_embeds[:st_start_token_pos1 + 1],
cur_st_features,
cur_input_embeds[st_start_token_pos1 + num_patches + 1:]),
dim=0)
cur_st_idx += 1
else: # 一组标记,流程和上面一样
st_start_token_pos = st_start_tokens[0]
self.st_start_id0 = st_start_token_pos
num_patches = cur_st_features.shape[0]
if cur_input_ids[st_start_token_pos + num_patches + 1] != st_tower.config.st_end_token:
raise ValueError("The st end token should follow the st start token.")
if orig_embeds_params is not None:
cur_new_input_embeds = torch.cat((cur_input_embeds[:st_start_token_pos].detach(),
cur_input_embeds[st_start_token_pos:st_start_token_pos + 1],
cur_st_features,
cur_input_embeds[
st_start_token_pos + num_patches + 1:st_start_token_pos + num_patches + 2],
cur_input_embeds[
st_start_token_pos + num_patches + 2:].detach()), dim=0)
else:
cur_new_input_embeds = torch.cat((cur_input_embeds[:st_start_token_pos + 1],
cur_st_features,
cur_input_embeds[st_start_token_pos + num_patches + 1:]),
dim=0)
cur_st_idx += 1
new_input_embeds.append(cur_new_input_embeds)
assert cur_st_idx == len(st_projector_out)
# 输入embedding替换为缝合了时空编码信息的embedding
inputs_embeds = torch.stack(new_input_embeds, dim=0)
# 调用llama的前向传播过程,解码输入信息
return super(STLlamaModel, self).forward(
input_ids=None, attention_mask=attention_mask, past_key_values=past_key_values,
inputs_embeds=inputs_embeds, use_cache=use_cache,
# 隐层也要输出,所以有这个参数
output_attentions=output_attentions, output_hidden_states=output_hidden_states,
return_dict=return_dict
)主体模型 前向传播
# 对时空信息的处理,包括时空特征的提取、投影和整合,以及更新输入嵌入表示后的模型正常前向传播过程
# 根据分类和回归损失对STLlama的时空相关部分进行梯度更新
def forward(
self,
input_ids: torch.LongTensor = None, # 输入标记的ID
attention_mask: Optional[torch.Tensor] = None, # 注意力遮罩
past_key_values: Optional[List[torch.FloatTensor]] = None, # 过去的键值
inputs_embeds: Optional[torch.FloatTensor] = None, # 输入的嵌入表示
labels: Optional[torch.LongTensor] = None, # 标签(用于计算损失)
use_cache: Optional[bool] = None, # 是否使用缓存
output_attentions: Optional[bool] = None, # 输出注意力权重
output_hidden_states: Optional[bool] = None, # 输出隐藏状态
st_data_x: Optional[list] = None, # 时序数据
st_data_y: Optional[list] = None, # 时序数据的标签
# x和y要送入STLlama执行时空编码,编码后经过线性层 st_projector 处理得到投影的结果,然后将其与文本嵌入拼接形成新的嵌入,送入大模型
region_start: Optional[int] = -1, # 区域开始位置
region_end: Optional[int] = -1, # 区域结束位置
return_dict: Optional[bool] = None, # 是否返回字典形式的输出
) -> Union[Tuple, CausalLMOutputWithPast]:
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# STllama解码器的输出包括(dec_features, layer_state, dec_hidden, dec_attn)
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
st_data_x=st_data_x,
st_data_y=st_data_y,
region_start=region_start,
region_end=region_end
)
feature_nums = 2
hidden_states = outputs[0] # STllama解码的隐层
