JDBC
概述
- JDBC(Java Database Connectivity)是Java语言中用于与数据库通信的一种API,它允许Java应用程序通过标准的数据库访问方法与各种关系型数据库进行交互,例如MySQL、Oracle、SQL Server等。
- JDBC为访问不同的数据库提供了统一的接口,使开发人员能够编写Java程序以执行SQL查询、更新数据库记录。为使用者屏蔽了细节问题。
本质:
- 官方(sun公司)定义的一套操作所有关系型数据库的规则,即接口
- 各个数据库厂商去实现这套接口,提供数据库驱动jar包。(数据库驱动提供JDBC的实现类)
- 我们可以使用这套接口(JDBC)编程,真正执行的代码是驱动jar包中的实现类。
优点:
- 跨数据库兼容性:各数据库厂商使用相同的接口,Java代码不需要针对不同数据库分别开发。可随时替换底层数据库,访问数据库的Java代码基本不变。
- 安全性:JDBC提供了一种安全的数据库访问机制,可以防止SQL注入等安全问题。通过使用预编译语句和参数化查询等技术,可以有效地防止恶意用户对数据库进行攻击。
基本流程
public class JDBCDemo {
public static void main(String[] args) throws Exception {
//1. 注册驱动
// Class.forName("com.mysql.jdbc.Driver");
//2. 获取连接
String url = "jdbc:mysql://127.0.0.1:3306/db1";
String username = "root";
String password = "1234";
Connection conn = DriverManager.getConnection(url, username, password);
//3. 定义sql
String sql = "update account set money = 2000 where id = 1";
//4. 获取执行sql的对象 Statement
Statement stmt = conn.createStatement();
//5. 执行sql
int count = stmt.executeUpdate(sql);//受影响的行数
//6. 处理结果
System.out.println(count);
//7. 释放资源
stmt.close();
conn.close();
}
}API
DriverManager
DriverManager(驱动管理类)作用:
- 注册驱动

我们使用的注册驱动代码为
Class.forName("com.mysql.jdbc.Driver");这是因为MySQL提供的Driver类源码调用了DriverManager.registerDriver。
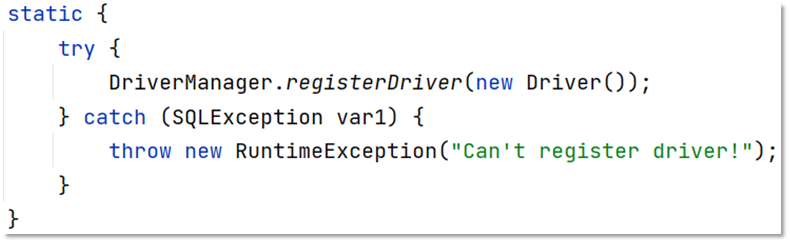
在该类中的静态代码块中已经执行了 DriverManager 对象的 registerDriver() 方法进行驱动的注册了,那么我们只需要加载 Driver 类,该静态代码块就会执行。而Class.forName("com.mysql.jdbc.Driver"); 就可以加载 Driver 类。
==提示:==
- MySQL 5之后的驱动包,可以省略注册驱动的步骤
- 自动加载jar包中META-INF/services/java.sql.Driver文件中的驱动类
Connection
Connection(数据库连接对象)作用:获取执行 SQL 的对象;管理事务
获取执行对象
普通执行SQL对象–statement
//3. 定义sql
String sql = "update account set money = 3000 where id = 1";
//4. 获取执行sql的对象 Statement
Statement stmt = conn.createStatement();
//5. 执行sql
int count = stmt.executeUpdate(sql);预编译SQL的执行SQL对象:防止SQL注入
SQL注入是通过操作输入来修改事先定义好的SQL语句,用以达到执行代码对服务器进行攻击的方法。
例如普通statement如果使用字符串拼接构造SQL
String sql = "select * from stu where name='" + name + "'";在name中传入"lucy" or name="郭麒麟",此时就会改变原有的SQL,查询到两条语句。也就是SQL注入漏洞可以使用
PreparedStatement来实现数据库操作,它的特点是:使用占位符?表示SQL语句中的参数,通过set方法为SQL语句传入参数public static void queryPrepare(String name) throws SQLException { // 预编译SQL,SQL语句中的参数值,使用?占位符替代 ptmt = conn.prepareStatement("select * from stu where name=?"); ptmt.setString(1, name); // 打印预编译后的SQL语句 System.out.println(ptmt.toString()); // 调用这个方法时不需要传递SQL语句,因为获取SQL语句执行对象时已经对SQL语句进行预编译了。 rs = ptmt.executeQuery(); while (rs.next()) { StringBuilder sb = new StringBuilder("[id="); sb.append(rs.getLong("id")); sb.append(", name=" + rs.getString("name")); sb.append(", age=" + rs.getInt("age")); sb.append(", class_id=" + rs.getLong("class_id")); sb.append("]"); System.out.println(sb.toString()); } }