batch_size = hidden_states.shape[0]
# =========通过自定义的回归层对hidden_state投影及预测部分做回归预测,然后比较和label之间的误差,
# 同时融合大模型隐层预测的结果logits的误差,综合回归+分类+文本生成误差,更新梯度===========
# 隐层做全连接得到最终st_pre结果
if labels is not None:
# 从 hidden_states 中切片出start-end对应的部分(分别是待预测序列,预测表征序列),并将其转换成训练表征 st_pre_embs1 和 st_pre_embs2。
# 对 st_pre_embs1 和 st_pre_embs2 分别进行线性变换和relu激活函数操作,得到 st_pre_out1 和 st_pre_out2。
st_pre_embs1 = hidden_states[:,
self.model.st_start_id0 + 1:self.model.st_start_id0 + feature_nums + 1,
:].detach().reshape(batch_size, -1, feature_nums, self.config.hidden_size)
# # [4, 1, 2, 4096]-->[4, 1, 2, 128]
st_pre_out1 = self.relu(self.st_pred_linear_1(st_pre_embs1))
st_pre_embs2 = hidden_states[:,
self.model.st_start_id1 + 1:self.model.st_start_id1 + feature_nums + 1,
:].reshape(batch_size, -1, feature_nums, self.config.hidden_size)
# # [4, 1, 2, 4096]-->[4, 1, 2, 128]
st_pre_out2 = self.relu(self.st_pred_linear_3(st_pre_embs2))
# 将 st_pre_out1 和 st_pre_out2 拼接起来,并经过另一个线性变换得到最终结果 st_pre_final。
# # [4, 1, 2, 256]-->[4, 1, 2, 12]
st_pre_final = self.st_pred_linear_2(torch.cat([st_pre_out1, st_pre_out2], dim=-1))
# # [4, 1, 2, 12]-->[4, 1, 12, 2]
st_pre_final = st_pre_final.transpose(-1, -2)
else: # 测试,而非训练
self.st_pre_res.append(hidden_states.clone())
# 线性层,lm_head将隐层特征映射到词表
logits = self.lm_head(hidden_states)
loss = None
if labels is not None: # 训练过程
# Shift so that tokens < n predict n
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss() # fct,交叉熵
rec_loss = scaler_mae_loss(scaler=None, mask_value=None) #MAE
bce_loss = BCEWithLogitsLoss()
shift_logits = shift_logits.view(-1, self.config.vocab_size)
shift_labels = shift_labels.view(-1)
# Enable model/pipeline parallelism
shift_labels = shift_labels.to(shift_logits.device)
# 处理标签
if len(st_data_y) > 1:
st_data_y = torch.cat(st_data_y, dim=0)
labels_stpre = st_data_y[:, :, region_start[0]:region_end[0], :feature_nums].transpose(1, 2).to(
torch.bfloat16)
task_type_all = st_data_y[:, 0, region_start[0], -1]
else:
labels_stpre = st_data_y[0][0:1, :, region_start[0]:region_end[0], :feature_nums].transpose(1, 2).to(
torch.bfloat16)
task_type_all = st_data_y[0][0:1, 0, region_start[0], -1]
regress_idx_list = []
classificate_idx_list = []
regress_result_list = []
classificate_result_list = []
for i in range(batch_size):
task_type = task_type_all[i]
# classification
if task_type == 3 or task_type == 4:
classificate_idx_list.append(i)
regress_result_list.append(st_pre_final[i:i + 1, ...].detach())
classificate_result_list.append(st_pre_final[i:i + 1, ...])
# regression
else:
regress_idx_list.append(i)
classificate_result_list.append(st_pre_final[i:i + 1, ...].detach())
regress_result_list.append(st_pre_final[i:i + 1, ...])
regress_result = torch.cat(regress_result_list, dim=0)
classificate_result = torch.cat(classificate_result_list, dim=0)
# 回归损失--MAE
loss_regress = rec_loss(regress_result, labels_stpre)
labels_classificate = labels_stpre
labels_classificate[labels_classificate >= 1] = 1
labels_classificate[labels_classificate < 1] = 0
# 分类损失bce
loss_classificate = bce_loss(classificate_result, labels_classificate)
# 综合损失
loss = loss_fct(shift_logits, shift_labels) + loss_regress + loss_classificate
if not return_dict:
# print('not return dict')
output = (logits,) + outputs[1:]
print(loss.shape)
return (loss,) + output if loss is not None else output
return CausalLMOutputWithPast(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)评估
@ray.remote(num_gpus=1)
@torch.inference_mode()
def eval_model(args, prompt_file, start_idx, end_idx):
# load prompting file
# prompt_file = load_prompting_file(args.prompting_file)
# Model
disable_torch_init()
# model_name = os.path.expanduser(args.model_name)
print('start loading')
# 加载预训练的tokenizer,用于对输入文本进行编码
tokenizer = AutoTokenizer.from_pretrained(args.model_name)
print('finish loading')
print('start loading')
# 加载预训练的时空语言模型
model = STLlamaForCausalLM.from_pretrained(args.model_name, torch_dtype=torch.bfloat16, use_cache=True,
low_cpu_mem_usage=True).cuda()
# 设置时空依赖编码器
model.set_st_tower()
print('finish loading')
# 根据模型配置,调整tokenizer的词汇表,添加时空相关的特殊标记。
use_st_start_end = getattr(model.config, "use_st_start_end", False)
tokenizer.add_tokens([DEFAULT_ST_PATCH_TOKEN], special_tokens=True)
if use_st_start_end:
tokenizer.add_tokens([DEFAULT_ST_START_TOKEN, DEFAULT_ST_END_TOKEN], special_tokens=True)
st_tower = model.get_model().st_tower
# 配置编码器
st_config = st_tower.config
st_config.st_patch_token = tokenizer.convert_tokens_to_ids([DEFAULT_ST_PATCH_TOKEN])[0]
# 配置中的token使用对应词汇在词表中的id
st_config.use_st_start_end = use_st_start_end
if use_st_start_end:
st_config.st_start_token, st_config.st_end_token = tokenizer.convert_tokens_to_ids(
[DEFAULT_ST_START_TOKEN, DEFAULT_ST_END_TOKEN])
res_data = []
print(f'total: {len(prompt_file)}')
with open(args.st_data_path, 'rb') as file:
st_data_all = pickle.load(file)
error_i = 0
for idx, instruct_item in tqdm(enumerate(prompt_file)):
# 使用load_st加载时空数据,包括时空标记长度、时空数据x和y的编码信息、时空区域的起始和结束位置等
# prompt file对应的instruct item:NYC_taxi.json
# st_data:pkl文件,存储已经训练好的时序编码信息
st_dict = load_st(idx, instruct_item, st_data_all)
st_token_len = st_dict['st_token_len']
st_data_x = st_dict['st_data_x']
st_data_y = st_dict['st_data_y']
region_start = st_dict['region_start']
region_end = st_dict['region_end']
# 自然语言问题从instruct_item中提取
qs = instruct_item["conversations"][0]["value"]
replace_token = DEFAULT_ST_PATCH_TOKEN * st_token_len
replace_token = DEFAULT_ST_START_TOKEN + replace_token + DEFAULT_ST_END_TOKEN
qs = qs.replace(DEFAULT_STHIS_TOKEN, replace_token)
qs = qs.replace(DEFAULT_STPRE_TOKEN, replace_token)
# if "v1" in args.model_name.lower():
# conv_mode = "stchat_v1"
# else:
# raise ValueError('Don\'t support this model')
conv_mode = "stchat_v1"
if args.conv_mode is not None and conv_mode != args.conv_mode:
print('[WARNING] the auto inferred conversation mode is {}, while `--conv-mode` is {}, using {}'.format(
conv_mode, args.conv_mode, args.conv_mode))
else:
args.conv_mode = conv_mode
conv = conv_templates[args.conv_mode].copy()