==小结:==
- 在获取PreparedStatement对象时,将sql语句发送给mysql服务器进行检查,编译(这些步骤很耗时)
- 执行时就不用再进行这些步骤了,速度更快
- 如果sql模板一样,则只需要进行一次检查、编译
事务管理
MySQL事务管理的操作:
- 开启事务 : BEGIN; 或者 START TRANSACTION;
- 提交事务 : COMMIT;
- 回滚事务 : ROLLBACK;
Connection接口中定义了3个对应的方法:
try {
// ============开启事务==========
conn.setAutoCommit(false);
//5. 执行sql
int count1 = stmt.executeUpdate(sql1);//受影响的行数
//6. 处理结果
System.out.println(count1);
int i = 3/0;
//5. 执行sql
int count2 = stmt.executeUpdate(sql2);//受影响的行数
//6. 处理结果
System.out.println(count2);
// ============提交事务==========
//程序运行到此处,说明没有出现任何问题,则需求提交事务
conn.commit();
} catch (Exception e) {
// ============回滚事务==========
//程序在出现异常时会执行到这个地方,此时就需要回滚事务
conn.rollback();
e.printStackTrace();
}数据库连接池
简介
数据库连接池是个容器,负责分配、管理数据库连接(Connection)
它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个;
释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏
好处
- 资源重用:在需要时分配和回收资源
- 降低连接的建立和关闭开销,提升系统响应速度
- 限制并发连接数,便于管理和维护,避免数据库连接遗漏
其他八股见Java基础数据库连接池部分
之前我们代码中使用连接是没有使用都创建一个Connection对象,使用完毕就会将其销毁。这样重复创建销毁的过程是特别耗费计算机的性能的及消耗时间的。
而数据库使用了数据库连接池后,就能达到Connection对象的复用,如下图
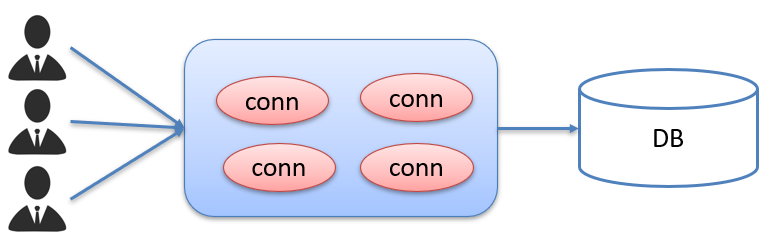
连接池是在一开始就创建好了一些连接(Connection)对象存储起来。用户需要连接数据库时,不需要自己创建连接,而只需要从连接池中获取一个连接进行使用,使用完毕后再将连接对象归还给连接池;这样就可以起到资源重用,也节省了频繁创建连接销毁连接所花费的时间,从而提升了系统响应的速度。
Driud连接池
Druid(德鲁伊)连接池是阿里巴巴开源的数据库连接池项目。使用步骤:
- 导入jar包 druid-1.1.12.jar
- 定义配置文件
- 加载配置文件
- 获取数据库连接池对象
- 获取连接
现在通过代码实现,首先需要先将druid的jar包放到项目下的lib下并添加为库文件
项目结构如下:
编写配置文件如下:
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql:///db1?useSSL=false&useServerPrepStmts=true
username=root
password=1234
# 初始化连接数量
initialSize=5
# 最大连接数
maxActive=10
# 最大等待时间
maxWait=3000使用druid的代码如下:
public class DruidDemo {
public static void main(String[] args) throws Exception {
//3. 加载配置文件
Properties prop = new Properties();
prop.load(new FileInputStream("jdbc-demo/src/druid.properties"));
//4. 获取连接池对象
DataSource dataSource = DruidDataSourceFactory.createDataSource(prop);
//5. 获取数据库连接 Connection
Connection connection = dataSource.getConnection();
System.out.println(connection); //获取到了连接后就可以继续做其他操作了
}
}Hibernate
Java持久层框架是在Java语言中用于与数据库交互的重要工具。它们提供了一种简便的方式来管理数据的持久性。在Java开发过程中,持久层框架可以大大简化数据访问的过程,并且提供了一些额外的功能,如事务管理和缓存机制。
- Hibernate是一个持久层的ORM的框架。允许开发者将Java类和数据库表之间进行映射,使得开发者可以直接操作Java对象,而不用关心底层数据库的细节
- javaBean - config.xml –数据库(三者映射)
- Hibernate 能够自动生成 SQL 语句并自动执行,实现对数据库进行操作,整个过程完全不需要人工干预,大大降低了开发成本。
Hibernate的优点:
- 简化JDBC的编程.
- 修改了实体类,不需要修改源代码.
- 轻量级的框架.
- 支持lazy,可以让你的数据只在需要的时候被加载
- 提供HQL(Hibernate Query Language),可以完全把查询映射到模型
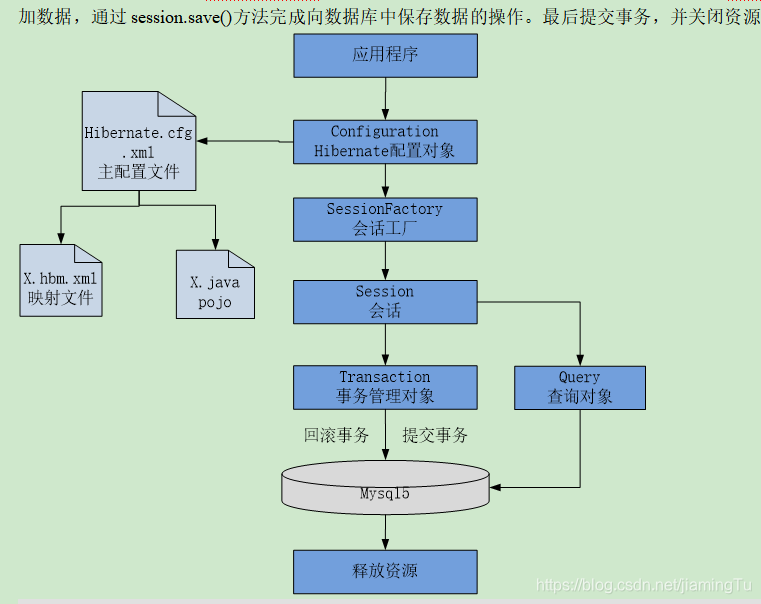
流程说明:首先创建Configuration类的实例,并通过它来读取并解析配置文件hibernate.cfg.xml。然后创建SessionFactory读取解析映射文件信息,并将Configuration对象中的所有配置信息拷贝到SessionFactory内存(一级缓存级别)中。接下来,打开Session,让SessionFactory提供连接,并开启一个事务,之后创建对象,向对象中添加数据,通过session.save()方法完成向数据库中保存数据的操作。最后提交事务,并关闭资源。
缺点:
- 性能问题: 在大规模数据操作和复杂查询时,Hibernate的性能可能不如手动编写的SQL语句高效,需要开发者针对具体情况进行优化。
- 学习成本: 对于初学者来说,学习和掌握Hibernate框架需要一定的时间和精力,尤其是理解ORM的概念和工作原理。
- 对于特定场景的限制:hibernate将数据库与开发者隔离了,开发者不需要关注数据库是Oracle还是MySQL,hibernate来帮你生成查询的sql语句,但在某些特定场景下可能无法满足需求,需要开发者考虑是否需要自定义实现或者选择其他技术。

JPA
JPA,全称是:Java PersistenceAPI。是SUN公司推出的一套基于ORM的规范。hibernate框架中提供了JPA的实现(但是,JPA规范的实现仅仅是Hibernate的一部分)。JPA通过JDK 5.0注解或XML描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。JPA框架中支持大数据集、事务、并发等容器级事务。
Spring Data JPA为Java Persistence API(JPA)提供了实现。它简化了通过JPA访问数据库的开发工作,提供了很多CRUD的快捷操作,还提供了如分页、排序、复杂查询、自定义查询(JPQL)等功能,Spring Data JPA底层也是依赖于Hibernate来实现的,Spring Data JPA拥有标准化、简单易用、面向对象等优势,并且Spring将EntityManager 的创建与销毁、事务管理等代码抽取出来,并由Spring统一进行管理。
JPA搭建
maven依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>springboot配置
spring:
application:
#应用名称
name: spring-data-jpa
datasource:
#你的数据库密码
password: 123456
#你的数据库地址
url: jdbc:mysql://localhost:3306/spring_test?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=true
#数据库用户名
username: root
#数据库驱动名称
driver-class-name: com.mysql.cj.jdbc.Driver #配置MySQL的驱动程序类
#指定连接池类型
type: com.zaxxer.hikari.HikariDataSource
#数据库连接池的配置
hikari:
#客户端等待连接池连接的最大毫秒数
connection-timeout: 30000
……
#连接池的名称
pool-name: SpringDataJPAHikariCP
#jpa相关配置
jpa:
hibernate:
#DDL:用于定义数据库的三层结构,包括外模式、概念模式、内模式及其相互之间的映像,定义数据的完整性,安全控制等约束
ddl-auto: none #什么也不做
#其他可选值
#create: 每次运行应用程序时,都会重新创建表,所以,数据都会丢失
#create-drop:每次运行程序时会创建表结构,然后程序结束时清空数据
#update: 每次运行程序没有表时会创建表,如果对象改变会更新表结构,原有数据不会清除,只会更新
#validate: 运行程序会校验数据与数据库的字段类型是否相同,字段不同会报错
#打印执行的sql及参数
show-sql: true
# 关闭懒加载配置,否则会报错
open-in-view: false
properties:
hibernate:
#输出sql语句
show_sql: true
#格式化输出的sql,否则会一行显示
format_sql: true
server:
#指定服务端口号
port: 8008JPA简单查询
Repository的编写
JPA中,我们只需要定义一个接口就可以轻松地操作数据库,这个接口要继承JpaRepository接口,这里需要指定两个泛型。
public interface BannerRepository extends JpaRepository<Banner, Long> {
}第一个泛型是实体类的类型,第二个泛型是主键的类型。
JPA简单条件查询
JPA要求 我们按照一定的规则进行命名就可以进行一些简单的查询,下面我们开始编写第一个JPA方法。