conv.append_message(conv.roles[0], qs) # 为用户角色添加qs问题
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
# 对prompt编码
inputs = tokenizer([prompt])
# 输入张量
input_ids = torch.as_tensor(inputs.input_ids).cuda()
# 停用词
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
keywords = [stop_str]
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
with torch.inference_mode():
# 大模型解码,生成预测文本tokens的id序列
output_ids = model.generate(
input_ids,
# st_data=st_data_x,
st_data_x=st_data_x.cuda(),
st_data_y=st_data_y.cuda(),
region_start=region_start,
region_end=region_end,
do_sample=True,
# do_sample=False,
# temperature=0.2,
temperature=0.01,
# max_new_tokens=1024,
max_new_tokens=256,
stopping_criteria=[stopping_criteria])
# 找到自定义的special token
start_inx = torch.where(output_ids[0, :] == 32001)[0]
end_inx = torch.where(output_ids[0, :] == 32002)[0]
# 获取隐层状态
hidden_states = model.get_st_pre_res()
hidden_states = torch.cat(hidden_states, dim=1)
model.reset_st_pre_res()
# 将tokens解码为输出结果
batch_size = hidden_states.shape[0]
feature_nums = 2
st_pre_embs1 = hidden_states[:,
model.model.st_start_id0 + 1:model.model.st_start_id0 + feature_nums + 1,
:].detach().reshape(batch_size, -1, feature_nums, model.config.hidden_size)
# 通过一个线性层获取结果
st_pre_out1 = model.relu(model.st_pred_linear_1(st_pre_embs1))
if start_inx.shape[0] == 3:
if hidden_states.shape[1] > start_inx[2] + 1 + feature_nums:
st_pre_embs2 = hidden_states[:, start_inx[2] + 1:start_inx[2] + 1 + feature_nums, :]
else:
print('========error========')
error_i = error_i + 1
print(error_i)
print(hidden_states.shape, start_inx[2] + 1)
st_pre_embs2 = hidden_states[:, -(2+feature_nums):-2, :]
else:
print('========error========')
error_i = error_i + 1
print(error_i)
st_pre_embs2 = hidden_states[:, -(2+feature_nums):-2, :]
st_pre_embs2 = st_pre_embs2.reshape(batch_size, -1, feature_nums, model.config.hidden_size)
st_pre_out2 = model.relu(model.st_pred_linear_3(st_pre_embs2))
st_pre_final = model.st_pred_linear_2(torch.cat([st_pre_out1, st_pre_out2], dim=-1))
st_pre_final = st_pre_final.transpose(-1, -2)
st_pre_infolow = st_pre_final[:, :, :, 0].squeeze().detach().cpu().tolist()
st_pre_outfolow = st_pre_final[:, :, :, 1].squeeze().detach().cpu().tolist()
x_in, y_in = st_data_x[:, :, region_start:region_end, 0].squeeze().tolist(), st_data_y[0, :, region_start:region_end,
0].squeeze().tolist()
x_out, y_out = st_data_x[:, :, region_start:region_end, 1].squeeze().tolist(), st_data_y[0, :, region_start:region_end,
1].squeeze().tolist()
input_token_len = input_ids.shape[1]
n_diff_input_output = (input_ids != output_ids[:, :input_token_len]).sum().item()
if n_diff_input_output > 0:
print(f'[Warning] {n_diff_input_output} output_ids are not the same as the input_ids')
# outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=False)[0]
outputs = outputs.strip()
if outputs.endswith(stop_str):
outputs = outputs[:-len(stop_str)]
outputs = outputs.strip()
res_data.append(
{"id": instruct_item["id"], "res": outputs, "x_in": x_in, "x_out": x_out, "y_in": y_in, "y_out": y_out,
"st_pre_infolow": st_pre_infolow, "st_pre_outfolow": st_pre_outfolow}.copy())
with open(osp.join(args.output_res_path, 'arxiv_test_res_{}_{}.json'.format(start_idx, end_idx)), "w") as fout:
json.dump(res_data, fout, indent=4)
return res_data
# with open(args.output_res_path, "w") as fout:
# json.dump(res_data, fout, indent=4)