我们可以定义如下的方法,按照字面上的理解就是,通过查询Banner通过Id,参数是bannerId,也可以通过其他字段来进行查询,IDE会给出提示,我们仅仅需要编写一个这样的方法JPA就会自动的完成查询工作,当前方法中返回的Java8中的Optional对象,也可以直接返回Banner实体类,在一些业务场景下,返回的结果集可能是多个实体对象,这时要用List来进行接收。
public interface BannerRepository extends JpaRepository<Banner, Long> {
/**
* 查询banner 通过bannerId
*
* @param bannerId bannerId
* @return banner 详细信息
*/
Optional<Banner> findBannerById(Long bannerId);
}多条件查询
如果通过多个条件进行查询,如通过名称和描述进行查询,JPA也支持这种查询方式,我们只需要将条件用and进行连接,这里的条件的属性名称与个数要与参数的位置和个数一一对应。
1Banner findBannerByNameAndDescription(String name, String description);JPA几乎实现了MySQL所有的查询关键字,第一个查询是通过Equals关键字来查询名称相同和价格相等的商品,第二个查询是通过GreaterThanEqual关键字来查询名称相同价格大于等于给定价格的商品。
/**
* 查询商品列表通过名称和价格
*/
List<Goods> findByNameAndPriceEquals(String name, BigDecimal price);
/**
* 查询商品列表并且价格大于等于指定的价格
*/
List<Goods> findByNameAndPriceGreaterThanEqual(String name, BigDecimal price);排序与分页
JPA还提供了对排序和分页的支持,只需要在查询方法的入参中加入Sort对象作为入参,就可以实现排序功能,实现分页功能需要将Pageable作为入参就可以实现分页功能。
List<Goods> findAll(Sort sort);
Page<Goods> findAll(Pageable pageable);JPA复杂查询
自定义JPQL
如果JPA规范定义的查询关键字不能满足需求的话,就可以使用@Query自定义查询的JPQL。
第一个自定义简单查询
查询最大id的商品信息,nativeQuery属性表示,是否使用原生SQL,目前使用的JPQL并不是原生的,该属性默认是false,默认可以不写就是使用JPQL查询,这里要注意的是查询使用的表名是实体类,而不是数据表。
/**
* 查询id值最大的商品信息
*/
@Query(value = "SELECT g from Goods g WHERE id = (SELECT max(id) FROM Goods)", nativeQuery = false)
Goods getMaxIdGoods();第二种传递参数的方式:通过参数名来进行传递,通过@Param注解来指定参数名称,在JPQL中使用:参数名的方式。
@Query("SELECT g FROM Goods g WHERE name= :name and price >= :price")
List<Goods> findGoodsBySecondParam(@Param("name") String name, @Param("price") BigDecimal price);JPA原生查询
之前我们使用的自定义查询都是使用JPQL来进行查询,下面将演示使用原生SQL来进行查询,如下查询所有的商品信息,前面已经介绍过,nativeQuery用来标志当前查询是一条原生SQL。
@Query(value = "SELECT * FROM goods", nativeQuery = true)
List<Goods> findAllNativeQuery();那么如果我们想要拿到原生查询的部分结果,那么我们就需要使用Map来进行接收。
@Query(value = "SELECT name, price FROM goods", nativeQuery = true)
List<Map<String, Object>> getGoodsNameAndPriceNativeQuery();参考
黑马程序员JDBC原理+实战:https://www.bilibili.com/video/BV1s3411K7jH/?spm_id_from=333.337.search-card.all.click&vd_source=bf952648bf410c0b9b23bf213e3d24ba
JDBC连接如何防止SQL注入:https://blog.csdn.net/u014454538/article/details/108952103
Java持久层框架整理:https://blog.csdn.net/jiamingTu/article/details/106298092
为什么90%的开发者放弃使用Hibernate,而选择MyBatis:https://www.zhihu.com/question/532452772



